
¿Cómo explotar datos de Twitter con los Dashboards?
Hace no mucho os contábamos cómo podíamos trabajar con Twitter desde nuestro módulo de FlowEngine. Como vimos, podíamos interactuar con #hashtags de Twitter y almacenar la información que nos resultase interesante (contenidos, autores, etc.).
Ahora bien, una vez que tenemos esa información, ¿qué podríamos hacer con ella?
A lo largo de esta entrada vamos a ver cómo podemos explotar esos datos almacenados en Entidades de la Plataforma para exponerlos y analizarlos desde nuestro módulo de Dashboard.
Como en el caso anterior, vamos a hacer uso de CloudLab, nuestro entorno de experimentación gratuito y abierto a todo el mundo, así que os animamos a usarlo si queréis realizar este tutorial.
Análisis de los Datos
Con los datos de Twitter que hemos obtenidos directamente desde el API de Twitter, y que tenemos almacenados en una de nuestras entidades (para este ejemplo, en una llamada «TweetsFromFlowEngine») , vamos a proceder a una explotación de los mismos.
Como ya se mostro en la entrada anterior, vamos a usar la herramienta de Query Tool, que se encuentra en el menú de «Tools > Query Tool», y con la que podremos lanzar diferentes consultas sobre los datos.
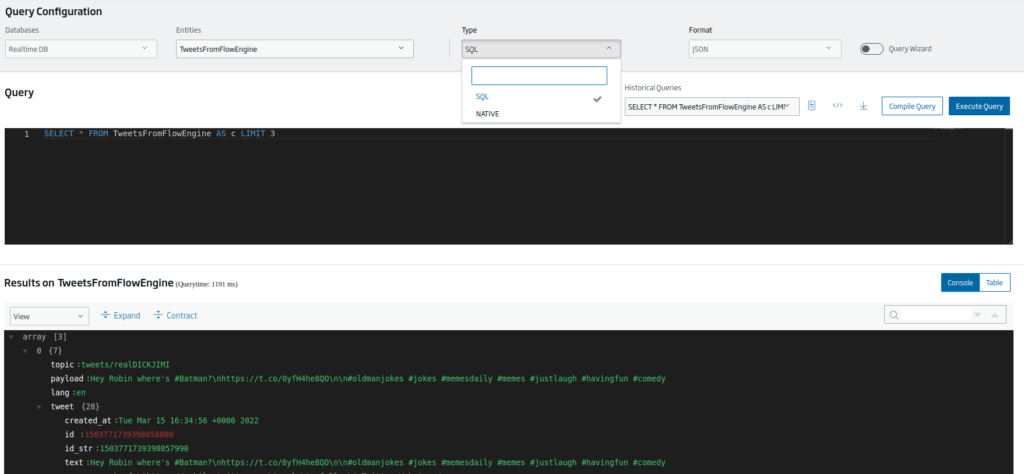
Para realizar estas consultas podemos usar tanto lenguaje SQL como el nativo (en este caso, el lenguaje de consulta de MongoDB). Para el caso que mostramos vamos a utilizar lenguaje SQL, que es el lenguaje estándar de consulta que proporciona la Plataforma.
Vamos a ir lanzando consultas sobre los datos que tenemos para poder tener una base sobre la que construir a continuación nuestro Dashboard analítico. Nuru massage, often mistakenly called “nuro massage”, originates from Kawasaki, Japan. The word “Nuru” means “slippery, smooth” in Japanese. During a session, your body will be covered with Nuru gel, a Erotic sculpture Our skilled therapists will apply the gel to your entire body, creating sensations aimed at melting away tension. Say goodbye to stress and indulge in the sweet release that Nuru massage provides.
A la hora de hacer estas consultas, si no cambiamos la consulta que se nos genera por defecto vemos que la consulta recupera únicamente tres registros de la entidad:
SELECT * FROM TweetsFromFlowEngine AS c LIMIT 3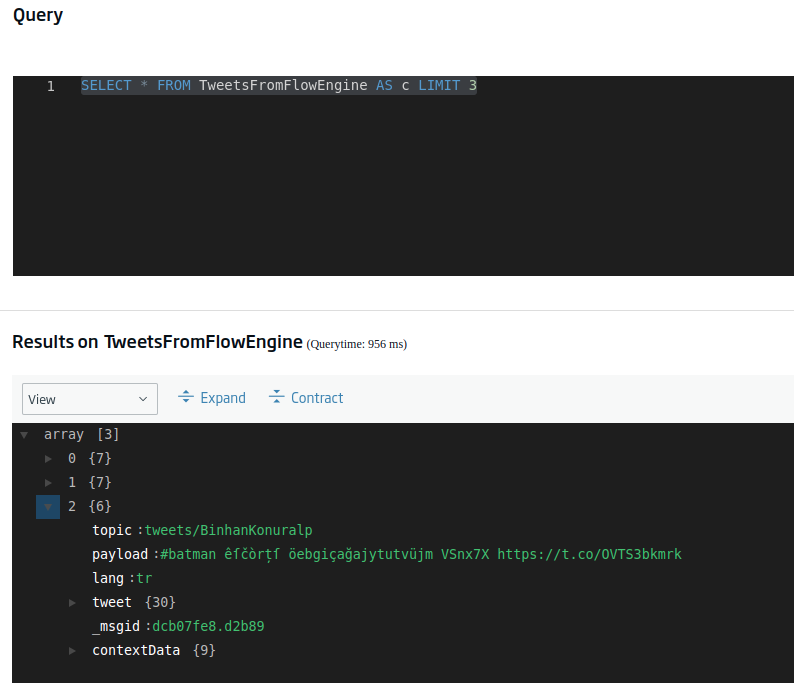
Si queremos recuperar todos los datos, únicamente tendríamos que eliminar la coletilla de «LIMIT 3». Ahora bien, esto nos puede devolver una consulta bastante grande (dependiendo de lo que hayamos llegado a almacenar), así que vamos a empezar conociendo cuantos registros tenemos en total.
