
¿Cuándo usar el módulo Dataflow?
En esta entrada queremos describir cómo el modulo Dataflow de la Onesait Platform puede ayudar a resolver varios escenarios típicos de muchos proyectos.
Pero, ¿en qué consiste este módulo? Pues permite definir de forma gráfica y sencilla flujos de datos, transformaciones de datos, etc. Si os interesa consultar en detalle las capacidades técnicas del módulo, os recomendamos este artículo al respecto de nuestro Portal del Desarrollador.
La idea que tenemos para esta entrada no es ya pretender mostraros ejemplos concretos de los flujos de datos, sino mostrar a más alto nivel las posibilidades que ofrece este módulo.
Procesamiento de datos en streaming
Una de las capacidades más usadas del Dataflow es el procesamiento de datos en streaming. Con este módulo se pueden definir flujos de datos desde la conexión con el origen de dichos datos hasta los posibles destinos de los mismos. Además, permite implementar las transformaciones de datos necesarias.
Veamos un ejemplo para describir en mayor detalle las distintas etapas y posibilidades. En la siguiente figura muestra un ejemplo en el que hay dos fuentes de datos en streaming distintas.
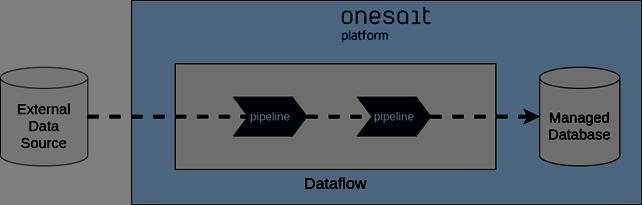
Estas fuentes de datos pueden ser incluso de diferentes tecnologías; por ejemplo, brokers de comunicación tales como Apache Kafka y Google Pub/Sub. También se pueden usar como fuentes de datos orígenes más tradicionales como bases de datos relacionales, bases de datos NoSQL, servidores FTP, etc. La lista de tecnologías soportadas es muy amplia y continúa extendiéndose.
Procesamiento Batch
Otro escenario muy típico en los proyectos son tareas que tienen que realizarse periódicamente sin que ningún usuario tenga que supervisar o activar dichas tareas.
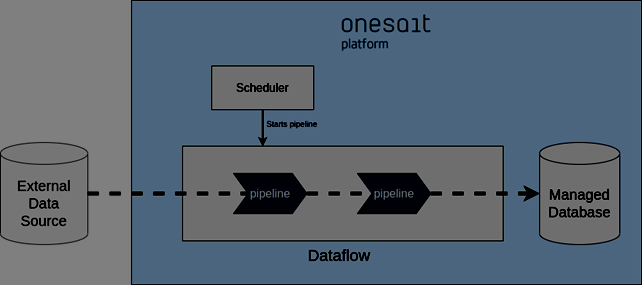
En la figura anterior se muestra un escenario similar al comentado anteriormente. Sin embargo, la diferencia radica en que, en este caso, los conectores no estarán suscritos a las fuentes de datos sino que será un planificador el que lance las tareas de forma programada.
La Onesait Platform permite esta planificación usando el componente Flowengine. En este escenario, el pipeline comenzará cuando el planificador se lo indique. En caso de ser necesario el propio planificador puede pasar parámetros a los pipelines. Una vez se han procesado los datos los pipelines se pararán hasta que el planificador decida lanzar una nueva ejecución.
Replicación de datos entre entornos
Muchos proyectos tienen la necesidad de contar con copias de los datos de producción en entornos de pruebas o preprodución. Con el Dataflow se puede cumplir con esta necesidad. Hay varias formas de hacer esta replicación de datos con el Dataflow. En la siguiente figura se muestra un escenario en el que el Dataflow de uno de los entornos exporta a otro entorno directamente.
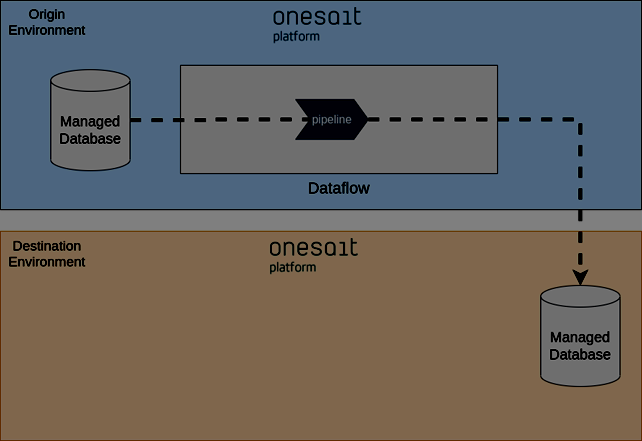
Otras posibilidades serían que el Dataflow del destino leyese los datos desde el origen, o incluso se podría contar con un broker o repositorio intermedio. Dependiendo de la conectividad que exista entre los entornos se deberán usar unas variantes u otras. Normalmente las limitaciones de conectividad vienen determinadas por los requisitos de seguridad.
Integración de sistemas
En otros proyectos, la integración entre distintos sistemas se hace a nivel de datos. En estos casos se puede usar el Dataflow para obtener los datos de sistemas externos y tenerlos disponibles en los nuevos desarrollos que se hagan sobre la Plataforma. Lo mismo sucede al contrario: Hay clientes que cuentan con herramientas u otros sistemas que necesitarán almacenar datos localmente y hay que suministrárselos.

En la figura previa se muestra un ejemplo en el que se cuenta con dos instancias del módulo Dataflow, una de ellas dedicada a la adquisición de datos desde fuentes externas y otra dedicada a proporcionar datos a sistemas externos. Tener instancias dedicadas de Dataflow facilita la gestión de los pipelines cuando su número empieza a crecer.
Centralización de datos
En muchos casos, la Onesait Platform se usa para centralizar datos de diversos sistemas. Un claro ejemplo son los proyectos de tipo «Data Lake». En este caso, se definirá un pipeline por cada fuente de datos.
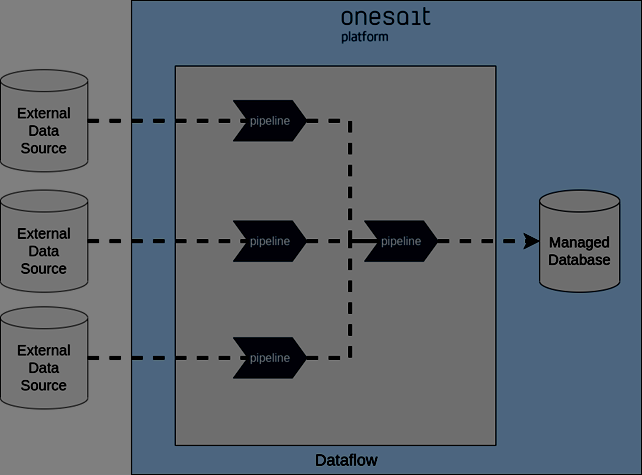
Gracias a la flexibilidad del Dataflow se podrán contar con multitud de tecnologías como origen de datos, además de poder añadir nuevos orígenes sin tener que desplegar nuevo software, ya que los pipelines del Dataflow se definen de forma dinámica.
Conclusiones
Hemos visto algunos de los casos típicos que pueden implementarse con el Dataflow. Hay muchos más casos que se pueden resolver con este módulo, ya que si por algo destaca es por su flexibilidad.
Esperamos que os haya parecido interesante, y si os surge alguna duda dejadnos un comentario.


