
Conectando con Google BigQuery: Agentes JDBC
En muchas ocasiones, nuestro objetivo de negocio se basa en el acceso y operación sobre mucha información que reside en diferentes bases de datos. En la Onesait Platform, gracias al concepto de ontología, podemos tener una abstracción sobre las mismas, de modo que podemos trabajar con estos datos directamente e independientemente de la implementación que tengan. Para nosotros, será una ontología más, con todas sus capacidades.
En el plano técnico, tenemos diversos conectores sobre múltiples bases de datos, tales como MongoDB, Kudu, Impala/Hive, MySQL, Oracle, SQLServer, PostgreSQL, etc., que proporciona la Plataforma sin necesidad de hacer nada.
Algunos de ellos, se pueden usar de forma directa desde las opciones avanzadas de creación de ontologías paso a paso:
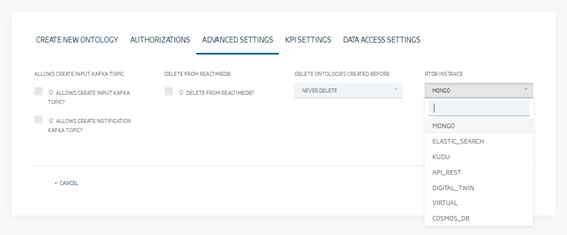
Otros sin embargo, funcionan como conexiones JDBC a una base de datos, permitiendo inferir ontologías desde tablas existentes o creando nuevas tablas con las denominadas ontologías sobre bases de datos relacionales.
En este segundo tipo, puede ocurrir que tengamos que acceder a una nueva base de datos vía JDBC y que no sea ninguna de las anteriores o sea alguna versión incompatible de las mismas, con los drivers proporcionados por la Plataforma. En estos casos, se nos podría ocurrir incluir estos nuevos drivers, de modo que acabaríamos teniendo infinitos drivers con los posibles problemas que podrían generar, conflictos entre los mismos, tamaño en disco, etc.
Es por eso que en la Plataforma se implementó un conector universal para este tipo de casuísticas, de modo que podemos desacoplar el driver de la base de datos e incluso escalarlo independientemente si es necesario, con los agentes JDBC de Calcite Avatica.
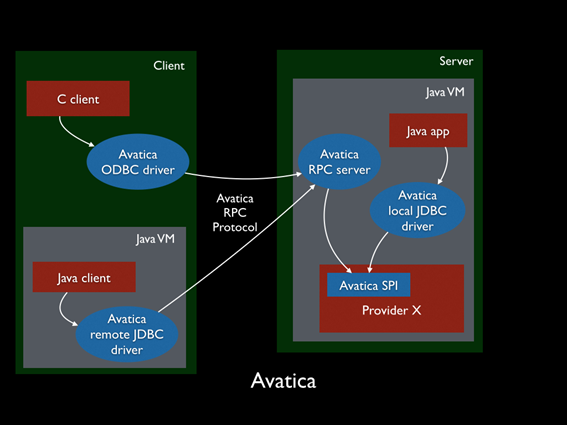
Estos agentes JDBC, se desplegarán como contenedores y funcionarán de intermediarios entre la Onesait Platform y la base de datos que queremos usar. El driver en sí de la base de datos irá embebido en el contenedor del agente JDBC que montará un servidor JDBC de Avatica, donde la Plataforma, con sólo el driver cliente de Avatica, se conectará a cualquier base de datos que maneje el agente que funcionará de proxy entre la Plataforma y la base de datos.
Configuración y uso de estos agentes
Vamos a seguir un proceso en el que vamos a conectarnos por JDBC a Google BigQuery (vía cuenta de servicio + token JSON de acceso), el cual es un buen caso de driver pesado y que no tiene sentido incluir en el core de la Plataforma.
El driver JDBC puede obtenerse desde esta URL en concreto.
Necesitaremos también una cuenta de servicio de BigQuery junto con un token JSON de acceso que tendremos que descargar. Esto puede crearse todo desde la consola de Google Cloud Platform.