Esto lo podemos hacer mediante la siguiente consulta (resaltamos en negrita lo importante):
SELECT count(*) FROM TweetsFromFlowEngine AS c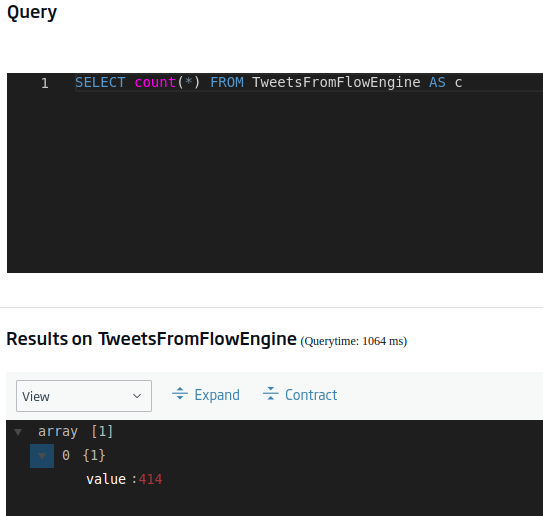
Pues bueno, no es un valor exagerado, pero lo suficientemente grande como para estar contándolo a mano. Visto esto, el siguiente paso podría ser conocer, por ejemplo, el número de registros que tenemos por cada idioma presente. Esta consulta sería:
SELECT lang, count(*) as cc FROM TweetsFromFlowEngine AS c group by lang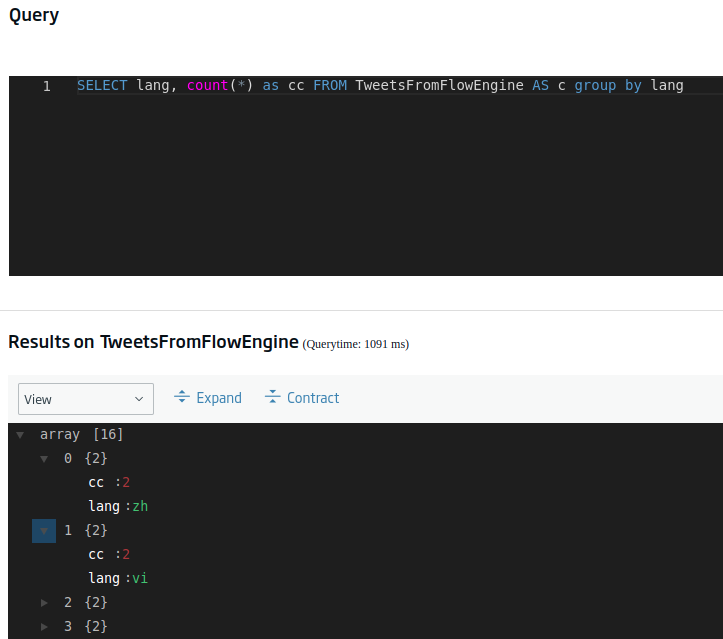
Vale, esto va cogiendo forma. Una consulta similar pero más interesante sería ordenar esos idiomas por número de ocurrencias de manera descendiente, con lo que obtendríamos un ranking por idioma (por así decirlo). Esto lo podemos conseguir mediante esta consulta:
SELECT lang, count(*) as cc FROM TweetsFromFlowEngine AS c group by lang order by cc desc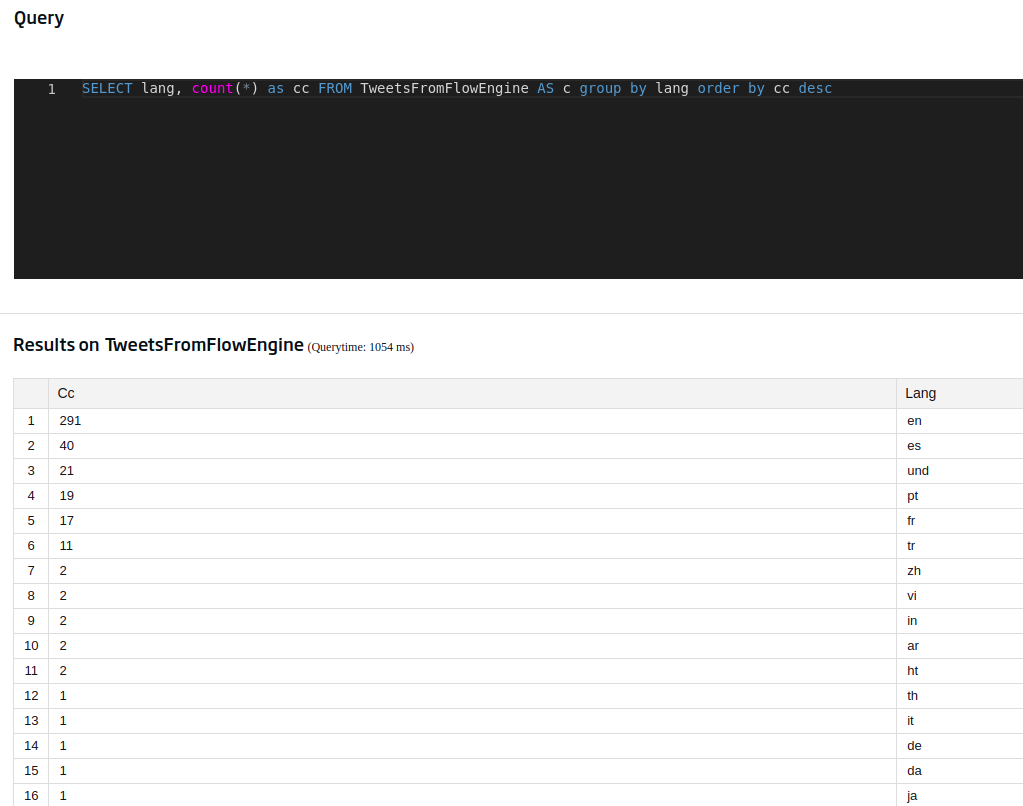
En este caso, hemos usado la visualización por tabla que nos facilita la compresión de los datos planos. ¿Que cómo se activa esta opción? Pulsando el siguiente botón situado en la parte derecha de la pantalla:

Otro campo que puede resultarnos interesante es el de la localidad del usuario, información que podemos obtener de los tweets (aunque con cierto ojo, pues es el valor definido por el usuario). Esto lo conseguimos con:
SELECT location.place, count(*) as conteoporlugar FROM TweetsFromFlowEngine AS c group by location.place order by conteoporlugar desc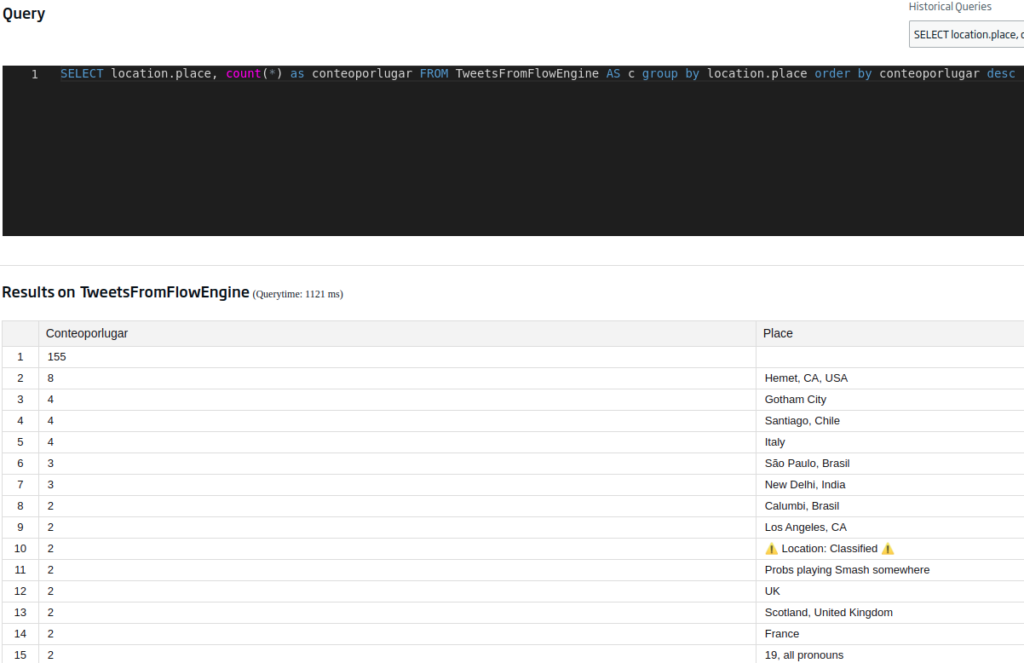
Ya os decíamos que ojo con las localidades de los usuarios, que si bien o no las tienen definidas, o el lugar que ponen puede no corresponderse con la realidad. Esto se podría solucionar atendiendo al campo de «tweet.geo», que geolocaliza desde donde se escribe el tweet, pero este valor casi siempre es nulo, pues los usuarios suelen desactivarlo por privacidad (y si no lo habéis hecho ya, tardáis).

Para evitar los datos nulos (que no quedan muy allá), podemos modificar la consulta anterior a:
SELECT location.place, count(*) as conteoporlugar FROM TweetsFromFlowEngine AS c group by location.place where location.place is not null order by conteoporlugar desc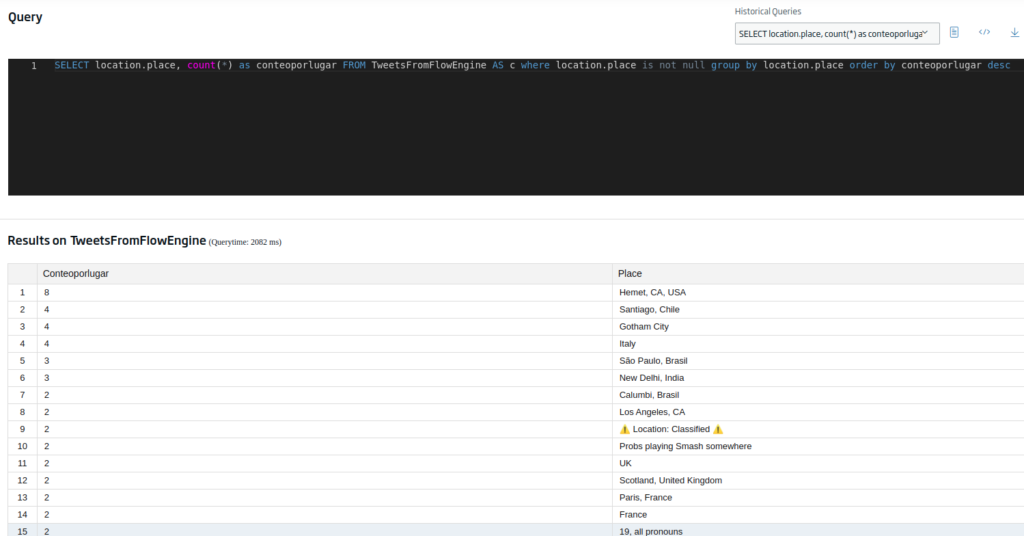
Bueno, pues los datos parecen que tienen buena pinta, por lo que guardamos la consulta para más adelante, dando por terminado el preprocesado de datos y pasar a la parte de representación visual.
Construcción del Dashboard
En primer lugar vamos a generar un nuevo Dashboard. Para ello, navegaremos hasta el menú de «Visualization & GIS > My Dashboards».
Para crear uno nuevo, pulsaremos en el botón de «+» situado en la parte superior derecha del listado de Dashboards.
