
¿Qué tecnología Open Source recomendamos para reemplazar Hadoop?
Hadoop es una plataforma de almacenamiento de datos muy escalable que se utiliza como base para muchos proyectos y productos Big Data. En la década de los 2000, Hadoop se había estandarizado como solución para la creación de Data Lakes ya que permitía construir clústeres locales con hardware básico para almacenar y procesar estos nuevos datos de forma barata.
Hasta hace no mucho, montar un Data Lake sobre Hadoop era una opción muy usada por lo siguientes motivos:
- Mayor familiaridad entre el equipo técnico.
- Solución Open Source, que hace que su implantación sea económica.
- Muchas herramientas disponibles para la integración con Hadoop.
- Fácil de escalar.
- La localidad de los datos permite una computación más rápida.
- Posibilidad de montarlo On Premise o como servicio en las diversas Clouds.
Pero el mundo Open Source ha seguido evolucionando y en la actualidad con Hadoop es muy difícil conseguir la elasticidad, simplicidad y agilidad en el provisionamiento que otras soluciones basadas en Kubernetes si ofrecen. Además, la curva de aprendizaje es compleja y tiene sus complicaciones, así que la pregunta que hay que hacerse es, ¿tenemos alternativas a Hadoop?
Si sois seguidores de nuestro blog, seguro que conocéis la respuesta.
Hadoop, Hadoop, HADOOP
Antes de nada, pongámonos en situación. Hasta hace no mucho cuando surgía la necesidad de montar un Data Lake, siempre nos venía a la mente el mismo nombre: Hadoop.

Si nos fijamos en la historia, en la década de los 2000 como decíamos se hizo masivamente popular, entre otras cosas porque coincidió con la moda de las grandes empresas de apostar por el código abierto, así que los primeros proyectos de Big Data se basaron en esta plataforma.
Pero su valor no era únicamente que fuese Open Source, sino que Hadoop ofrecía dos capacidades principales que le aportaban valor:
- Un sistema de archivos distribuidos (HDFS) para persistir los datos.
- Un marco de procesamiento que permitía procesar todos los datos en paralelo.
Cada vez más, las organizaciones y empresas comenzaron a querer trabajar con todos sus datos, y no sólo con algunos. Y como resultado de ello, Hadoop se hizo popular por su capacidad para almacenar y procesar nuevas fuentes de datos, incluidos los registros de logs, los flujos de clics y los datos generados por sensores y máquinas (algo que para nosotros a día de hoy es «lo normal»).
Hadoop tenía por tanto mucho sentido, ya que permitía construir clústeres locales con hardware básico para almacenar y procesar estos nuevos datos de forma barata. Sin embargo, el Open Source siguió evolucionando y surgió un nuevo marco: Apache Spark, el cual estaba optimizado para trabajar con datos en memoria y no en disco. Y esto, por supuesto, significa que los algoritmos que se ejecutan en Spark son más rápidos.
Ahora bien, seguía siendo necesario persistir los datos de alguna forma, por lo que Spark se solía incluir en muchas distribuciones de Hadoop, sacando lo mejor de cada parte, pero teniendo que coexistir.
Algo pasa con Hadoop
Tras el ascenso, la caída. Uno de los principales motivos que se esgrimen es que con la compra de Hortonworks por Cloudera (y la de MapR por HP) en esencia podemos decir que ya no existen distribuciones gratuitas de Hadoop, lo que hace que se estén buscando soluciones alternativas.
Está claro que no es el único motivo, y es que con Hadoop es muy difícil conseguir la elasticidad, simplicidad y agilidad en el provisionamiento que otras soluciones basadas en Kubernetes si ofrecen, como ya hemos en la introducción.
Entonces cabe preguntarnos, ¿es posible montar un potente Data Lake sin hacer uso de Hadoop? Por supuesto.
Introducing MinIO & Presto
Si recordáis, en su día hablamos por el blog sobre qué era un Data Lake, sus diferencias con un Warehouse, y el uso de Hadoop como Data Lake. Aquí en concreto nos centramos en mostrar una alternativa muy actual: el uso de MinIO y Presto como Data Lake.
Primer ingrediente: MinIO
MinIO, resumiendo, es un almacenamiento distribuido que implementa la API de AWS S3. Puede desplegarse en modo On-Premise y funciona sobre Kubernetes. En la actualidad, es una alternativa interesante a los entornos basados en HDFS y al resto del ecosistema Hadoop.
