
Trabajando con un Data Lake en la Onesait Platform (parte 5)
Todo camino llega a su fin, y terminamos nuestra serie sobre Data Lake y la Onesait Platform.
Si recordamos, las semanas pasadas hemos aprendido lo que es un Data Lake y los beneficios que nos aporta, en qué se diferencia de un Data Warehouse, qué tipos de Data Lakes existen, cómo se relacionan con la nube, y hoy por fin vamos a ver cómo le damos soporte en la Onesait Platform.
Soporte Data Lake en Onesait Platform: Data Fabric
El uso de Onesait Platform como plataforma tecnológica para el montaje de un Data Lake es uno de los casos de uso de plataformas tradicionales, donde la Plataforma tiene numerosas referencias desde hace varios años en mercados como Financiero, Utilities, Sanidad, etc.

Con el crecimiento de la Plataforma, ahora mismo podemos decir que en sí soporta el Data Lake a través del concepto de Data Fabric, aunque en este caso nos centraremos en las capacidades Data Lake.
Gestión del Ciclo de vida de la información en la Plataforma
Empecemos por ver cuál es el flujo típico que sigue la información en la Plataforma en un ámbito Data Lake, desde la ingesta y procesamiento de los datos, su almacenamiento, la analítica que puedo realizar sobre ellos y finalmente la publicación hacia el exterior de estos.
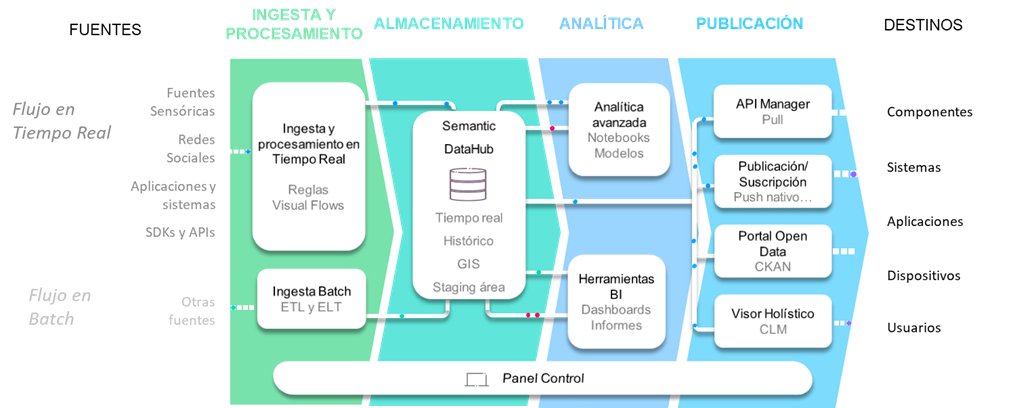
A continuación, vamos a explicar el flujo digital de información citado anteriormente, que comunica desde los productores de datos hasta los consumidores de información a través de la Plataforma.
Ingesta y procesamiento
La solución propuesta permite:
- Real Time Flow: la ingesta de información de fuentes de datos en tiempo real de prácticamente cualquier tipo de naturaleza, desde dispositivos hasta sistemas de gestión pasando por redes sociales, APIS, etc.
- Batch Flow: la ingesta proveniente de fuentes más genéricas que se obtiene mediante procesos de extracción, transformación y carga en modo batch (no tiempo real) accede a la solución a través del módulo de carga masiva de información (ETL).
Almacenamiento
Una vez ingestada y procesada, la información típicamente se almacena en la Plataforma, en lo que denominamos Semantic DataHub, el core del Data Lake. Este componente está soportado por una serie de repositorios expuestos hacia el resto de las capas, que ocultan su infraestructura tecnológica subyacente a los módulos que acceden a su información.

De esta manera, en función de los requerimientos de cada proyecto (volúmenes de información en tiempo real e histórico, accesos mayoritariamente de lectura o escritura, mayor cantidad de procesos analíticos, tecnologías previamente existentes en los clientes, etc.) se provee la infraestructura más adecuada.
Se soportan entre otros estos repositorios:
- Base de datos en Tiempo Real (RealTimeDB): pensada para soportar un gran volumen de inserciones y consultas online de forma muy eficiente. La Plataforma abstrae de la tecnología subyacente permitiendo usar BD documentales como Mongo, BD Time Series, relacionales, etc.