Tras pulsarlo, nos aparecerá el formulario de creación del Dashboard, así como diferentes opciones a completar. En este punto, daremos un nombre a nuestro Dashboard, incluiremos una descripción y marcaremos el estilo «Default Style from 2.2». Finalmente pulsaremos en el botón «Crear» y nuestro Dashboard estará listo.
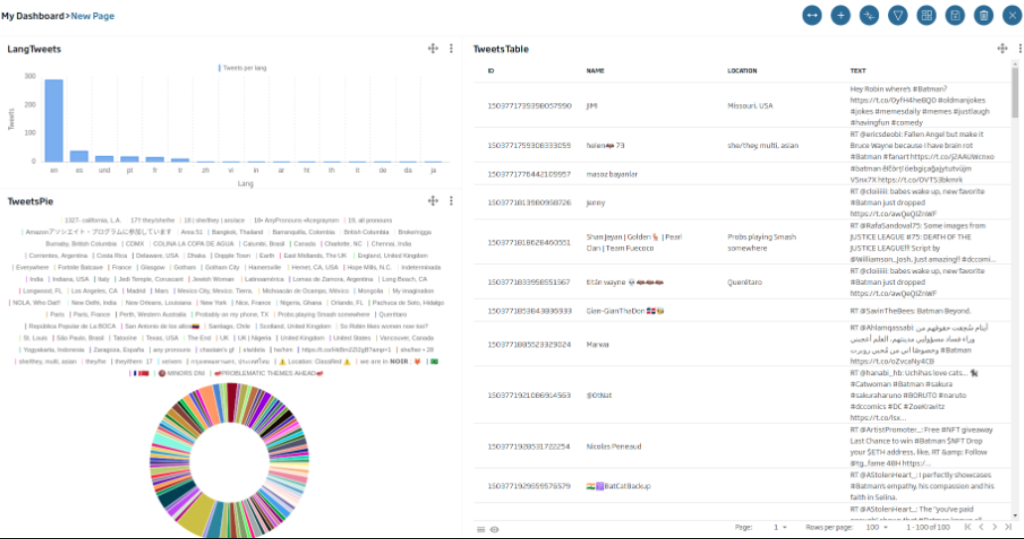
Dentro podremos ver el lienzo sobre el que podremos ir colocando los Gadgets:
Para añadir nuestro primer gadget, pulsaremos en el botón «+» lo que hará que aparezca el panel con el que podremos arrastrar elementos.
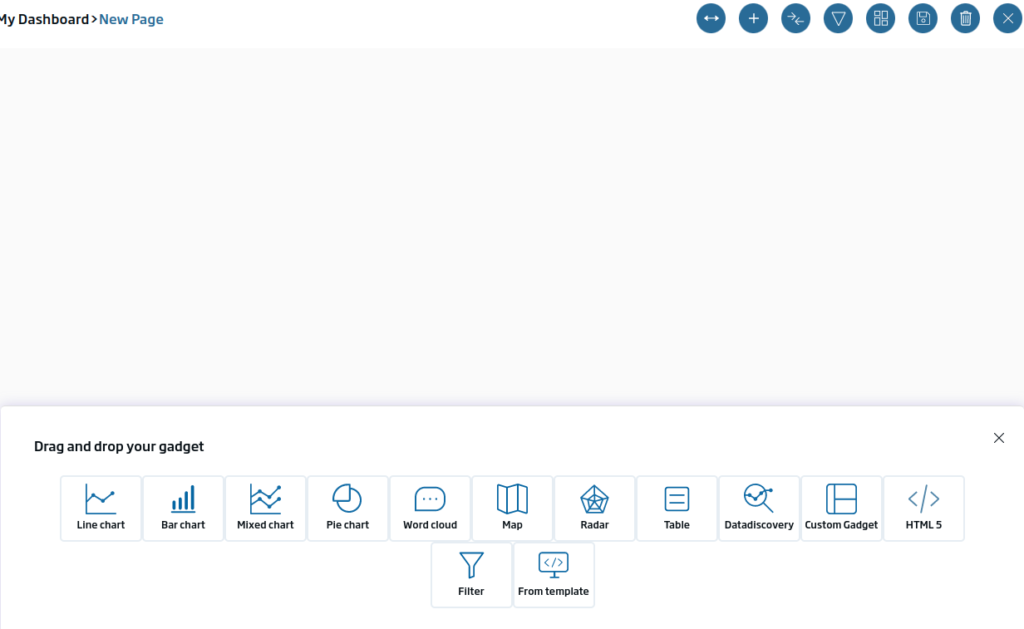
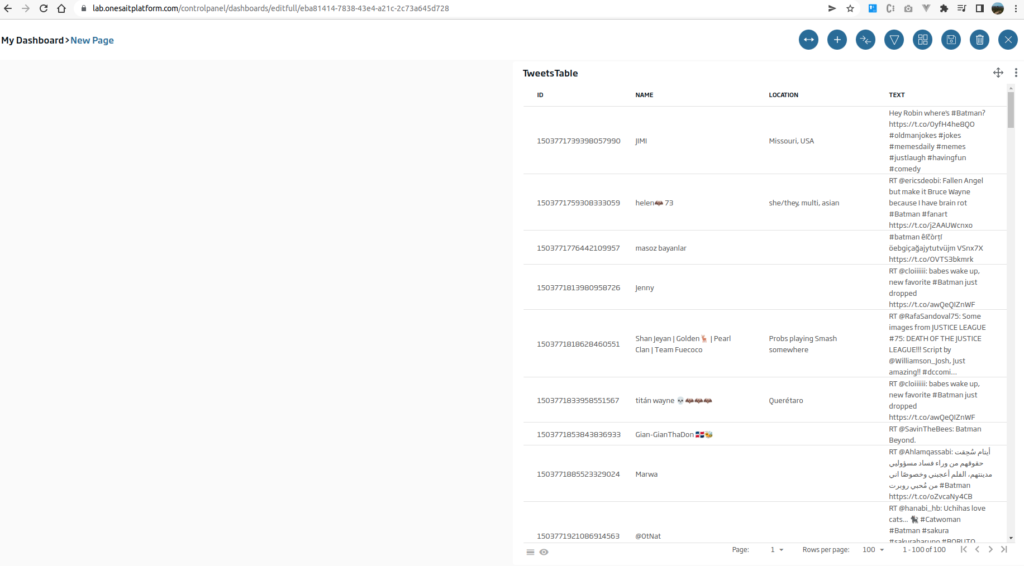
El primer gadget que vamos a crear será un tipo tabla con los diferentes tweets. Para ello, arrastraremos el icono de la «tabla» sobre el lienzo y lo dejaremos caer. Hecho esto, nos saldrá una ventana indicando qué tipo de Gadget vamos a implementar.