La principal diferencia entre MinIO y HDFS es que MinIO es una Object Storage mientras que HDFS es un File Storage basado en Block Storage:

El Object Storage basa su almacenamiento en objetos, donde cada objeto se compone de tres elementos:
- Los datos propiamente dichos. Los datos pueden ser cualquier cosa que se quiera almacenar, desde una foto familiar hasta un manual de 400.000 páginas para construir un cohete.
- Una cantidad ampliable de metadatos. Los metadatos son definidos por quien crea el objeto; contienen información contextual sobre lo que son los datos, para qué deben usarse, su confidencialidad, o cualquier otra cosa que sea relevante para la forma en que deben usarse los datos.
- Un identificador único global. El identificador es una dirección que se da al objeto, para que pueda ser encontrado en un sistema distribuido. De este modo, es posible encontrar los datos sin tener que conocer su ubicación física (que podría existir en diferentes partes de un centro de datos o en diferentes partes del mundo).
Este almacenamiento en objetos es relevante porque guarda los datos en un «objeto» en lugar de en un bloque para formar un archivo. Los metadatos se asocian a ese archivo, lo que elimina la necesidad de la estructura jerárquica utilizada en el almacenamiento de archivos: no hay límite a la cantidad de metadatos que se pueden utilizar. Todo se coloca en un espacio de direcciones plano, que es fácilmente escalable.
Esencialmente, el almacenamiento de objetos funciona muy bien para los grandes contenidos y alto throughput, permite que los datos se almacenen en varias regiones, se escalan infinitamente hasta los petabytes y más allá, y ofrece metadatos personalizables para ayudar a recuperar los archivos.
Segundo ingrediente: Presto
Hemos visto que MinIO puede sustituir a HDFS como almacenamiento en nuestro Data Lake, pero aún nos falta un motor de consultas SQL al estilo del eterno HIVE, que es lo que se usaba con Hadoop.
Aquí la opción es utilizar Presto, un motor de consultas SQL distribuido Open Source y construido en Java, el cual está pensado para lanzar consultas analíticas interactivas contra un gran número de fuentes de datos (a través de conectores) soportando consultas sobre fuentes de datos que van desde gigabytes hasta petabytes.
Al ser un motor de consulta ANSI-SQL, permite consultar y manipular datos en cualquier fuente de datos conectada con las mismas sentencias, funciones y operadores SQL.
Esto implica que podemos consultar numerosas fuentes de datos, como los datos almacenados en MinIO, de modo que en lugar de montar HIVE para consultar en formato SQL los datos almacenados en HDFS usaremos Presto para consultar los datos almacenados en MinIO. ¿Y lo mejor de todo? Que podemos consultar otras fuentes de datos de forma directa, inclusive HDFS.
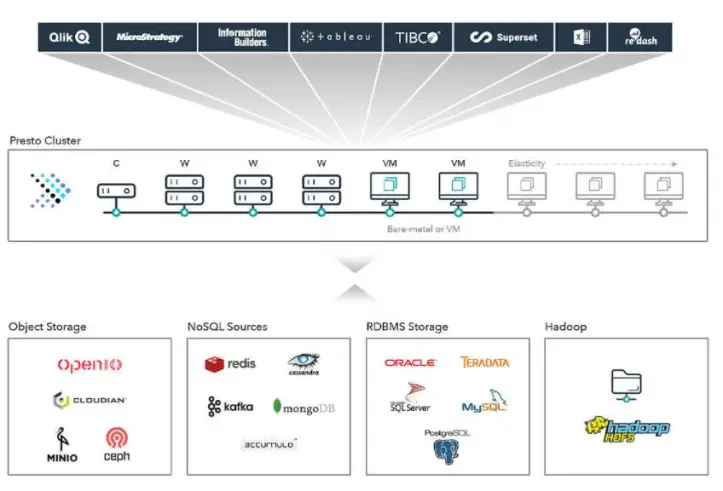
Además Presto puede ejecutar sobre Spark, lo que permite aprovechar Spark como entorno de ejecución para las consultas de Presto.
Ventajas de este combo
Bueno, hemos vendido las bondades de MinIO y Presto; ahora nos queda conocer qué ventajas nos aporta. Pues bien, esta aproximación tiene numerosas ventajas sobre el montaje de un Data Lake sobre Hadoop:
- La combinación es más elástica que la típica configuración Hadoop: mientras que en Hadoop añadir y quitar nodos a un clúster Hadoop es un proceso completo, en esta aproximación todo ejecuta sobre Kubernetes, lo que nos permite escalar de forma sencilla.
