
What Open Source technology do we recommend to replace Hadoop?
Hadoop is a highly scalable data warehouse platform that is used as the foundation for many Big Data projects and products. In the 2000s, Hadoop had been standardized as a solution for the creation of Data Lakes, since it allows building local clusters with basic hardware to store and process this new data cheaply.
Until not long ago, setting up a Data Lake on Hadoop was a widely used option for the following reasons:
- Greater familiarity among the technical team.
- Open Source solution, which makes its implementation economical.
- Many tools available for integration with Hadoop.
- Easily scalable.
- Locality of data allows for faster computation.
- Possibility of building it on-premise, or as a service in the different Clouds.
But the Open Source world has continued to evolve, and today, with Hadoop it is very difficult to achieve the elasticity, simplicity and agility in provisioning that other Kubernetes-based solutions offer. Besides, the learning curve is complex and has its complications, so the question to ask is, do we have alternatives to Hadoop?
If you are followers of our blog, surely you know the answer.
Hadoop, Hadoop, HADOOP
First of all, let’s get down to business. Until not long ago, when the need arose to set up a Data Lake, the same name always came to mind: Hadoop.

If we look at history, back in the 2000s, as we were saying, it became massively popular, among other things because it coincided with the trend of large companies betting on open source, so the first Big Data projects were based on this platform.
Yet its value was not only that it was Open Source, but also that Hadoop offered two main capabilities that added value:
- A distributed file system (HDFS) to persist data.
- A processing framework that allowed all data to be processed in parallel.
Increasingly, organizations and companies began to want to work with all of their data, instead of not just some of it – and as a result, Hadoop became popular for its ability to store and process new data sources, including log records, clickstreams, and sensor and machine-generated data (which, by today, is «the usual» for us).
Hadoop therefore made a lot of sense, as it allowed local clusters to be built with basic hardware to store and process this new data cheaply. However, Open Source continued to evolve and a new framework emerged: Apache Spark, which was optimized to work with data in memory and not on disk. And this of course means that the algorithms running on Spark are faster.
Now then, data still needed to be persisted in some way, so Spark used to be included in many Hadoop distributions, making the best of each part, but having to co-exist.
There’s something about Hadoop
After the rise, the fall. One of the main reasons given is that, when Cloudera purchased Hortonworks (and HP purchased MapR), we can essentially say that there are no longer free distributions of Hadoop, which means it’s time to look for alternative solutions.
Clearly, this was not the only reason, and that’s because with Hadoop it is very difficult to achieve the elasticity, simplicity and agility in provisioning that other Kubernetes-based solutions do offer, as we have already mentioned in the introduction.
So we must ask ourselves, is it possible to set up a powerful Data Lake without using Hadoop? Of course.
Introducing MinIO & Presto
If you remember, back in the day we talked on the blog about what a Data Lake was, its differences with a Warehouse, and the use of Hadoop as a Data Lake. Here in particular we focus on showing a very current alternative: the use of MinIO and Presto as Data Lake.
First ingredient:MinIO
MinIO, in short, is a distributed storage that implements the AWS S3 API. It can be deployed either on premise, and it works on top of Kubernetes. Today, it is an interesting alternative to HDFS-based environments and to the rest of the Hadoop ecosystem.
The main difference between MinIO and HDFS is that MinIO is an Object Storage while HDFS is a File Storage based on Block Storage:

Object Storage bases its storage on objects, where each object is made up of three elements:
- The data itself. The data can be anything you want to store, from a family photo to a 400,000-page manual for building a rocket.
- An expandable amount of metadata. The metadata are defined by whoever creates the object; they contain contextual information about what the data is, what it should be used for, its confidentiality, or anything else that is relevant to how the data should be used.
- A globally unique identifier. The identifier is an address given to the object, so that it can be found in a distributed system. This way, you can find the data without having to know its physical location (which could exist in different parts of a data center or in different parts of the world).
This object storage is relevant because it stores the data in an «object» rather than in a block to form a file. The metadata is associated with that file, which eliminates the need for the hierarchical structure used in file storage: there is no limit to the amount of metadata that can be used. Everything is placed in a flat address space, which is easily scalable.
Essentially, object storage works great for large content and high throughput, it allows data to be stored in multiple regions, scales infinitely to petabytes and beyond, and offers customizable metadata to help recover files.
Second ingredient: Presto
We have seen that MinIO can replace HDFS as storage in our Data Lake, but we still lack an SQL query engine in the style of the eternal HIVE, which is what was used with Hadoop.
Here the alternative is to use Presto, an Open Source distributed SQL query engine built in Java, which is designed to launch interactive analytical queries against a large number of data sources (through connectors), supporting queries on data sources that go from gigabytes to petabytes.
Being an ANSI-SQL query engine, it allows you to query and manipulate data in any connected data source with the same SQL statements, functions, and operators.
This means that we can query numerous data sources, such as the data stored in the MinIO, so instead of mounting HIVE to query the data stored in HDFS in SQL format, we will use Presto to query the data stored in the MinIO. The best of all? We can query other data sources directly, even HDFS.
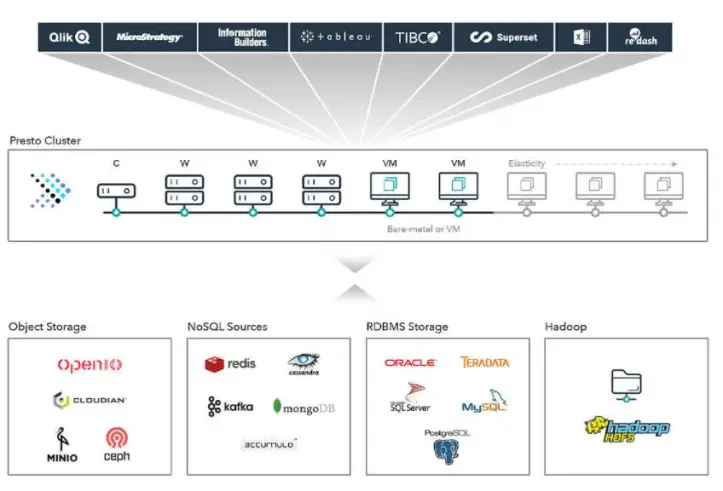
Besides, Presto can run on top of Spark, which allows you to take advantage of Spark as the execution environment for Presto queries.
Advantages of this combo
Well, we have sold you the benefits of MinIO and Presto. Now we have to know what advantages it brings us. Well then, this approach has numerous advantages over setting up a Data Lake on Hadoop:
- The combination is more elastic than the typical Hadoop setup: in Hadoop, adding and removing nodes to a Hadoop cluster is a whole process, while in this approach, everything runs on top of Kubernetes, allowing us to easily scale.
- Independent computation and storage: with Hadoop, if you want to add more storage, you need to add more nodes (with computation). If you need more storage, you end up having more computation, whether you need it or not – whereas, with object storage architecture, if you need more computation you can add nodes to the Presto cluster and keep the storage so compute and storage are not only elastic, they are independently elastic.
- Maintenance: maintaining a stable and reliable Hadoop cluster is a complex task. For example, updating a cluster usually involves stopping the cluster, continuous updates are complex, etc.
- Cost reduction: with this architecture, we will have a reduction in the total cost of ownership, since MinIO hardly requires any management, and also object storage is cheaper.
Looks good, right? It convinced us quite some, and we hope that, with what is shown here, you will also be encouraged to try it. That will be when you really see if something really works.
Case study: the Onesait Platform
Surely you will not be surprised if we tell you that the Onesait Platform allows you to generate entities on a historical database supported by MinIO + Presto, where the data of these entities are stored in files in MinIO, which can be queried through the query engine distributed in Presto.
To see how all this works, we are going to carry out a practical example from the CloudLab experimentation environment that we have uploaded to the cloud.
To create this type of entities, we will navigate to the Development > My Entities menu.
Once here, we will see a list with the different existing entities. To create a new one, we will click on the «+» button located at the top right of the screen.

This will take us to the screen to create the different types of entities. Here, we will select the «Create Entity in Historical Database» option.
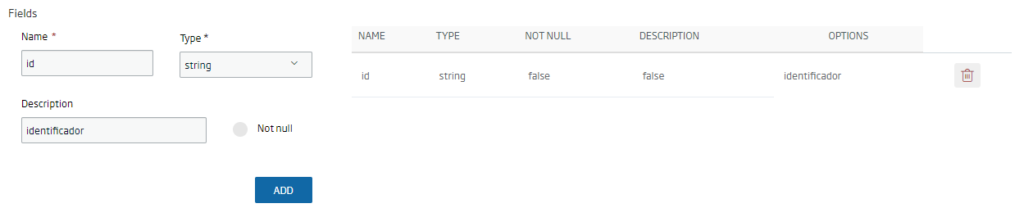
The wizard for creating the entity based on the historical database will then open. As in the case of the other entities, we have to fill in the mandatory fields (name, meta-information, description), and add, one by one, the fields that we want our entity to contain:
Next, we will select the format of the file in which we want the data to be saved in the entity, or of the file that we are going to upload.
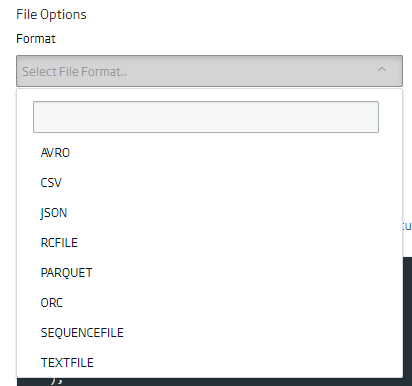
By default the data will be stored in ORC format, so, if we don’t select anything, this will be used.
Likewise, if what we want is storage in CSV, then the escape, quote and separator characters must be specified. If these are not specified, then the default values will be taken. This is very important when uploading a file so that the data is readable by the engine, so it is interesting to spend a little time to make sure that everything is correct.

