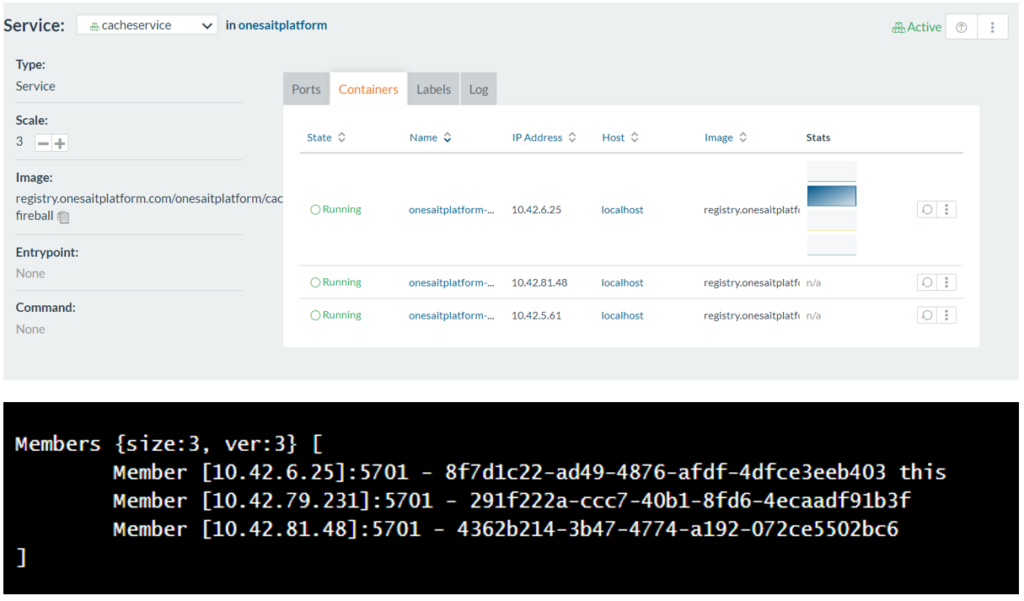
Clustered Hazelcast deployment
As we mentioned in a previous entry, Hazelcast plays a very important role in the Onesait Platform by providing support for certain features.
One of the main features of Hazelcast is dynamic scaling, so that it is possible to add or remove nodes from the cluster on the fly and transparently,: Hazelcast assigns partitions and balances the data and tasks among the different cluster members.
In the Onesait Platform Hazelcast cluster, the different cluster members are containers in the CaaS (Rancher or Openshift). This requires a discovery strategy between nodes within the container network.
En el cluster de Hazelcast de la Onesait Platform los diferentes miembros del clúster son contenedores en el CaaS (Rancher u Openshift). Lo que necesita de una estrategia de descubrimiento entre nodos dentro de la red de contenedores.
There are different discovery strategies for Hazelcast. The Onesait Platform uses, or plans to use, the following ones:
SPI strategy with ZooKeeper
Used by the Onesait Platform on Rancher 1.6.
Based on the following Hazelcast SPI driver: https://github.com/hazelcast/hazelcast-zookeeper
ZooKeeper provides a centralized configuration and directory system for distributed applications. It allows each instance in a distributed ecosystem to register, in a directory, the configuration needed to interact with the rest of the instances in its ecosystem. Using ZooKeeper SPI, each node in the Hazelcast cluster will register in the corresponding directory in ZooKeeper at startup, and will query for instances that have already been registered. If there are any, it will retrieve their connection data and join them to form a cluster.
On a technical and programming level, the cluster support for Hazelcast with ZooKeeper covers the following requirements in the cache-server module:
- Having an instance of ZooKeeper installed:

- Adding ZooKeeper’s SPI dependencies for Hazelcast:
<!-- Zookeeper SPI -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-test</artifactId>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-x-discovery</artifactId>
</dependency>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-zookeeper</artifactId>
</dependency>
- Configuring the discovery strategy by indicating ZooKeeper’s url, the cluster configuration directory and the cluster name. In this case, we are using an XML file, but this can also be done via software.
<network>
<join>
<multicast enabled="false"/>
<tcp-ip enabled="false" />
<aws enabled="false"/>
<discovery-strategies>
<discovery-strategy enabled="true"
class="com.hazelcast.zookeeper.ZookeeperDiscoveryStrategy">
<properties>
<property name="zookeeper_url">
${zookeeper.url}
</property>
<property name="zookeeper_path">
/discovery/hazelcast
</property>
<property name="group">
onesaitplatform_cache
</property>
</properties>
</discovery-strategy>
</discovery-strategies>
</join>
</network>
- On startup of the cache-server module, creating the Hazelcast instance from the previous configuration:

