
Configuración avanzada de Fluentd
Fluentd es la F del stack EFG (Elastic-Fluent-Grafana). Muy resumidamente, el caso de uso que tenemos propuesto para en el marco de referencia es el siguiente: escribimos desde un cierto artefacto un log en Fluentd. Este, después de uno o más filtros o transformaciones, lo escribe en Elasticsearch. Una vez la información está indexada en Elasticsearch, la visualizaremos gráficamente con la potencia que nos da Grafana.
En esta entrada veremos algunas de las distintas posibilidades que ofrece Fluentd dentro de ese stack EFG.
Información básica de una traza que se escribe en Fluentd y Elasticsearch
Es importante conocer los campos más importantes de la estructura de información que viaja en una traza de Fluentd. En las diferentes estrategias y configuraciones que se describen en esta entrada, suenan a menudo:
- Tag: se trata de la cabecera principal bajo la cual se indexará la información que va a viajar. Está compuesta por dos partes separadas por un punto (.):
- Tag: la primera parte se llama tag, propiamente dicho.
- Label: la segunda parte se llama label.
La composición de ambas, por tanto, da el valor «tag.label». En los ejemplos que veamos a continuación, el tag valdrá «projectName» y la label «serviceName», con lo que las trazas en Fluentd y Elasticsearch estarían encabezadas por el valor de ejemplo: «projectName.serviceName».
El tag es muy importante para entender cómo se filtra y transforma la información en Fluentd y como termina indexándose en Elasticsearch.
- Host: es el nombre del servidor en el que se ejecuta Fluentd. En nuestros ejemplos será «fluentdservice», aunque no será muy relevante.
- Port: es el puerto de Fluentd abierto en el servidor.
- Key: Fluentd añade cierta metainformación a la traza que escribirá en Elasticsearch. Al mismo nivel de los campos de esa metainformación, la llamada key es la que contendrá el mensaje que escribimos nosotros desde nuestro aplicativo. Por defecto, su valor es «message», aunque se puede cambiar como describiremos después. En nuestros ejemplos supondremos que el mensaje que queremos escribir está en formato JSON, lo que además nos valdrá para explicar algunos de los filtros que metemos en la configuración de Fluentd.
- Level: al mismo nivel que la metainformación también se tiene el campo level, que indica el nivel de logging en el que se ha enviado la traza (INFO, ERROR, DEBUG, etc.).
Estrategias de escritura en Fluentd desde Java
Esta entrada está elaborada desde la experiencia que hemos adquirido ante la necesidad de realizar una escritura de logs distribuidos desde varios artefactos Springboot al mismo tiempo. Por lo tanto, aunque las configuraciones de Fluentd descritas sirven para cualquier tecnología que lo ataque, los métodos y estrategias utilizados estarán descritos desde un punto de vista Java.
Lo primero que nos planteamos es si queremos realizar la escritura en Fluentd a través desde slf4j o de una forma nativa. Ambos tienen pros y contras que deben ser considerados. Vamos a explicar cada una de las dos estrategias y luego hacemos un análisis comparativo.
Escritura desde logback
Esta es una típica estrategia de slf4j. Lo primero es añadir en el pom.xml las dependencias necesarias.
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>com.sndyuk</groupId>
<artifactId>logback-more-appenders</artifactId>
<version>1.8.0</version>
</dependency>La librería «com.sndyuk.logback-more-appenders» ofrece un appender de logback para configurar el «logback.xml», de tal forma que se hagan los envíos a Fluentd:
<appender name="FLUENT_TEXT"
class="ch.qos.logback.more.appenders.DataFluentAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
<tag>projectName</tag>
<label>serviceName</label>
<remoteHost>fluentdservice</remoteHost>
<port>24224</port>
<useEventTime>false</useEventTime>
<messageFieldKeyName>message</messageFieldKeyName> <!-- Se puede prescindir de esta línea, ya que el key por defecto es "message" -->
</appender> Además de los parámetros remoteHost y port, que se describen por sí mismos, es importante recalcar la importancia de tag y label. Compondrán el tag que indexará la traza en Fluentd y posteriormente en Elasticsearch. Como hemos explicado anteriormente, su composición resultará en un valor que concatenará tag y label separados por un punto. En el ejemplo de arriba:
projectName.serviceName La forma mediante la cual escribimos en el log de Fluentd a través de logback es homólogo a como escribiríamos en STDOUT o en un fichero.
private final Logger logger = LoggerFactory.getLogger(this.getClass());
(...)
logger.info(message);
logger.debug(message);
logger.error(message); A partir de este momento, si tenemos arrancado Fluentd en el servidor ${fluentdservice} y puerto 24224, deberíamos ver en el log de Fluentd cómo llega la traza de log que estamos escribiendo. Más adelante veremos cómo capturar dicha traza, cómo filtrarla y cómo redireccionarla a un store (en nuestro caso de uso, Elasticsearch).
