Despliegue de Hazelcast en clúster
Como ya comentamos en una entrada anterior, Hazelcast juega un rol muy importante en la Onesait Platform proporcionando soporte para determinadas funcionalidades.
Una de las principales características de Hazelcast es el escalado dinámico, de manera que es posible añadir o eliminar nodos del cluster en caliente y de forma transparente, Hazelcast asigna particiones y balancea los datos y tareas entre los diferentes miembros del cluster.
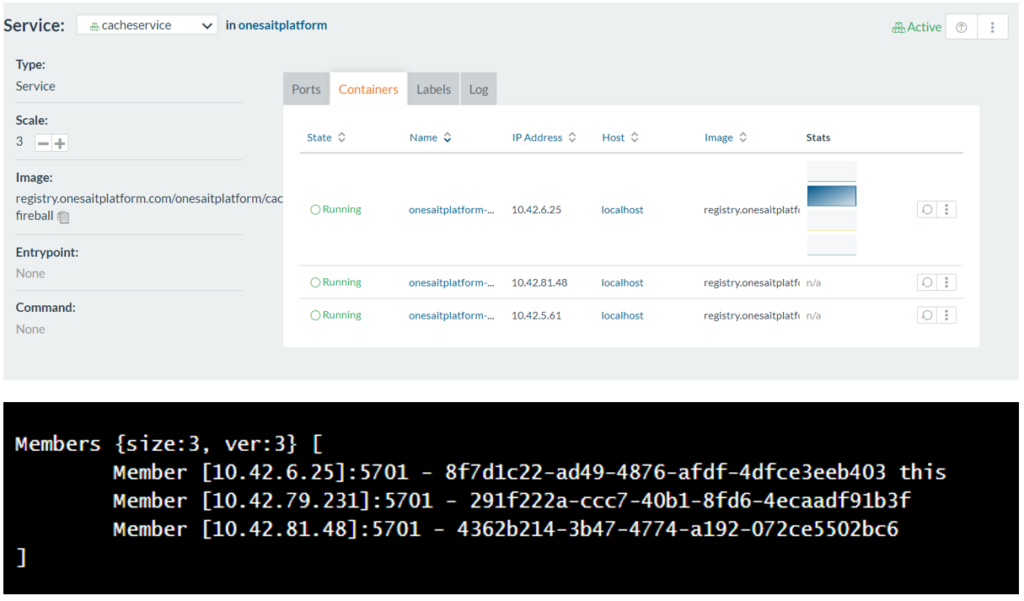
En el cluster de Hazelcast de la Onesait Platform, los diferentes miembros del clúster son contenedores en el CaaS (Rancher u Openshift), lo que necesita de una estrategia de descubrimiento entre nodos dentro de la red de contenedores.
Existen diferentes estrategias de descubrimiento para Hazelcast. Onesait Platform utiliza o prevé utilizar las siguientes:
Estrategia SPI con ZooKeeper
Utilizado por la Onesait Platform sobre Rancher 1.6.
Se basa en el siguiente driver SPI de Hazelcast: https://github.com/hazelcast/hazelcast-zookeeper
ZooKeeper proporciona un sistema centralizado de configuración y de directorio, para aplicaciones distribuidas. Permite que cada instancia de un ecosistema distribuido registre en un directorio la configuración necesaria para interactuar con el resto de instancias de su ecosistema. Utilizando el SPI de ZooKeeper, cada nodo del clúster de Hazelcast, al arrancar se registrará en el directorio correspondiente en ZooKeeper y consultará si existen instancias ya registradas. En caso de existir recuperará sus datos de conexión y se unirá a ellas para formar un clúster.
A nivel de técnico y de programación, el soporte de cluster para Hazelcast con ZooKeeper abarca los siguientes requisitos en el módulo cache-server:
- Disponer en la instalación de una instancia de ZooKeeper:

- Añadir las dependencias del SPI de ZooKeeper para Hazelcast:
<!-- Zookeeper SPI -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-test</artifactId>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-x-discovery</artifactId>
</dependency>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-zookeeper</artifactId>
</dependency>
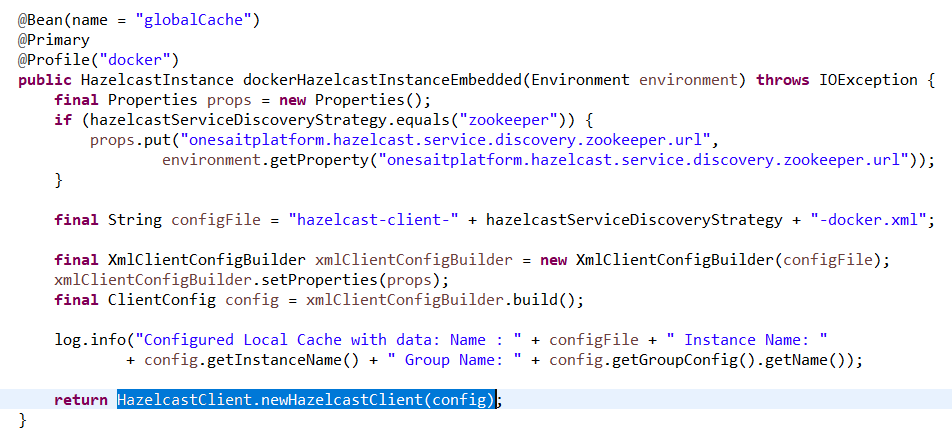
- Configurar la estrategia de descubrimiento indicando la url de ZooKeeper, el directorio de configuración del cluster y el nombre del cluster. En este caso utilizaremos un fichero XML, pero también se podría hacer programática.
<network>
<join>
<multicast enabled="false"/>
<tcp-ip enabled="false" />
<aws enabled="false"/>
<discovery-strategies>
<discovery-strategy enabled="true"
class="com.hazelcast.zookeeper.ZookeeperDiscoveryStrategy">
<properties>
<property name="zookeeper_url">
${zookeeper.url}
</property>
<property name="zookeeper_path">
/discovery/hazelcast
</property>
<property name="group">
onesaitplatform_cache
</property>
</properties>
</discovery-strategy>
</discovery-strategies>
</join>
</network>
- En el arranque del módulo cache-server crear la instancia de Hazelcast a partir de la configuración anterior:

