
Hazelcast IMDG in Onesait Platform
Hazelcast IMDG is one of Datagrid’s main products on the market.
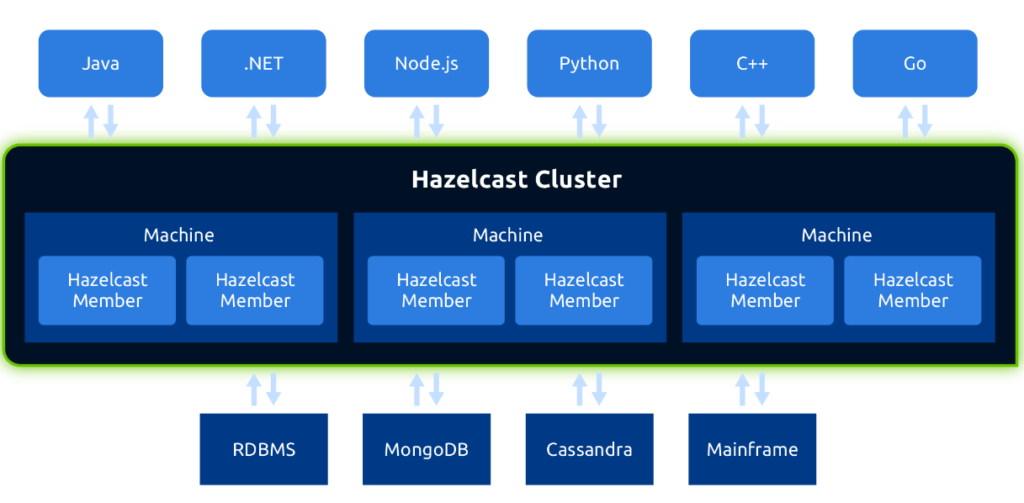
It provides an in-memory, distributed and scalable datagrid. It can be deployed in cluster mode, grouping different distributed Hazelcast nodes to work together.
Hazelcast IMDG provides applications with services such as:
- Cache and data structures for distributed storage in the cluster, such as Maps, Multipaths, Lists…
- Communication mechanisms between processes, such as Topics and Queues.
- Synchronization and distributed execution mechanisms between processes, such as Semaphores, distributed Locks, distributed Executors…
- Support for queries on the data stored in the cluster with an API and syntax that is SQL-like.
Hazelcast’s main features are:
- Dynamic scaling: Provides different discovery mechanisms (multicast, Zookeper, Kubernetes…) so that new members are added dynamically by connecting to the cluster. Once connected to the cluster, they are assigned the corresponding partitions to balance data and load among the different members.
- High Availability: The data in the cluster is stored in replicated form, so that, if a member fails, its data has at least one copy in another member of the cluster and is automatically replicated in the rest of the active members.
- Event Management: Any cluster client application can subscribe to notification of events such as: new cluster members, disconnection of cluster members, connection/disconnection of cluster clients.
- Possibility of independent deployment or embedded in the application itself: In the first case, each Hazelcast node is a process with the exclusive task of exercising datagrid functions and allowing client applications to connect to use the services it offers. In the second case, the Hazelcast node is a process that shares the datagrid tasks with those of the application’s own business, and can both support client connections from other applications to make use of the datagrid, and provide such datagrid capabilities to the embedded application through the programming API.
- Apis in different programming languages.
Onesait Platform uses Hazelcast for four main functions:
- Distributed Database cache for increased performance.
- Cache service for applications developed on the platform.
- Communication between platform modules.
- High availability due to the management of shared data structures between modules and mirrors, as well as notification of connection/disconnection events of mirrors of each module.
Hazelcast, like the rest of the components of the platform, is deployed containairized in an independent module called cache-manager. That way, the Hazelcast cluster is formed by building mirrors of this container, being each mirror a node of the cluster.