- Base de datos Histórica y Analítica (HistoricalDB): este store está pensado para almacenar toda la información que ya no forma parte del mundo online (por ejemplo, información de años anteriores que ya no se consulta) y para soportar procesos analíticos que extraen conocimiento de estos datos (algoritmos).
- Área de Staging: permite almacenar ficheros en crudo y sin procesar por la Plataforma, para su posterior ingesta. La Plataforma permite usar HDFS, GridFS o MinIO como almacenamiento.
- Base de datos GIS: es la base de datos que almacena información con componente geoespacial, y puede usarse una de las bases ya existentes, integrar con base de datos de la organización o montar una nueva instancia.
Analítica
Toda la información almacenada en la Plataforma puede analizarse con una visión holística; es decir, permitiendo el cruce de información a lo largo del tiempo, entre sistemas verticales e incluso con datos más estáticos que se hayan alimentado previamente a la Plataforma (información de catastro, renta por barrio, tipología de cada zona, etc.).

Para esto, la Plataforma ofrece un módulo denominado Notebooks que permite a los equipos especializados el desarrollo de algoritmos y modelos IA/ML con los lenguajes más usados en este ámbito (Spark, Python, Tensorflow, etc.), desde el entorno web suministrado por la Plataforma. Estos modelos pueden publicarse de forma sencilla para ser consumidos por el resto de capas y sistemas externos.
Publicación
La Plataforma ofrece capacidades para poner a disposición de usuarios, partners, aplicaciones y verticales toda la información previamente almacenada. Para esto ofrece diversos mecanismos, entre ellos:
- API Manager: publicando la información en forma de APIs REST gestionables de manera individual y con capacidades de monitorización de su consumo. Esto permite a la Plataforma interactuar con todo tipo de sistemas y dispositivos a través de los canales digitales más típicos, como son la Web, smartphones, tablets y otros sistemas capaces de consumir la información a través del protocolo REST.
- Portal Open Data: La plataforma permite publicar de forma muy sencilla la información que maneja en el Portal Open Data que integra.
Capa de soporte: Panel de Control
Toda la configuración de los módulos previamente descritos se realiza a través de un único panel de control web, que centraliza la gestión de la Plataforma al completo, desde la modelización de la información hasta la asignación de permisos de los usuarios además de gestionar las reglas y algoritmos de manipulación de información y hasta de configurar en modo web los cuadros de mando (Dashboards) de explotación de la información almacenada.
Capacidades de Onesait Platform en ámbito Data Lake
Almacenamiento Multi-store
Como hemos dicho, el Semantic Data Hub permite almacenar la información gestionada por la Plataforma en diferentes repositorios en función del uso que se hará de ellos, tratándolos como si todos estuvieran en el mismo repositorio ofreciendo un interfaz SQL para acceder a estos independiente de su repositorio.
Podemos encontrar más información sobre este módulo en este artículo del Portal de Desarrollo. En el ámbito Data Lake, la Plataforma soporta tecnologías como:
- HDFS, para el almacenamiento en formato crudo sobre una instancia Hadoop, accesible además con la seguridad de plataforma a través del componente File Manager de la Plataforma.
- HIVE e Impala, para el tratamiento de los datos almacenados en HDFS como un Data Warehouse SQL.
- MinIO+Presto, como alternativa al uso de HDFS y HIVE sobre una infraestructura Kubernetes, evitando los grandes problemas de Hadoop (complejidad, reducción de costes).
- MongoDB, como base NoSQL muy adecuada para almacenamiento de datos semiestructurados en JSON, como por ejemplo medidas.
- Amazon DocumentDB, que es un servicio de base de datos documental de Amazon, escalable, de alta disponibilidad y totalmente gestionado que es totalmente compatible con la API y el funcionamiento de MongoDB.
- Elasticsearch, para el almacenamiento de grandes volúmenes de datos sobre los que requiera hacer búsquedas textuales, como pudieran ser registros.
- TimescaleDB. para almacenamiento escalable de datos Time Series.
- Y otras muchas más, como CosmosDB o AuroraDB.