There is also the option of partitioning the data by selecting one or more fields of the entity that we want to create. These must be the last fields in the create query, and they must be in the same order:campos en la consulta de creación y estar en el mismo orden:

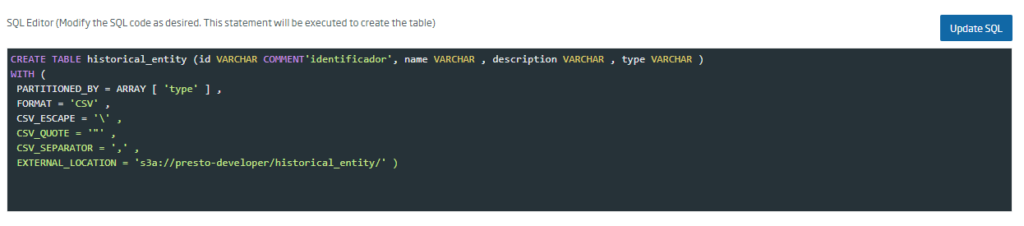
Once we have completed the data that applies to the entity to be created, we must click on the «Update SQL» button to generate the table creation query:
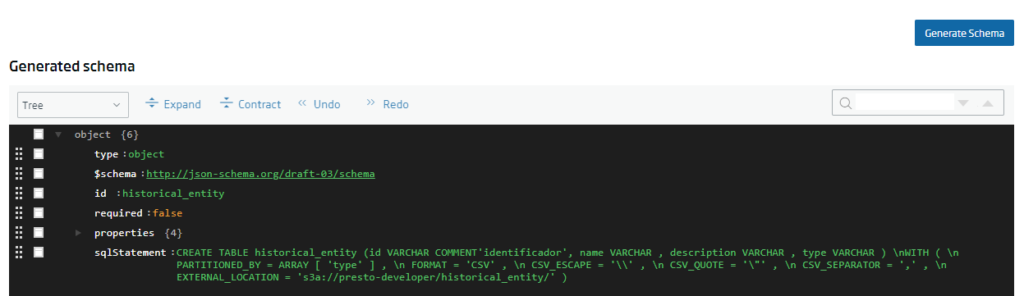
After this, the JSON schema that will allow the entity to be created on the platform must be generated, by clicking on the «Generate Schema» button:
When clicking on the «Create» button, if the entity has been generated correctly, a pop-up will appear that will allow us to upload a file to the database:
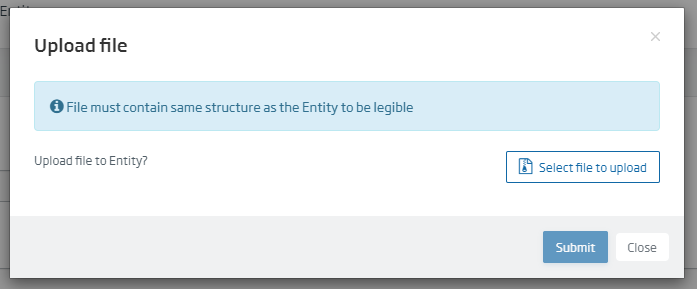
This option is also available when editing the entity through the «Upload file to Entity» button. If you access the «Query tool» through the menu option Tools > Query Tool:
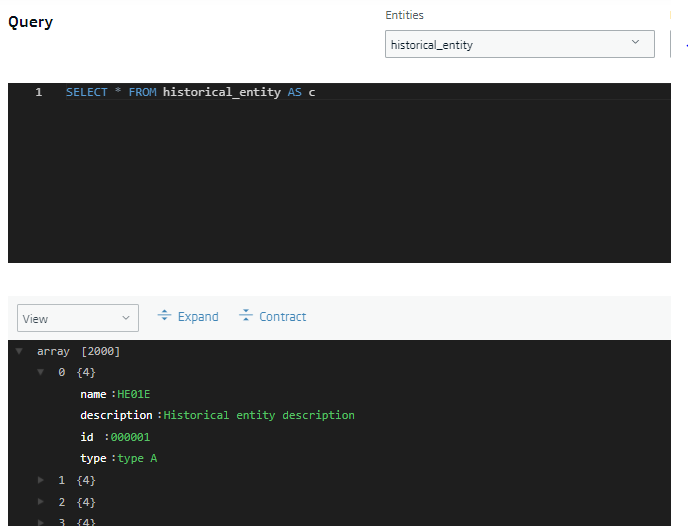
You can obtain the data of the file through a query:
I hope you found the post interesting, and if you have any questions, leave us a comment about that. And remember, you can stop using Hadoop.