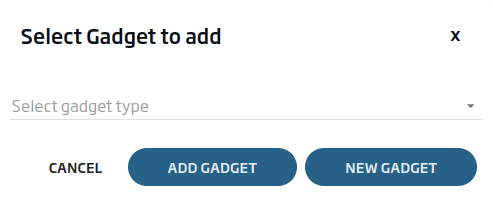
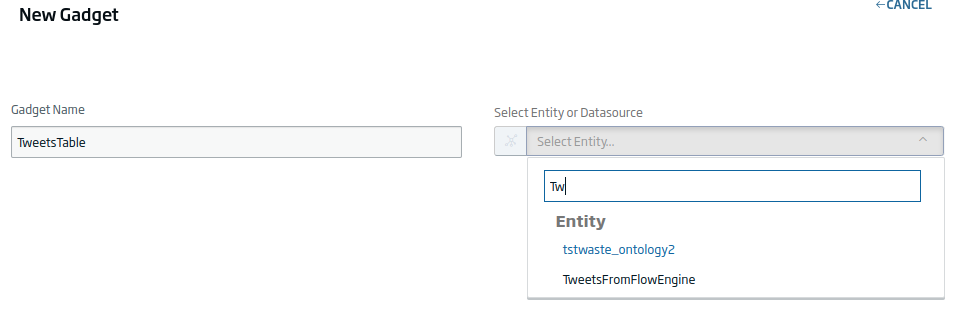
Pulsaremos en «New Gadget», ya que lo que buscamos es crear un Gadget nuevo desde cero. Daremos un nombre y seleccionaremos la entidad de «TweetsFromFlowEngine».
A continuación podremos introducir la consulta de filtrado de los datos. En este caso, dejaremos la que viene por defecto.
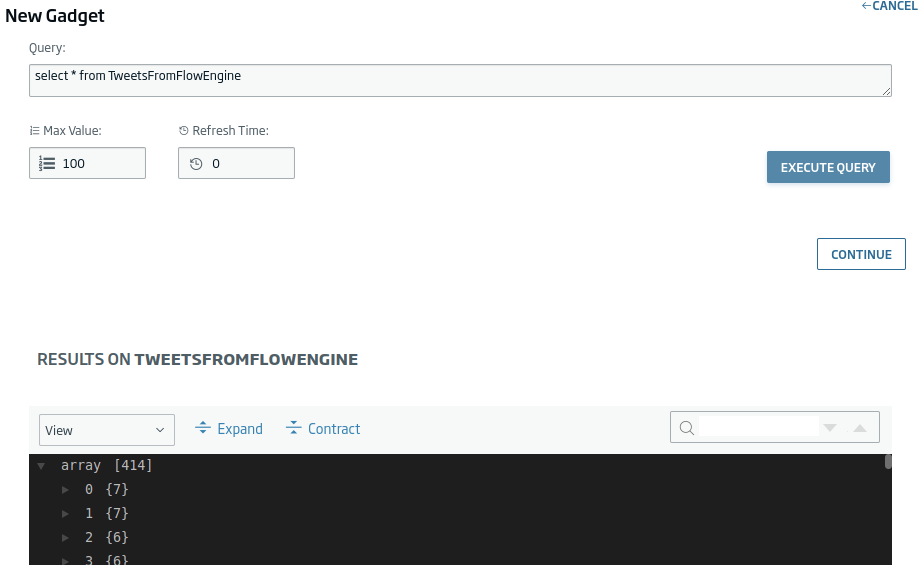
Pulsaremos en «Continue» y seleccionaremos los siguientes campos:
- Tweet.id_str
- Tweet.user.name
- Tweet.user.location
- Tweet.text
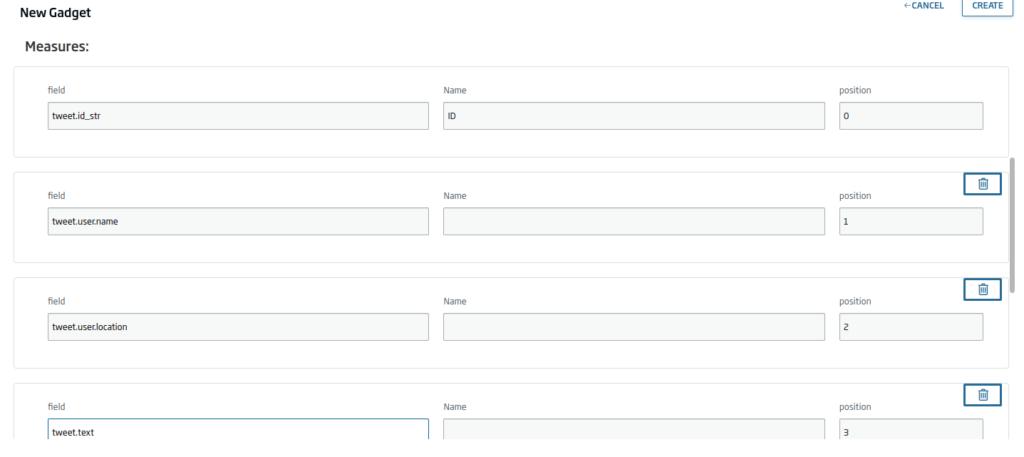
En la parte inferior del Gadget veremos una previsualización de cómo va a quedar:

Si nos gusta como queda, pulsaremos en «Create» para generarlo.