- Computación y almacenamiento independientes: con Hadoop si se quiere añadir más almacenamiento, se hace añadiendo más nodos (con computación). Si necesitas más almacenamiento, vas a tener más cómputo, lo necesites o no mientras que con la arquitectura de almacenamiento de objetos si necesitas más computación, puedes añadir nodos al clúster Presto y mantener el almacenamiento, de modo que la computación y el almacenamiento no son sólo elásticos, son elásticos de forma independiente.
- Mantenimiento: mantener un clúster Hadoop estable y fiable es una labor compleja, por ejemplo la actualización de un clúster suele implicar la parada del clúster, las actualizaciones continuas son complejas, …
- Reducción de costes: con esta arquitectura tendremos una reducción del coste total de la propiedad: ya que MinIO apenas requiere gestión, y además el almacenamiento de objetos es más barato.
Tiene buena pinta, ¿verdad? A nosotros nos tiene bastante convencidos, y esperamos que con lo aquí mostrado os animéis también a probarlo, que es cuando realmente se ve si algo funciona de verdad.
Caso práctico: la Onesait Platform
Seguro que no os sorprende si os decimos que la Onesait Platform permite generar entidades sobre una base de datos histórica soportada por MinIO + Presto, en donde los datos de estas entidades se almacenan en ficheros en MinIO, que se pueden consultar mediante el motor de consultas distribuidas en Presto.
Para ver cómo funciona todo esto, vamos a llegar a cabo un ejemplo práctico desde el entorno de experimentación de CloudLab que tenemos subido a la nube.
Para crear este tipo de entidades, navegaremos al menú de Development > My Entities.
Una vez aquí, visualizaremos un listado con las distintas entidades existentes. Para crear una nueva, pulsaremos en el botón de «+» situado en la parte superior derecha de la pantalla.

Esto nos llevará a la pantalla de creación de los distintos tipos de entidades. Aquí seleccionaremos la opción de «Create Entity in Historical Database».
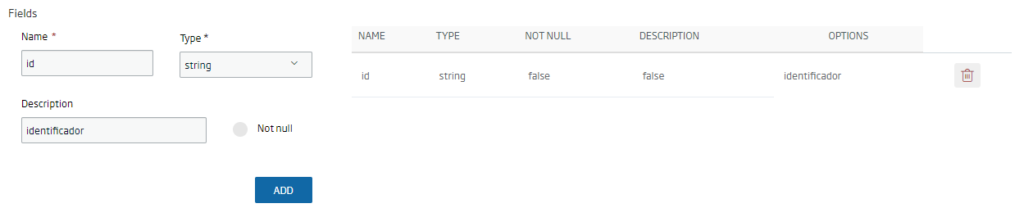
Se nos abrirá entonces el asistente de creación de la entidad sobre la base de datos histórica. Como en el caso de las otras entidades, tenemos que rellenar los campos obligatorios (nombre, metainformación, descripción), y añadir uno a uno los campos que deseamos que contenga nuestra entidad:
A continuación, seleccionaremos el formato del fichero en el que queremos que se guarden los datos en la entidad o del fichero que vayamos a subir.
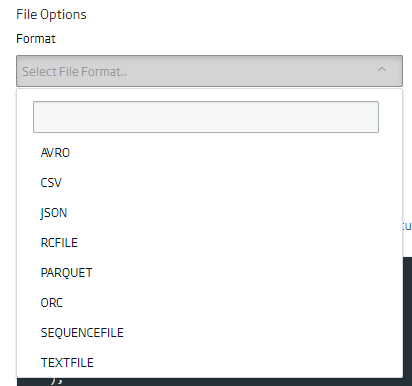
Por defecto los datos se almacenarán en formato ORC, por lo que si no se selecciona ninguno se usará este.
Así mismo, si lo que queremos es almacenamiento en CSV, se deberán indicar los caracteres de escapado, entrecomillado y separador; si no se indican se cogerán los valores por defecto. Esto es muy importante a la hora de subir un fichero para que los datos sean legibles por el motor, así que es interesante dedicarle un poco de tiempo para asegurarnos de que todo está correcto.

