
Hazelcast IMDG en la Onesait Platform
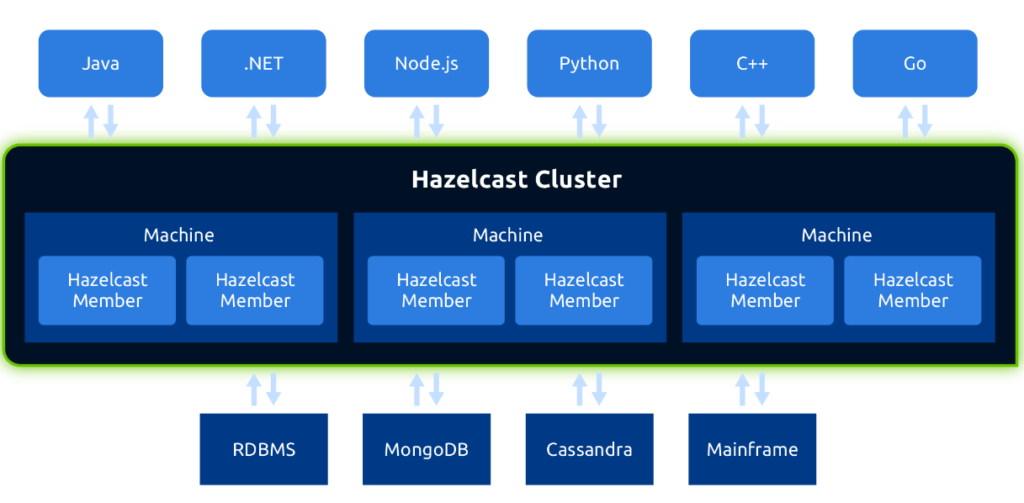
Hazelcast IMDG es uno de los principales productos de Datagrid en el mercado.
Proporciona un datagrid en memoria, distribuido y escalable. Se despliega en modo cluster agrupando diferentes nodos distribuidos de Hazelcast para trabajar de forma conjunta.
Hazelcast IMDG proporciona a las aplicaciones servicios como:
- Caché y estructuras de datos para almacenamiento distribuido en el cluster, como Mapas, Multimapas, Listas…
- Mecanismos de comunicación entre procesos, como Tópicos, Colas.
- Mecanismos de sincronización y ejecución distribuida entre procesos, como Semáforos, Locks distribuidos, Executors distrubuidos…
- Soporte para consultas sobre los datos almacenados en el cluster con un API y sintaxis parecidas a SQL.
Las principales característas de Hazelcast son:
- Escalado dinámico: Proporciona diferentes mecanismos de descubrimiento (multicast, zookeper, kubernetes…) para que nuevos miembros se añadan dinámicamente conectando al cluster. Una vez conectados al cluster, se les asignan las particiones correspondientes para balancear datos y carga entre los distintos miembros.
- Alta disponibilidad: Los datos en el cluster se almacenan replicados, de manera que si un miembro falla, sus datos tienen al menos una copia en otro miembro del cluster y automáticamente son vueltos a replicar en el resto de miembros activos.
- Gestión de Eventos: Cualquier aplicación cliente del cluster se puede suscribir a la notificación de eventos tales como: nuevos miembros del cluster, desconexión de miembros en el cluster, conexión/desconexión de clientes del cluster.
- Posiblidad de despliegue independiente o embebido en la propia aplicación: En el primer caso, cada nodo de Hazelcast es un proceso con la tarea exclusiva de ejercer funciones de datagrid y permitir que las aplicaciones cliente se conecten para utilizar los servicios que ofrece. En el segundo caso, el nodo de Hazelcast es un proceso que comparte las tareas de datagrid con las propias del negocio de la aplicación, y es capaz tanto de admitir conexiones cliente de otras aplicaciones para hacer uso del datagrid, como de ofrecer dichas capacidades de datagrid a la aplicación embebida a través del API de programación.
- Apis en diferentes lenguajes de programación.
La Onesait Platform utiliza Hazelcast para cuatro funciones principales:
- Caché distribuida de Base de datos para ofrecer un mayor rendimiento.
- Servicio de caché para aplicaciones desarrolladas sobre la plataforma.
- Comunicación entre módulos de la plataforma.
- Alta disponibilidad gracias a la gestión de estructuras de datos compartidas entre módulos y réplicas, así como notificación de eventos de conexión/desconexión de réplicas de cada módulo.
Hazelcast, al igual que el resto de componentes de la plataforma, se despliega contenerizado en un módulo independiente llamado cache-manager. De manera que el cluster de hazelcast se forma levantando réplicas de dicho contenedor siendo cada réplica un nodo del cluster.