Escritura nativa
En este caso no definiríamos un appender en logback dedicado a Fluentd. Al contrario, contamos con una librería que nos proporciona un logger que establece una conexión con el servidor de Fluentd.
Lo primero es añadir la dependencia en el «pom.xml».
<dependency>
<groupId>org.fluentd</groupId>
<artifactId>fluent-logger</artifactId>
<version>0.3.4</version>
</dependency> A continuación, directamente podemos hacer uso de la factoría FluentLogger de la siguiente manera:
FluentLogger LOG = FluentLogger.getLogger("projectName", "fluentdservice", 24224);
(...)
LOG.log("serviceName", "message", message);En este caso toda la configuración y uso es programática. A la factoría se le pasa el tag, el host y el puerto.
Más tarde, en la llamada al método log se le pasa la label, el key y el mensaje.
La API de esta librería es muy limitada. Sólo contiene ese método «log».
Al llamar al método, si se tiene el servidor de Fluent arrancado en el host fluentdservice y puerto 24224, se podrá observar en la consola cómo llega la traza enviada (tanto el mensaje como toda la metainformación generada).
Ventajas e inconvenientes de los tipos de escritura (Logback y nativa)
Logback
- Ventajas:
- Uso del estándar slf4j.
- Facilidad de uso y versatilidad.
- Uso de niveles de logging.
- Inconvenientes:
- Al estar configurado como un appender a nivel de logback, todos los logs que cumplan las condiciones establecidas en el fichero «logback.xml» para el appender de Fluentd serán enviados a Fluentd. Por lo tanto, si se establece el nivel en INFO, que es lo habitual, todas las trazas generadas por Spring en el arranque o en cualquier otro momento, así como por cualquier parte de la aplicación que en cualquier momento escriba en el logger estándar, lo hará también en Fluentd. Esto sobrecarga a Fluentd y obliga a meter filtros adicionales para descartar aquellas trazas enviadas que no deban ser enviadas a Elasticsearch.
- Lo anterior no es un problema grave en entornos de poca concurrencia. Pero en entornos de alta disponibilidad podría llegar a sobrecargar a Fluentd y a llenar los buffers de escritura.
Nativa
- Ventajas:
- Soluciona el contra de logback. Es decir, al escribir programáticamente sólo aquello que queremos, Fluentd tiene que trabajar menos, al ser menos necesario el descarte de trazas.
- Inconvenientes:
- API excesivamente simple.
- No permite la escritura de niveles de logging. Es decir, no envía a Fluentd un campo adicional a la metainformación que muestre si el mensaje es un INFO, ERROR, DEBUG, etc.
- Como consecuencia de lo anterior, no permite un cribado por niveles a no ser que se establezca un mecanismo manual.
Configuración general – Archivo fluent.conf
Toda instalación de Fluentd se rige por su archivo de configuración fluentd.conf. Es una configuración tremendamente versátil, con infinidad de posibilidades tanto en el CORE como en plugins adicionales. En este artículo se cubre una pequeña, aunque importante, parte de dicha versatilidad, pero insistimos en la utilidad de basarse siempre en la documentación oficial de Fluentd.
El archivo fluentd.conf es leído y ejecutado por el motor de Fluentd de arriba a abajo. Describimos a continuación algunas de las partes más importantes del archivo basándonos en un caso de uso real.
Source
Normalmente el archivo empieza con la cláusula <source> que describe el origen del input de las trazas recibidas. Sería la puerta de entrada a Fluentd. En nuestro caso, se asume que las trazas llegan directas al servidor por el puerto 24224 y pasan directamente a las siguientes fases (bloques inferiores). Es lo que se llama el input in_forward.
<source>
@type forward
port 24224
bind 0.0.0.0
</source> Otro tipo de source muy utilizado es el @type tile, que prevé que las trazas de entrada son escritas en un fichero y las mismas son consumidas posteriormente por otro proceso que los envía a las siguientes fases.
Sea cual sea la estrategia escogida en el input, la versatilidad de Fluentd permite hacer cosas como añadirle un prefijo al tag con el que llega la traza desde el artefacto Java:
<source>
@type forward
add_tag_prefix prod # Añade el prefijo "prod" al tag original de la traza recibida.
</source> Filter
Las cláusulas <filter> permiten filtrar las trazas recibidas con objeto de descartar aquellas que no cumplan un formato establecido. También son extraordinariamente versátiles. En la cabecera de la cláusula se establece qué tag es el que debe pasar por el filtro. También permite comodines.
Describimos a continuación dos usos que se les ha dado en un caso real.