In a future post we will describe the discovery between the different nodes or replicas to connect between them forming the cluster. As a preview, we will only comment on the fact that we use Zookeeper as a registration and discovery service, so you just have to configure the corresponding discovery strategy:

All the components of the platform that use some Hazelcast functionality will be connected to the cluster as clients of it, using the programming API. These components are again used by Zookeeper as the discovery service of the cluster to connect to.
We will next see examples of how Hazelcast is used to cover the indicated functionalities
- Distributed database cache:
All the modules of the platform use Spring Boot as a technological base, so for the support of caching of JPA entities, as well as any other method that needs it, Spring Cache and its @EnableCaching and @Cacheable annotations are used:

The implementation of the cache engine used by Spring is configured to the Hazelcast cluster during the start of each module, registering the client to the Hazelcast cluster as a Spring Bean, by means of a HazelcastInstance object (belonging to the Hazelcast API):

And registering the Spring CacheManager Bean to use the previous HazelcastInstance client as implementation, so that all the configuration of Spring Cache, and therefore its annotations, is associated with our Hazelcast cluster:

- Cache service for applications developed on the platform.
This is a service provided by the platform so that the applications developed on it, have a cache where to store data temporarily. It should not be used as an alternative service to ontology storage, as the purpose is totally different: it is not persistent storage, but storage in the memory of the Hazelcast cluster, and you cannot perform visualize or analysis work as with ontologies.
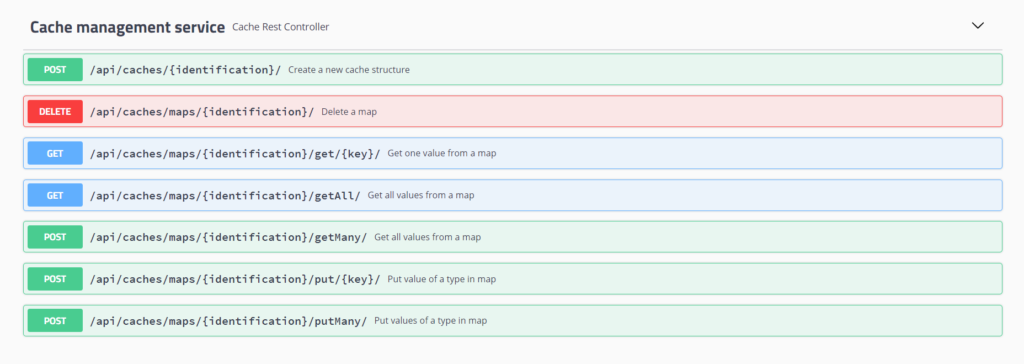
This service is a REST API that provides the applications with the capacity to create Maps in the Datagrid of the platform where to store and manage key-value pairs. This way, the applications have a temporary storage server without the need to add it to their infrastructure, since it is the platform itself that creates and manages these maps in its own Hazelcast cluster.
- Communication between platform modules.
Use of Hazelcast’s Publish/Subscribe mechanisms for module communication. For example, the following code is used to notify from the control-panel module the modification by the user of a rule to the rules-engine module, so that it can make the modification on the fly:
Notification from the control-panel:

Reception inrules-engine

- High availability:
To guarantee High Availability, and to improve the performance by paralleling requests, it is necessary to execute mirrors of the different modules so that there are several instances started at all times, guaranteeing that, should one fail, the rest can assume their tasks while the first one is booting again.
The fall of a mirror of a module on the platform must be transparent to the connected client applications. To ensure this:
- No mirror should sessionstore information of a client application in its own memory, but should instead resort to a data structure distributed in the Datagrid and accessible by the other mirrors.
- Any fall of a mirror must be immediately known by the rest of the mirrors, so that they assume their tasks.
- A new mirror means a new member capable of taking over work and increasing performance, so all other mirrors must rebalance the load when this happens.
For instance, transactional operations to ontologies are managed by the semantic-inf-broker module as follows:
- Storage of all the operations of a transaction for processing independently of the mirror that manages each operation so that when the commit is executed, the mirror that assumes it has all the operations:

- Detection of connections/disconnections to the cluster to identify new mirrors, as well as falls. This way, if a mirror falls in the middle of the processing of a transaction, another mirror will try to finish it:

Translated by: J Rodriguez



Pingback: Clustered Hazelcast deployment – Onesait Platform Blog