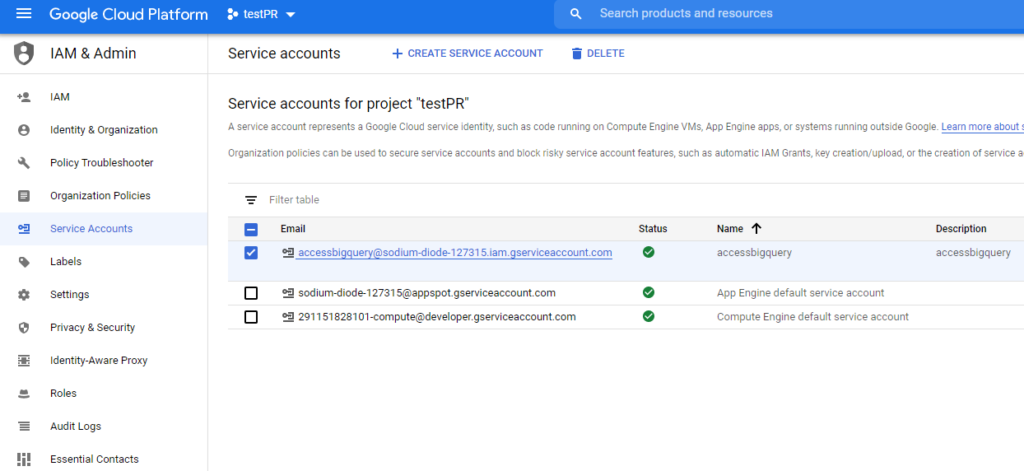
También, vamos usar una tabla creada con BigQuery que será la que usemos como ontología.
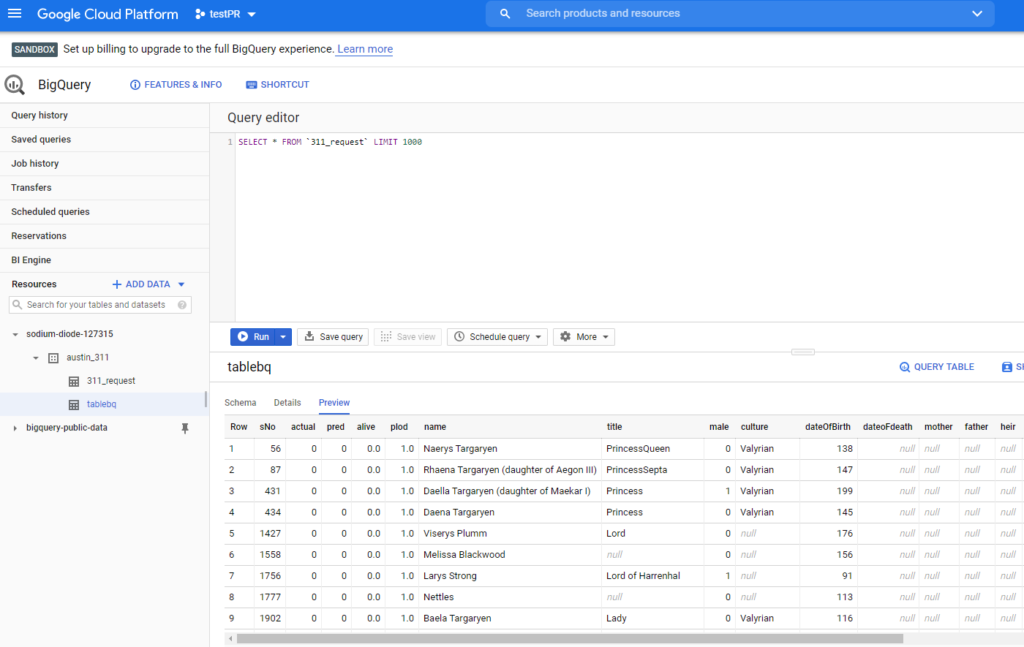
Creación del agente JDBC
El primer paso, requiere desplegar en el CaaS una de las imágenes existentes como un contenedor y configurarla correctamente. También, podría ser necesario, según el caso, crear una imagen Docker partiendo de una existente, para especializarla en cierta base de datos.
En este momento, existen 3 imágenes, MySQL 8, BigQuery y una imagen genérica para construir nuestro propio agente JDBC.

Uso de la imagen específica para crear conexiones
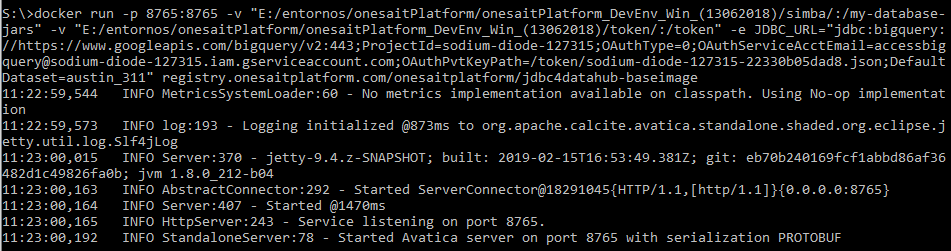
Las imágenes especificas son fáciles de usar, sólo es necesario definir la variable de entorno JDBC_URL que determinará la URL de conexión JDBC a la base de datos destino. Por ejemplo, para definir una conexión contra BigQuery vía nuestro archivo JSON de autenticación con el agente, usaremos la imagen especifica de BigQuery.