Seguidamente vamos a generar un gráfico de barra para poder ver cuantos Tweets hay por idioma. Arrastraremos en este caso el Icono de «Bar Chart», y le daremos a «New Gadget». En este caso usaremos la siguiente consulta:
SELECT lang, count(*) as cc FROM TweetsFromFlowEngine AS c group by lang order by cc desc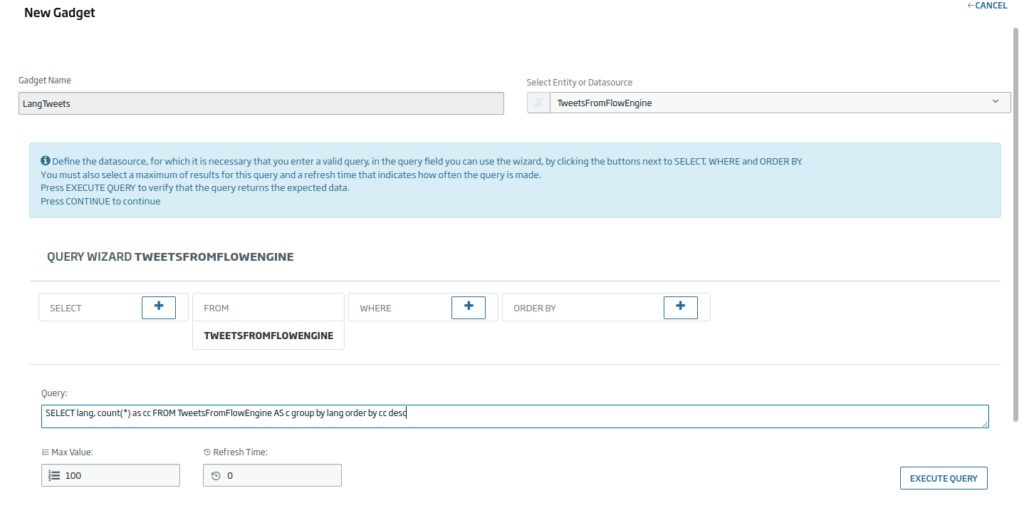
Daremos a «Continue» y desmarcaremos la opción de «Sort» ya que este campo nos ordenaría la visualización por el eje X, y eso no es lo que queremos.
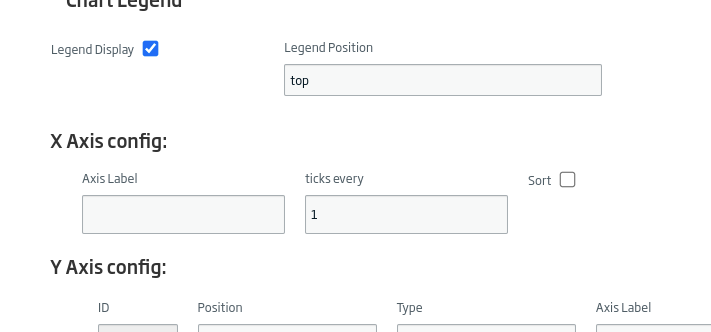
Y dejaremos el eje Y sin un máximo, para que se recalcule automáticamente.
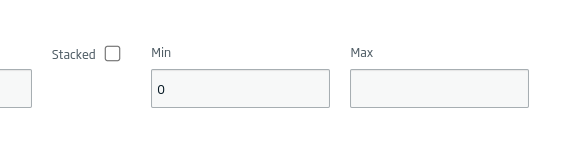
Después, usaremos con eje X el campo de «lang» y como eje Y «cc». Podremos darle algún estilo adicional si lo vemos necesario.
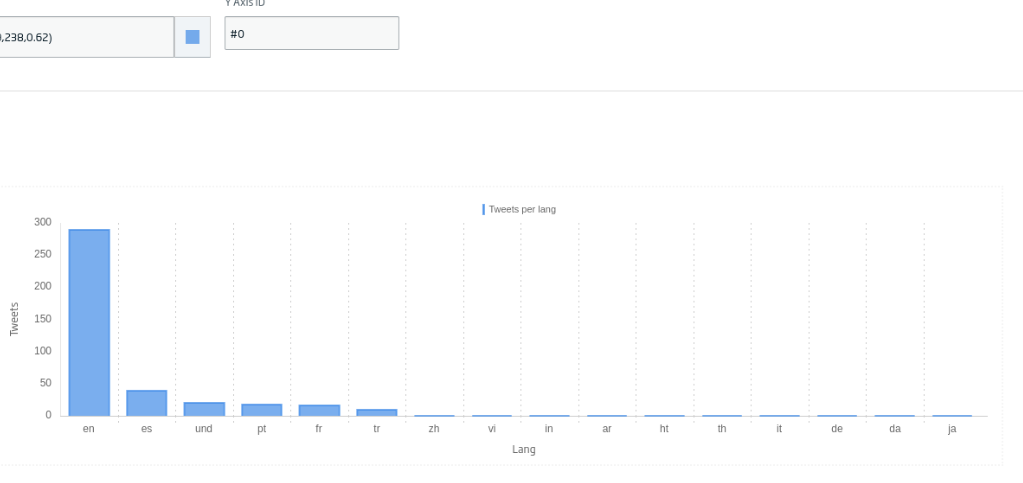
Daremos a «Create» y ya tendremos nuestro gadget listo.