Seguridad
En una organización, los usuarios de diferentes departamentos (potencialmente dispersos por todo el mundo) deben tener acceso flexible a los datos del Data Lake desde cualquier lugar.
Esto aumenta la reutilización del contenido y ayuda a la organización a recopilar más fácilmente los datos necesarios para impulsar las decisiones empresariales, pero a su vez hace más importante la seguridad para que cada usuario sólo pueda acceder a ciertos datos.

La Plataforma gestiona de forma unificada el acceso a estos datos (y a su procesamiento) de forma independiente a donde estén almacenados. Se pueden establecer políticas de seguridad por usuario y por rol, de modo que estos usuarios o roles puedan acceder sólo en modo consulta a un conjunto concreto de datos (Entidad), a un subconjunto (sólo los datos de una Entidad para un país concreto) o que puedan acceder en modo consulta a unos y en modo escritura a otros.
Podemos encontrar más información sobre seguridad en la Plataforma en este artículo del Portal de Desarrollo.
Ingesta y procesamiento sobre los datos
La Plataforma ofrece el componente DataFlow, que permite definir y desplegar de forma visual desde el propio Control Panel de la Plataforma flujos de ingesta o publicaciones, tanto en streaming (escucha de redes sociales) como en batch (carga de un fichero de un FTP cada X tiempo).
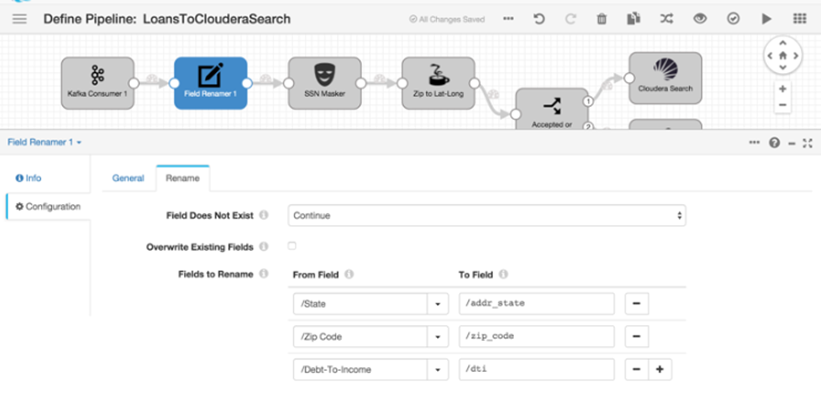
Ofrece una librería de componentes muy amplia, que incluye conectores Big Data con las principales tecnologías Big Data, como podemos ver:
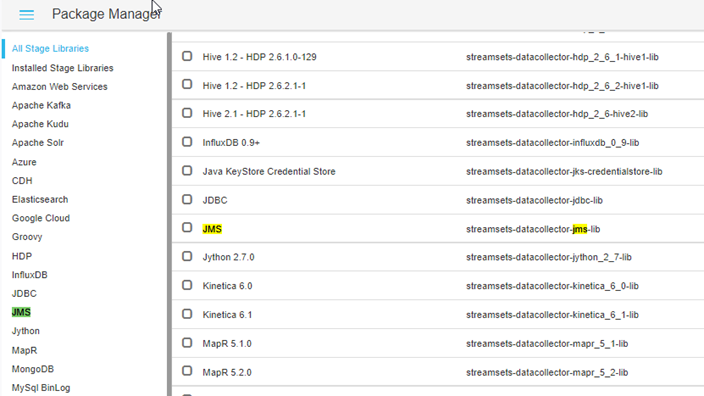
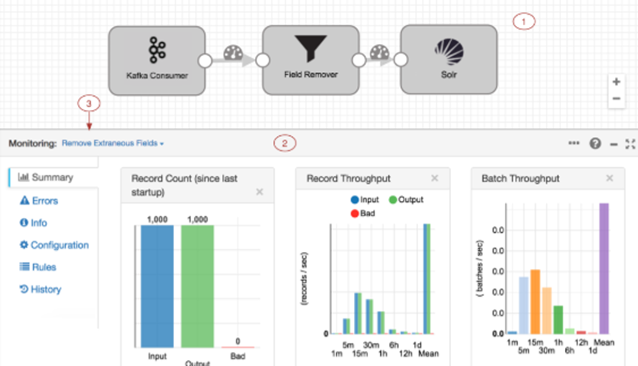
El DataFlow puede distribuir su carga de trabajo por los Workers del clúster Hadoop, además se integra con buses de tipo Kafka para procesamiento en Near Real Time. La Plataforma también despliega un clúster Kafka:
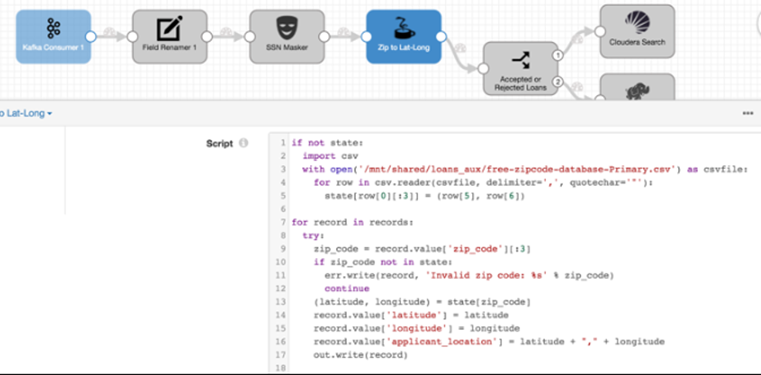
Analítica de los datos
El componente Notebooks Engine provee a los científicos de datos de un entorno compartido web y multiusuario en el que elaborar modelos de análisis de la información almacenada en la Plataforma (los denominados Notebooks). Estos modelos pueden de todo tipo: no solo descriptivos, también predictivos y prescriptivos permitiendo realizar, de manera interactiva, analítica sobre datos de fuentes muy variadas, incluidas las fuentes de datos de la Plataforma.
Los Notebooks se gestionan desde el propio Control Panel de la Plataforma, y pueden por tanto compartirse con otros usuarios (a nivel de edición, ejecución, vista):
Este módulo posee la capacidad de combinar código de varios lenguajes dentro de un mismo Notebook (utilizando intérpretes diferentes en cada párrafo de código), algunos de los lenguajes que soporta son: Python, R, Scala, SparkSQL, Hive, Shell o Scala.
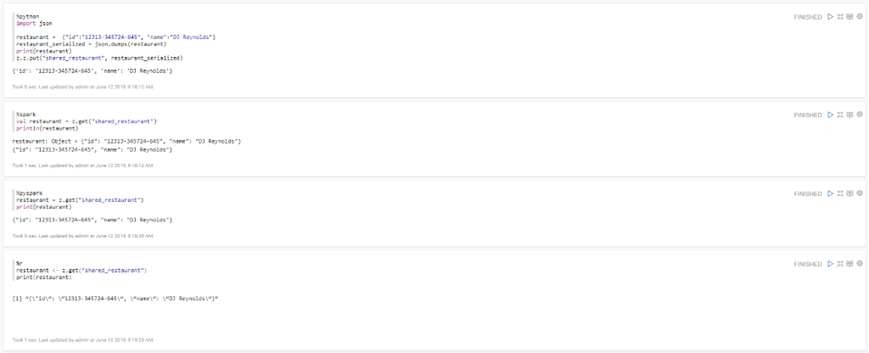
También permite realizar cargas de archivos a HDFS, cargar de datos en tablas HIVE, lanzar consultas o realizar un proceso complejo de Machine Learning (ML) mediante las librerías de MLlib de Spark, R o Python.
¿Qué os parece? ¿Sabíais de las capacidades que tenía la Onesait Platform para trabajar con Data Lakes y cómo lo gestiona todo? Seguro que con todo lo que hemos visto estas semansa, estaréis deseando probarlo por vosotros mismos.
Por tanto, os animamos a que os registréis (si no lo habéis hecho ya) en CloudLab, el entorno de pruebas en la nube de la Onesait Platform. Completamente gratuito, podréis probar el potencial de la Plataforma en dos clics (hasta tenemos una guía de primeros pasos).
Esperamos que os haya gustado la serie, y si os surge alguna duda, por favor dejadnos un comentario.
Imagen de encabezado de Philipp Katzenberger en Unsplash

