
When to use the Dataflow module?
In this article, we aim to describe how the Onesait Platform’s Dataflow module can help to solve several scenarios that are common in many projects.
But what is this module about? Well, it allows you to graphically and easily define data flows, data transformations, etc. If you are interested in consulting in detail the technical capabilities of the module, we recommend this article about that on our Developer’s Portal.
The idea behind this article is not only to show you specific examples of data flows, but rather to demonstrate at a higher level the possibilities that this module offers.
Processing of streaming data
One of Dataflow’s most used capacities is the processing of streaming data. With this module, data flows can be defined from the connection with the data source, to the possible destinations of the data. It also allows the implementation of the necessary data transformations.
Let’s see an example to describe the various stages and possibilities in greater detail. The following figure shows an example with two different streaming data sources.
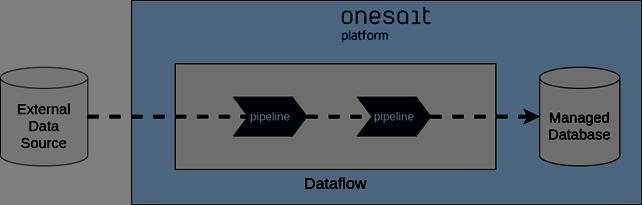
These data sources can even be from different technologies; for example, communication brokers such as Apache Kafka and Google Pub/Sub. More traditional sources such as relational databases, NoSQL databases, FTP servers, etc., can also be used as data sources. The list of supported technologies is very long and constantly expanding.
Batch Processing
Another very usual scenario in projects is tasks that have to be carried out periodically without any user supervising or activating them.
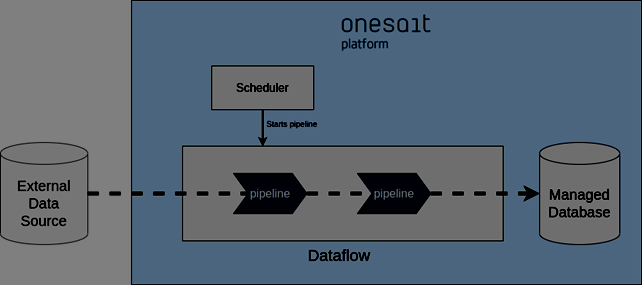
The figure above shows a similar scenario to the one we just discussed. Nevertheless, the difference is that, in this case, the connectors will not be subscribed to the data sources but instead a planner will launch the tasks in a programmed way.
The Onesait Platform allows this planning using the Flowengine component. In this scenario, the pipeline will start when the planner says so. If necessary, the planner itself can pass parameters to the pipelines. Once the data has been processed, the pipelines will stop until the planner decides to start a new run.
Data replication between environments
Many projects require to have copies of production data in test or pre-production environments. This need can be met with Dataflow. There are several ways to do this data replication with Dataflow. The following figure shows a scenario in which the dataflow from one of the environments exports directly to another environment.
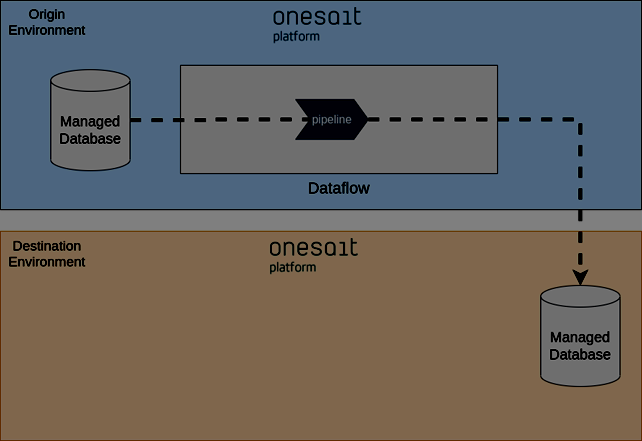
Other possibilities would be for the destination’s Dataflow to read the data from the source, or there could even be an intermediate broker or repository. Depending on the connectivity existing between the environments, the variants that should be used. Normally the connectivity limitations are determined by security requirements.
System integration
In other projects, integration between different systems is done at the data level. In these cases, Dataflow can be used to obtain data from external systems and make them available for new developments made on the Platform. The same happens on the opposite case: Some clients have tools or other systems that will need to store data locally and these must be supplied.

The previous figure shows an example in which there are two instances of the Dataflow module, one of them dedicated to data acquisition from external sources and the other dedicated to providing data to external systems. Having dedicated Dataflow instances facilitates the management of pipelines when their number starts to grow.
Data centralisation
In many cases, the Onesait Platform is used to centralize data from different systems. A clear example is the Data Lake-type projects. In this case, a pipeline is defined for each data source.
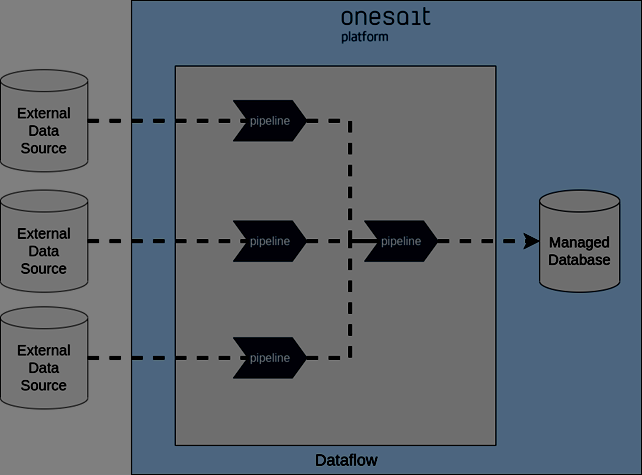
Thanks to the flexibility of the Dataflow, a multitude of technologies can be used as a data source, and we can also add new sources without having to deploy new software, because the Dataflow pipelines are defined dynamically.
Conclusions
We have seen some of the common cases that can be implemented with the Dataflow. There are many more cases that can be solved with this module, because it is nothing if it is not flexible.
We hope you found this interesting, and if you have any question, please leave us a comment.