Será necesario usar un volumen compartido donde dejar la clave JSON (en /token) y después incluir la propia url de conexión (jdbc:bigquery://… https://www.simba.com/products/BigQuery/doc/JDBC_InstallGuide/content/jdbc/bq/using/connectionurl.htm):

Esto nos arrancará un agente JDBC que atacará a BigQuery por la URL proporcionada, junto con el token de acceso. Este agente será accesible por el puerto 8765 del contenedor, que será el que tendremos que usar para acceder al mismo.
Uso de la imagen genérica para crear conexiones
En el caso de usar la imagen genérica, es necesario proporcionar también los drivers, vía volumen compartido sobre la carpeta “/my-database-jars”. Aquí incluiremos los descargados.
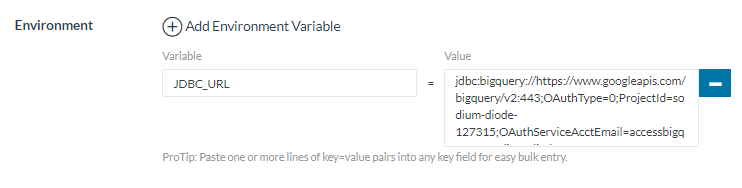
Para su uso en Rancher, sólo es necesario proporcionar la variable de entorno JDBC_URL y, en caso de usar la imagen genérica, el volumen con los drivers:
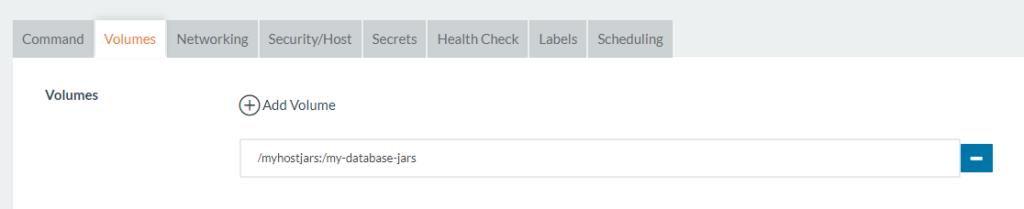
Una vez el contenedor está configurado y arrancado, se puede continuar al siguiente paso.
Creación de Ontología a partir del Agente JDBC
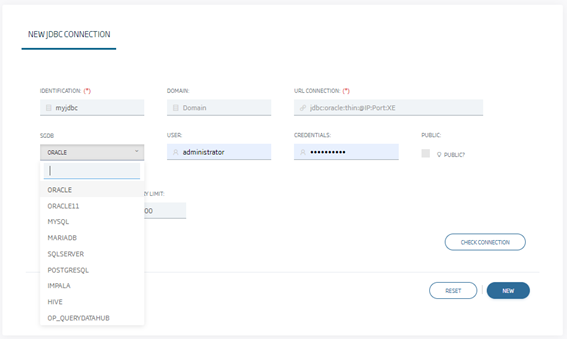
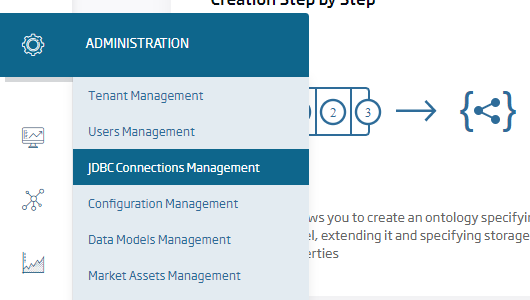
Para este paso iremos a la opción JDBC Connections Management, algo sólo disponible para el rol Administrador, y crearemos una nueva conexión:
En esta página, hay que usar la opción «OP_QUERYDATAHUB» en la base de datos y, a la hora de seleccionar la URL, completar una del tipo:
jdbc:avatica:remote:url=http://{agentip}:{agentport};serialization=protobuf
Por ejemplo:
jdbc:avatica:remote:url=http://jdbc4datahubbigquery:8765;serialization=protobuf
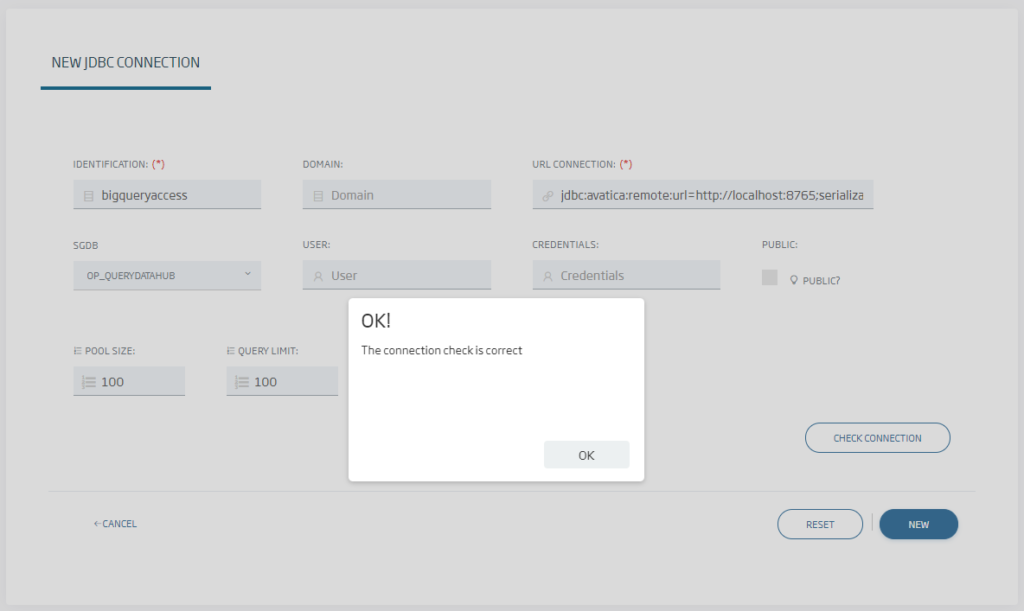
Después, sólo si la base de datos destino tiene usuario/password, deberán proporcionarse en esta pantalla y darle a crear la conexión. El agente enviará estas credenciales a la base de datos destino, con lo que no tendremos que tenerlas almacenadas en otro sitio. En el caso de bigquery no es necesario (al usar el Token de acceso), por lo que lo podemos dejar vacío.
Con lo anterior realizado, ya es posible crear ontologías como cualquiera del tipo relacional a través de «Creation from external relational database» y seleccionando la nueva conexión.

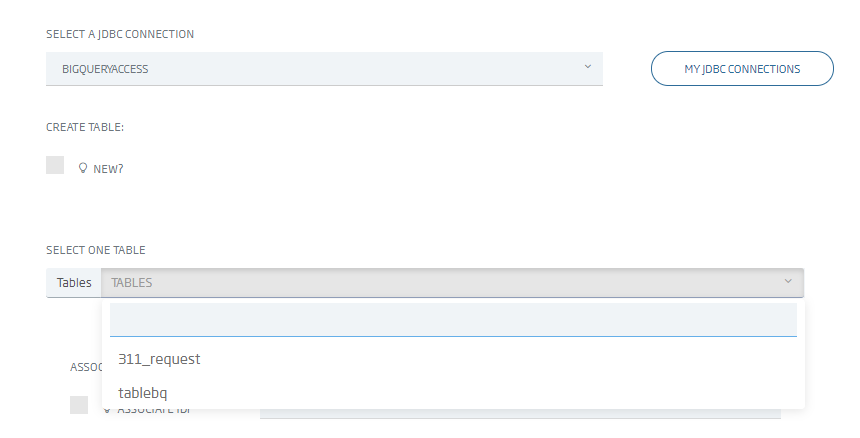
Y finalmente accediendo a los datos como a cualquier ontología, por lo que podemos usar esta ontología para generar un Dashboard sobre BigQuery, exponerla como API o muchas otras opciones que nos ofrece plataforma.
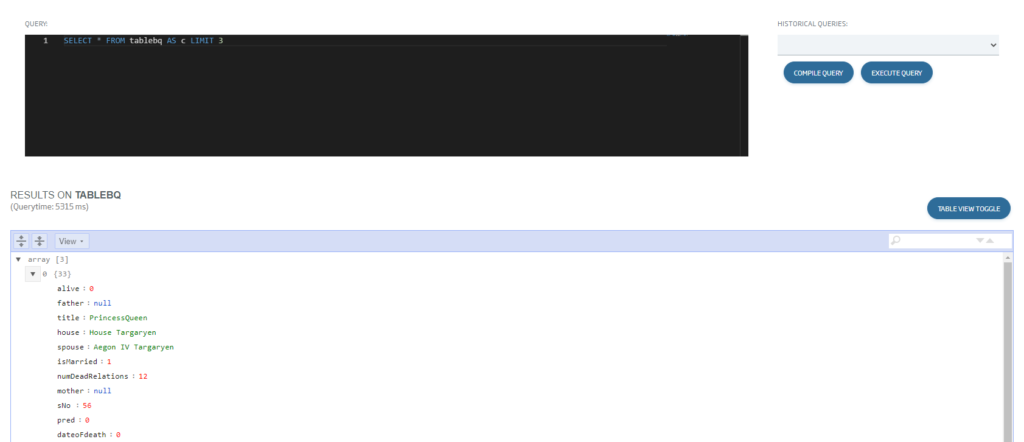
Sencillo, ¿verdad? Esperamos que os haya parecido interesante, y cualquier duda que tengáis, dejadnos un comentario.