With this configuration, by simply scaling the number of cache-server mirrors from CaaS, each new mirror will join the cluster.
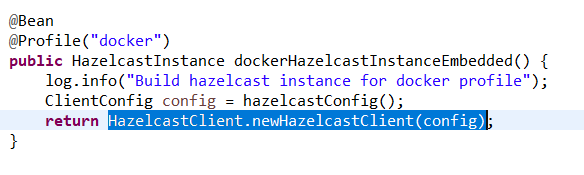
The clients of the cluster (the Platform’s other modules also using Hazelcast) have the same requirements in terms of library and configuration dependencies. The only difference is that, at startup, they will instantiate a client of the cluster (newHazelcastClient) instead of an instance (newHazelcastInstance):
SPI strategy with Kubernetes
Will soon be added to the Platform for installations on Openshift and Rancher 2.
Based on the following Hazelcast SPI driver: https://github.com/hazelcast/hazelcast-kubernetes
It allows to use Kubernetes’ own management services for the discovery of nodes of the cluster.
In this case, each node of the Hazelcast cluster, on startup, uses the Kubernetes API to register and to consult whether there are instances already registered to which to connect to form a cluster or not.
On a technical and programming level, cluster support for Hazelcast with Kubernetes covers the following requirements in the cache-server module:
- Adding ZooKeeper’s SPI dependencies for Hazelcast:
<dependencies>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-kubernetes</artifactId>
</dependency>
</dependencies>
- Create the connection settings. In this case, we decided to do it by software using a Spring bean. In the case of Kubernetes, you must specify:
- Namespace of the Kubernetes cluster where the Hazelcast cluster will be deployed.
- Service-Name with the identifier that the cache-server will have in the namespace where it will be deployed.

Once again, when the cache-server is deployed in the CaaS, scaling the number of mirrors, each new mirror will join the cluster.
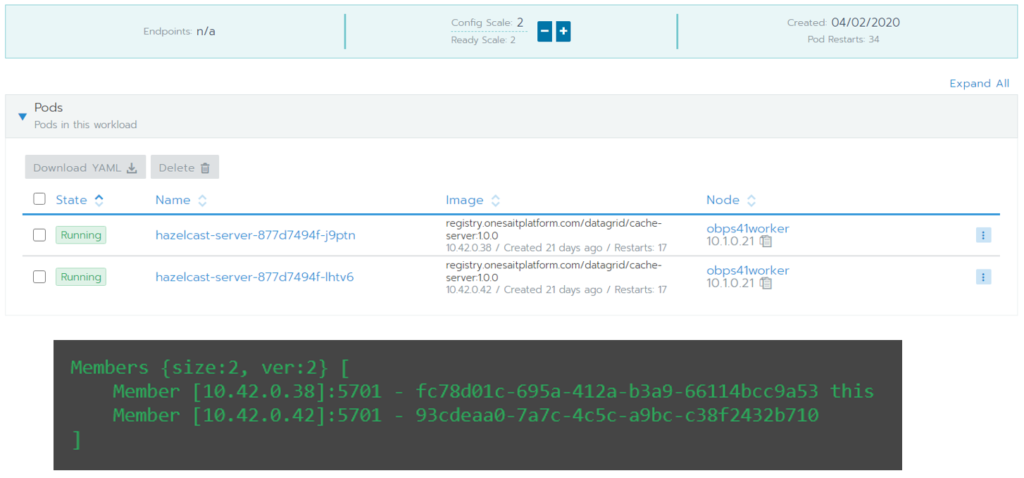
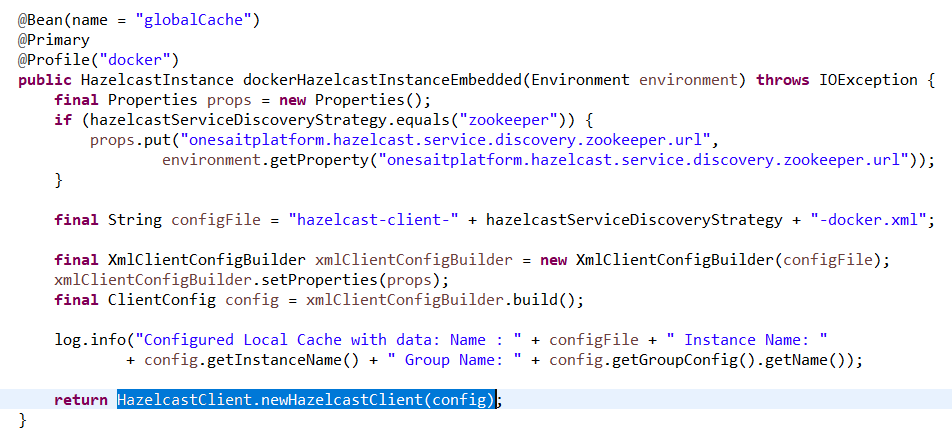
The clients of the cluster (the Platform’s other modules also using Hazelcast) have the same requirements in terms of library and configuration dependencies. The only difference is that, at startup, they will instantiate a client of the cluster (newHazelcastClient) instead of an instance (newHazelcastInstance):