El primer filtro descrito recibe como entrada las trazas encabezadas por los tags cuya primera parte sea la palabra «project» (siguiendo con nuestro ejemplo establecido inicialmente). Como se puede ver, si en nuestro proyecto tenemos varios servicios, cada uno de los cuales envía su propio tag (por ejemplo project.serviceName1, project.serviceName2, etc.), y el filtro chequearía las trazas llegadas de todos ellos gracias al comodín de la segunda parte del tag.
Hay muchos tipos de tags. El utilizado en este caso (parser) es de gran utilidad cuando lo que escribimos es un JSON. Se encarga parsear los diferentes campos que se encuentre en la estructura JSON, separándolos en pares clave-valor.
- @type: define el tipo de filtro.
- key_name: como recordaremos, el campo key es aquel que contiene el mensaje primitivo enviado desde nuestro artefacto Java. El parámetro key_name de la cláusula le dice a Fluentd el valor de dicha clave. En nuestro caso era la palabra «message».
- reserve_data (boolean): si está a true, conserva el campo con su clave <key_name> y el valor recibido en la traza. Si va a false, sigue parseando sus valores a pares clave-valor, pero en la traza indexada no habrá un campo adicional cuya clave sea el <key_name>.
- remove_key_name_field (boolean): en cada campo resultado del parseo y conversión a pares clave valor, antepone el valor del campo <key_name> a cada una de las claves que resultan del parseo.
- La subcláusula <parse> le presenta al filtro el método que debe usar para parsear el contenido del campo <key_name>. En nuestro caso es json, pero puede tener muchas otras propuestas de parseo, incluyendo expresiones regulares ad-hoc.
<filter project.**>
@type parser
key_name message
reserve_data true
remove_key_name_field false
<parse>
@type json
</parse>
</filter> El siguiente bloque presenta otro filtro. En este caso, se encarga de filtrar mediante una expresión regular o patrón. El @type es grep y la expresión se encarga de hacer coincidir y quedarse sólo con aquellos mensajes que tengan la palabra reservada «inout». Todo lo demás es descartado.
<filter project.**>
@type grep
<regexp>
key message
pattern /^.*inout.*$/
</regexp>
</filter> Match
La cláusula <match> es donde se le dice a Fluent qué es lo que tiene que hacer con la información resultante de todo lo hecho anteriormente. En nuestro caso, queremos que coja las trazas cuyo tag tenga la palabra «project», como prefijo, aceptando mediante el comodín ** todos los sufijos.
Además, también en nuestro caso queremos que haga dos cosas con las trazas «ganadoras». Lo describimos a continuación:
- @type copy: mediante el valor «copy» le decimos a Fluentd que vamos a hacer más de una cosa con la información. Cada una de esas cosas se indica en las subcláusulas <store>.
- <store>: indica qué se va a hacer con las trazas que cumplan los requisitos.
- @type elasticsearch: en este punto le decimos al primer store que la estrategia a seguir es una escritura en Elasticsearch. Las posibilidades de este plugin son muy extensas, y están descritas en la documentación del mismo.
- @type stdout: como se puede deducir, escribe las trazas en consola.
<match project.**>
@type copy
<store>
@type elasticsearch
host elasticdb
port 9200
logstash_format true
logstash_prefix applogs
logstash_dateformat %Y%m%d
include_tag_key true
type_name app_log
tag_key @log_name
flush_interval 1s
user elastic
password changeme
</store>
<store>
@type stdout
</store>
</match> Estrategias de uso del Buffer
Fluentd contiene un buffer en el que se van escribiendo las trazas ganadoras. El mismo está dividido en «chunks». Según una política totalmente configurable en términos de tiempos, ciclos y tamaños, esos chunks son volcados a los stores de salida. Una vez más, recomendamos la documentación oficial de Fluentd para saber de primera mano las posibilidades que ofrecen diferentes estrategias de buffering en Fluentd. No obstante, describimos a grandes rasgos los dos grandes grupos existentes según la estrategia escogida: en memoria y en fichero.
En esta sección de la documentación de Fluentd se describen exhaustivamente todos los parámetros que modifican las estrategias a seguir.
Buffer en fichero
Para configurar el buffer en fichero, en la sección <match> hay que definir lo siguiente a nivel de <store>:
<buffer>
@type file
path /var/log
</buffer> El parámetro único «path» indica la ruta donde se escribirán los logs. Es importante notar que por cada chunk se escribirán dos ficheros: el log en sí y un fichero de metainformación con datos de control del chunk correspondiente.
Esta estrategia es más fácil de monitorizar, ya que se puede hacer un seguimiento en vivo del crecimiento y rotación de los chunks. Si los mismos empiezan a crecer, es que se la estrategia está siendo errónea, ya que Elasticsearch no es capaz de tragarse con la suficiente velocidad todo el flujo de salida que está emitiendo Fluentd.