También se dispone de la opción de particionar los datos seleccionando uno o varios campos de la entidad que queremos crear. Éstos deben ser los últimos campos en la consulta de creación y estar en el mismo orden:

Una vez que hayamos completado los datos que apliquen a la entidad a crear, se debe pulsar sobre el botón «Update SQL» para generar la consulta de creación de la tabla:
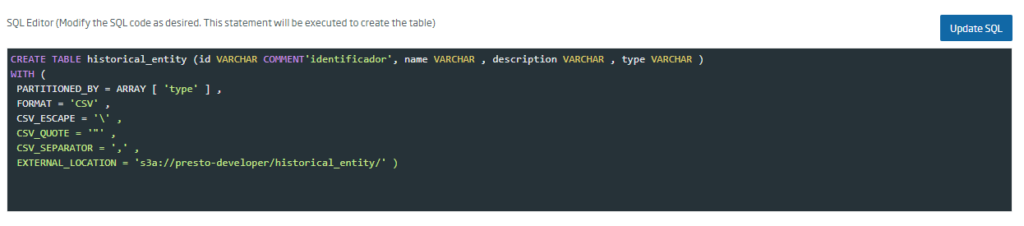
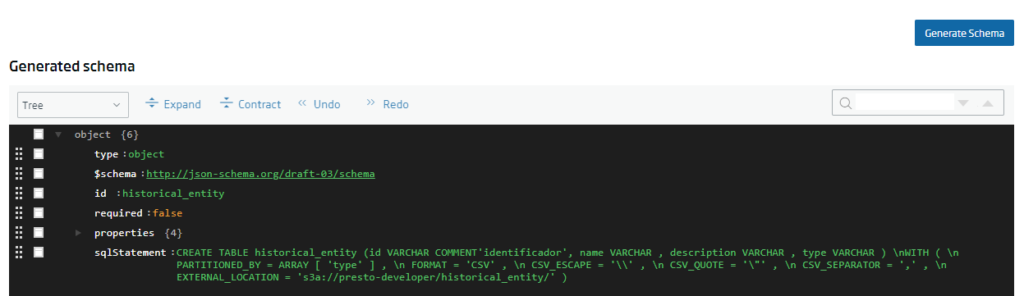
Después de esto, se debe generar el esquema JSON que permitirá crear la entidad en plataforma, pulsando sobre el botón «Generate Schema»:
Al pulsar sobre el botón «Crear», si la entidad se ha generado correctamente aparecerá un popup que nos permitirá subir un archivo a la base de datos:
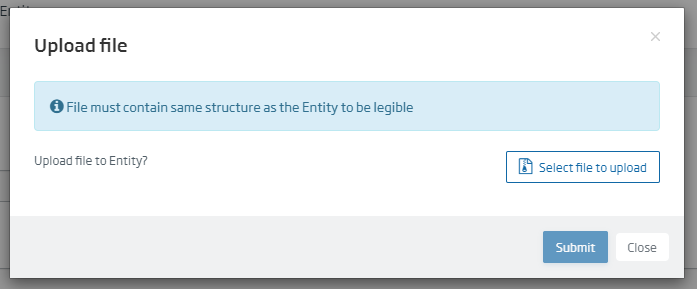
Esta opción también está disponible en la edición de la entidad, mediante el botón «Upload file to Entity». Si se accede a la herramienta «Query tool» mediante la opción del menú Herramientas > Query Tool:
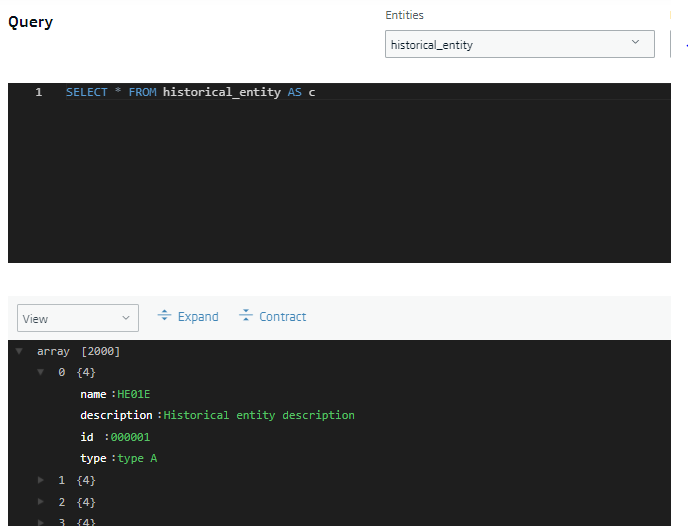
Los datos del fichero los podremos consultar mediante una consulta:
Espero que os haya parecido interesante la entrada, y cualquier duda que os surja dejadnos un comentario al respecto. Y recordad, de Hadoop también se sale.