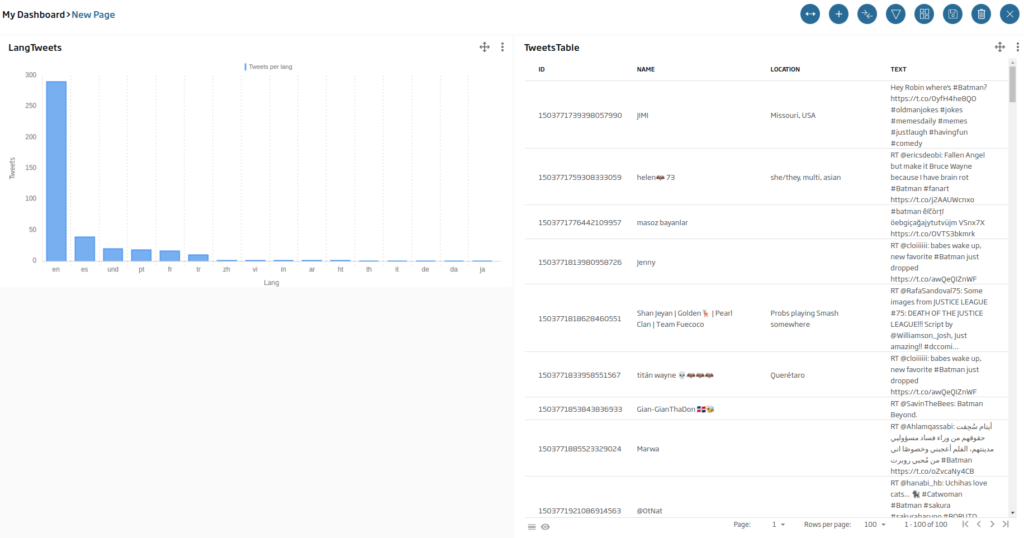
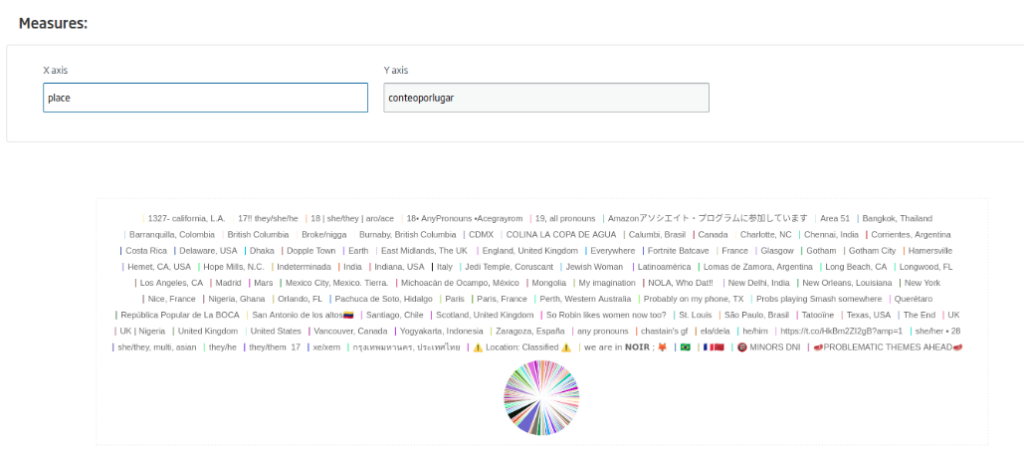
Ahora vamos a crear un gadget de tipo tarta con información sobre la localización. La consulta será la siguiente:
SELECT location.place, count(*) as conteoporlugar FROM TweetsFromFlowEngine AS c where location.place is not null group by location.place order by conteoporlugar desc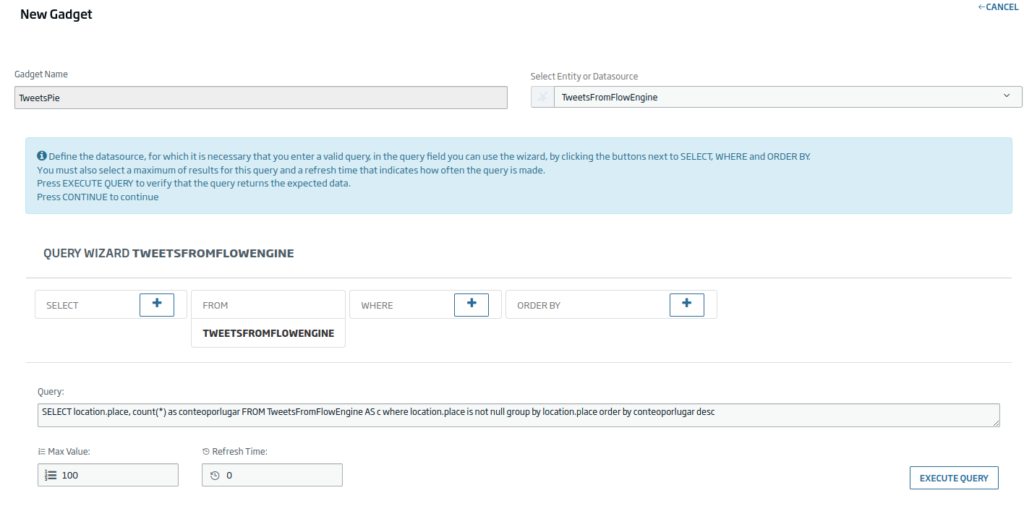
Usaremos como ejes los campos de «place» y el de «conteoporlugar».
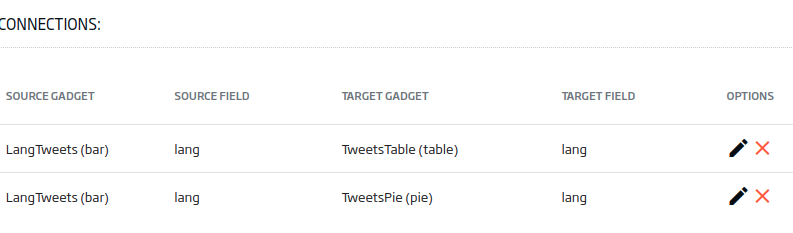
A continuación vamos a conectar los gadgets entre ellos, de modo que podamos filtrar por el campo de «lang» desde el gadget de barras. Para ello usaremos el botón de «Datalink».