En un futuro post hablaremos del descubrimiento entre los distintos nodos o réplicas para conectarse entre sí formando el cluster. Como avance, solo comentar que utlizamos Zookeeper como servicio de registro y descubrimiento, de manera que simplemente basta con configurar la estratégia de descubrimiento correspondiente:

Todos los componentes de la plataforma que utilizan alguna funcionalidad de Hazelcast se conectarán al cluster como clientes del mismo, utilizando el API de programación. Estos componentes, de nuevo se vuelve a utilizar zookeeper como servicio de descubrimiento del cluster al que conectarse.
A continuación veremos ejemplos de como se utiliza Hazelcast para dar cobertura a las funcionalidades indicadas
- Caché distribuida de Base de datos:
Todos los módulos de la plataforma utilizan Spring Boot como base tecnológica, de manera que para el soporte de cache de entidades JPA, así como de cualquier otro método que lo necesita, se utiliza Spring Cache y sus anotaciones @EnableCaching y @Cacheable:

La implementación del motor de cache utilizado por Spring se configura al cluster de Hazelcast durante el arranque de cada módulo, registrando como un Bean de Spring el cliente al cluster de Hazelcast, mediante un objeto HazelcastInstance (perteneciente al API de Hazelcast):

Y registrando el Bean del CacheManager de Spring para que utilice como implementación el cliente HazelcastInstance anterior. De manera que toda la configuración de Spring Cache y por ende sus anotaciones, queda asociada a nuestro cluster de Hazelcast:

- Servicio de caché para aplicaciones desarrolladas sobre la plataforma.
Se trata de un servicio proporcionado por la plataforma para que las aplicaciones desarrolladas sobre ella, dispongan de una caché donde almacenar datos temporalmente. No se debe confundir con un servicio alternativo al almacenamiento en ontologías, ya que el propósito es totalmente distinto, no se trata almacenamiento persistente, sino en la memoria del cluster de Hazelcast, y no hay posibilidad de visualización ni de análisis como con las ontologias.
Este servicio es un API REST que proporciona a las aplicaciones la capacidad de crear Mapas en el Datagrid de la plataforma donde almacenar y gestionar pares de clave-valor. De este modo, las aplicaciones disponen de un servidor de almacenamiento temporal sin necesidad de añadirlo a su infraestructura, ya que es la propia plataforma quien crea y administra dichos mapas en su propio cluster Hazelcast.
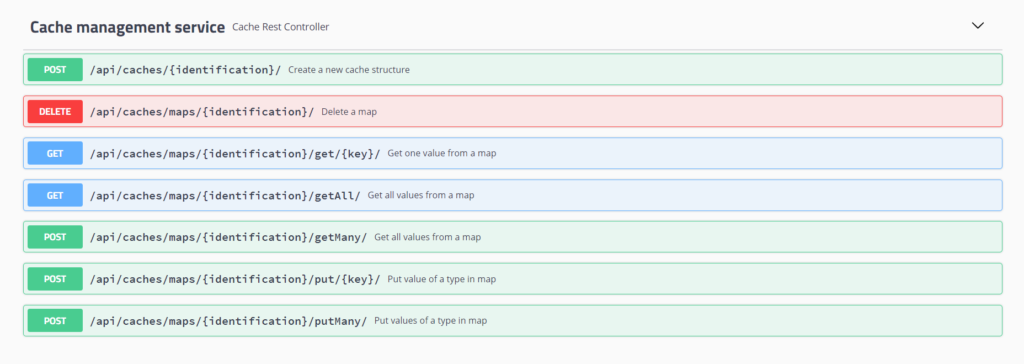
- Comunicación entre módulos de la plataforma.
Utilización de los mecanismos Publish/Subscribe de Hazelcast para comunicar módulos. Por ejemplo, el siguiente código se utiliza para notificar desde el módulo control-panel la modificación por parte del usuario de una regla al módulo rules-engine, para que este realice la modificación en caliente:
Notificación desde el control-panel:

Recepción en rules-engine

- Alta disponibilidad:
Para garantizar la Alta disponibilidad, así como mejorar el rendimiento paralelizando peticiones, es necesario ejecutar réplicas de los diferentes módulos para que haya varias instancias arrancadas en todo momento, que garanticen que si una falla, el resto asuman sus tareas mientras se levanta de nuevo.
La caída de una réplica de un módulo en la plataforma debe ser transparente para las aplicaciones clientes conectadas. Para garantizar esto:
- Ninguna réplica debe almacenar almacenar información de la sesión de una aplicación cliente en su propia memoria, sino que debe recurrir a una estructura de datos distribuida en el Datagrid y accesible por el resto de réplicas.
- Cualquier caída de una réplica debe ser conocida de inmediato por el resto de réplicas, para que estas asuman sus tareas.
- Una nueva réplica implica un nuevo miembro capaz de asumir trabajo e incrementar el rendimiento, de manera que el resto de réplicas deben rebalancear la carga cuando esto suceda.
Por ejemplo, las operaciones transaccionales a ontologías, son gestionadas por el módulo semantic-inf-broker del siguiente modo:
- Almacenamiento de todas las operaciones de una transacción para su procesamiento independientemente de la réplica que la gestione cada operación de manera que cuando se ejecute el commit, la réplica que lo asuma dispone de todas las operaciones:

- Detección de conexiones/desconexiones al cluster para identificar nuevas réplicas, así como caídas, de este modo si cae una réplica en mitad del procesamiento de una transacción, otra réplica intentará finalizarlo:


Pingback: Despliegue de Hazelcast en clúster – Onesait Platform Blog
Pingback: ¿Qué es un Data Grid? – Onesait Platform Community