Buffer en memoria
Es la configuración por defecto. Los chunks se almacenan en memoria. Este hecho hace que el tamaño de los chunks por defecto y los tiempos y ciclos de vaciado de los mismos sean mucho más pequeños. Esta estrategia es mucho más difícil de monitorizar, al no existir una escritura física de ficheros. En el caso de que se vea sobrepasado, por ejemplo, el tamaño máximo del buffer, nos enteraremos cuando ya se haya producido el error.
Configuración en alta disponibilidad
En entornos de alta concurrencia es muy recomendable llevar a cabo una configuración en alta disponibilidad, muy bien descrita, como de costumbre, en la documentación oficial de Fluentd.
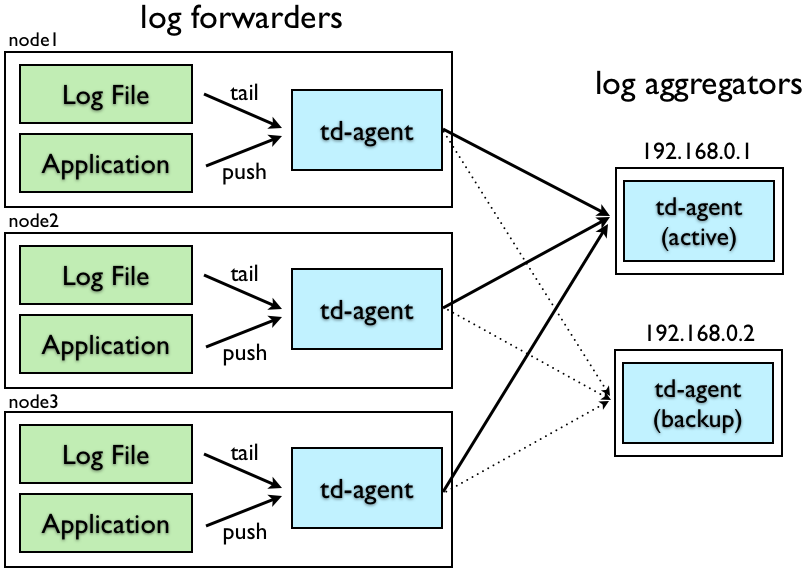
En este tipo de configuración se establecen dos tipos de nodos: log-forwarders y log-aggregators. En realidad, esta estrategia no es sino una «división de tareas». Los log-forwarders realizan todo el trabajo que hacen las secciones superiores (source y filter), mientras que los log-aggregators hacen el trabajo descrito en la sección de salida (match).
Log-forwarders
Como se ha dicho, los forwarders se limitan a recibir las trazas, filtrarlas y, una vez filtradas, sustituyen el interior de la cláusula <match> por un simple forward a tantos <servers> como log aggregators se hayan configurado. En el ejemplo del diagrama, hay dos, con lo que la configuración sería:
<source>
@type forward
port 24224
bind 0.0.0.0
</source>
<filter project.**>
@type parser
key_name message
reserve_data true
remove_key_name_field false
<parse>
@type json
</parse>
</filter>
<filter project.**>
@type grep
<regexp>
key message
pattern /^.*inout.*$/
</regexp>
</filter>
<match project.**>
@type forward
<server>
host fluentd-a1
port 24224
</server>
<server>
host fluentd-a2
port 24224
standby
</server>
</match> Como se puede observar, en un log forwarder, toda la configuración es exactamente igual exceptuando la cláusula <match>. Esto significa que todo lo referente al origen de las trazas y a la transformación y filtros posteriores para lograr las trazas «ganadoras» es exactamente igual que en una configuración de un único nodo.
Sin embargo, en la cláusula <match>, que se establece de tipo @type forward, se configuran dos servidores, el segundo de los cuales se inscribe con la palabra reservada «standby«. Esto indica todas las trazas seleccionadas son enviadas sin más comprobaciones a un log-aggregator «fluentd-a1». Cuando este muere, las trazas pasan a enviarse al log-aggregator «fluentd-a2».
Log-aggregators
Como se puede imaginar, los log-aggregators se limitan a recibir las trazas de los log-forwarders y realizar el trabajo que en la configuración de único nodo realizaba la cláusula <match>. Se realiza mediante este fichero de configuración:
<source>
@type forward
port 24224
bind 0.0.0.0
</source>
<match project.**>
@type copy
<store>
@type elasticsearch
host elasticdb
port 9200
logstash_format true
logstash_prefix applogs
logstash_dateformat %Y%m%d
include_tag_key true
type_name app_log
tag_key @log_name
flush_interval 1s
user elastic
password changeme
</store>
<store>
@type stdout
</store>
</match>Es decir, todas las trazas recibidas pasan directamente al <match>, que las escribe en Elasticsearch y las saca por salida estándar.



Pingback: Configuración en Kubernetes – Onesait Platform Community