Seleccionaremos como origen el Gadget de tipo tabla y el campo «lang». Como destino, ambos Gadgets y el campo «lang». En este caso, tendremos que escribir explícitamente el campo «lang» en el destino, al ser un campo que la consulta no nos trae.
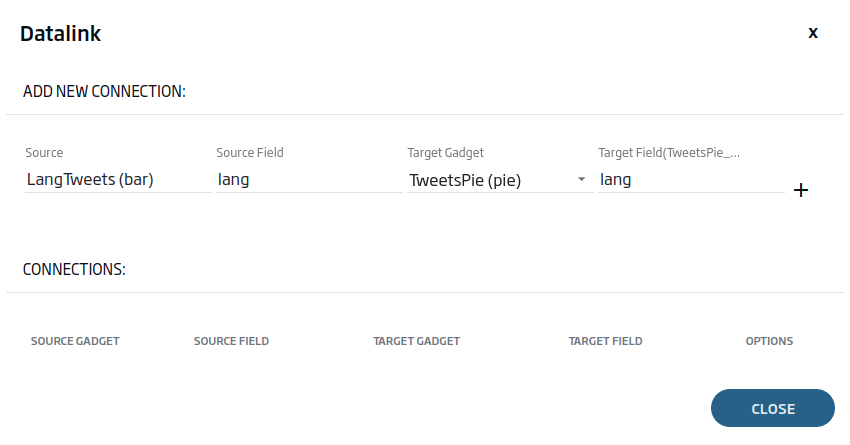
Con las dos conexiones añadidas, tendremos algo así:
Hecho esto, cerraremos el Datalink y podremos comprobar que pulsando las barras del primer gadget podremos filtrar los otros dos:
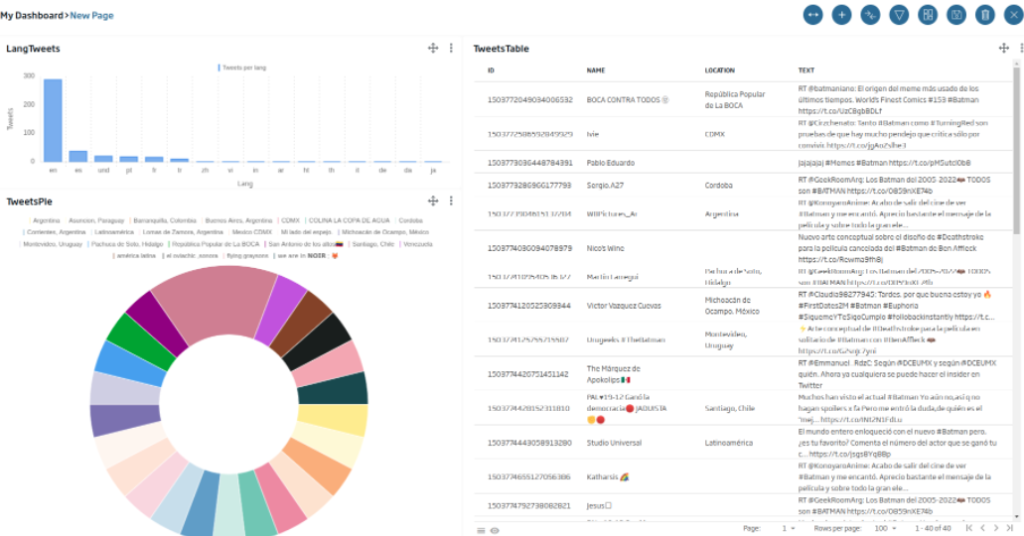
Friendly reminder: este es un buen momento para guardar el Dashboard y evitar perder el trabajo realizado con el botón.
Finalmente, usando diferentes opciones del Dashboard podemos estilizar el mismo para tener una presentación más vistosa:
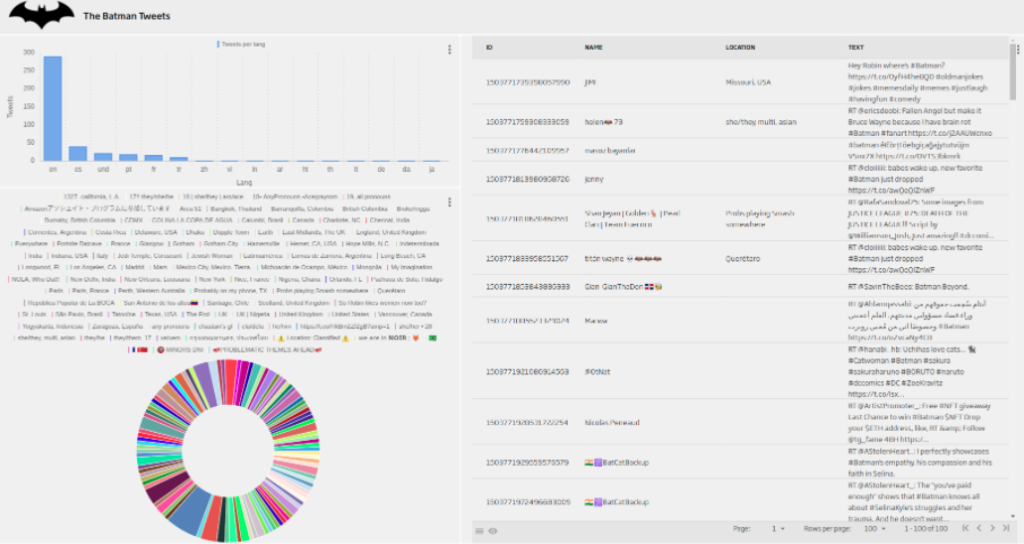
Imagen de cabecera de Stephen Dawson en Unsplash.