Con esta configuración, simplemente escalando el número de réplicas del cache-server desde el CaaS, cada nueva réplica se irá uniendo al cluster.
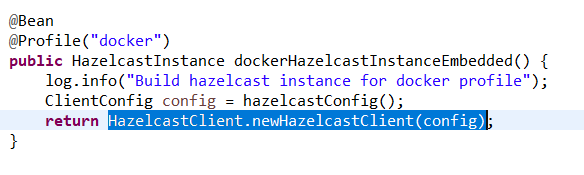
Los clientes del clúster (resto de módulos de la Plataforma que utilizan Hazelcast) tienen los mismos requisitos en cuanto a dependencias de librerías y de configuración. La única diferencia es que en el arranque instanciarán un cliente del cluster (newHazelcastClient) en vez de una instancia (newHazelcastInstance):
Estrategia SPI con Kubernetes
Se incorporará próximamente a la Plataforma para instalaciones sobre Openshift y Rancher 2.
Se basa en el siguiente driver SPI de Hazelcast: https://github.com/hazelcast/hazelcast-kubernetes
Permite utilizar los propios servicios de gestión Kubernetes para el descubrimiento de nodos del cluster.
En este caso, cada nodo del cluster de Hazelcast, al arrancar utiliza el API de Kubernetes para registrarse y consultar si existen instancias ya registradas a las que conectarse para formar un cluster.
A nivel de técnico y de programación, el soporte de cluster para Hazelcast con Kubernetes abarca los siguientes requisitos en el módulo cache-server:
- Añadir las dependencias del SPI de ZooKeeper para Hazelcast:
<dependencies>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-kubernetes</artifactId>
</dependency>
</dependencies>
- Crear la configuración de conexión. En este caso se opta por hacerlo de forma programática mediante un Bean de Spring. En el caso de kubernetes, hay que indicar:
- Namespace del Cluster de kubernetes donde se va a desplegar el cluster Hazelcast.
- Service-Name con el identificador que va a tener el cache-server en el namespace donde se despliegue.

De nuevo, una vez desplegado el cache-server en el CaaS, escalando el número de réplicas, cada nueva réplica se irá uniendo al cluster.
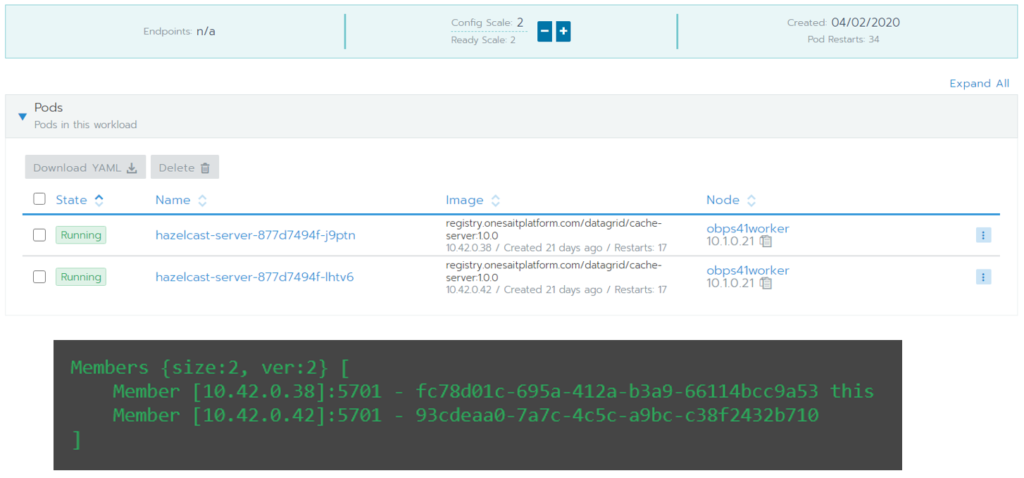
Los clientes del clúster (resto de módulos de la plataforma que utilizan Hazelcast) tienen los mismos requisitos en cuanto a dependencia de la librería de kubernetes y de configuración. La única diferencia de nuevo, es que en el arranque instanciarán un cliente del clúster (newHazelcastClient) en vez de una instancia (newHazelcastInstance):