Integración de PrestoDB como motor de consultas multi-repositorio
Como recordaréis, en la release 3.1.0 de Onesait Plataform integramos Presto+MinIO como soporte para el almacenamiento tipo DataLake para escenarios de migración desde Hadoop.
Pues en esta release, estamos trabajando para soportar Presto como motor de consultas SQL multirepositorio, lo que nos va a permitir hacer consultas analíticas sobre todas las Entidades de la Plataforma independientemente del repositorio donde estén almacenadas. Esto nos va a permitir, por ejemplo, hacer JOINs entre un PostgreSQLy un MongoDB, o entre un MinIO y un Oracle.
¿Cómo lo soportaremos en la Plataforma?
Por un lado, vamos a poder crear un nuevo tipo de Entidad denominada como «Presto Entity»:
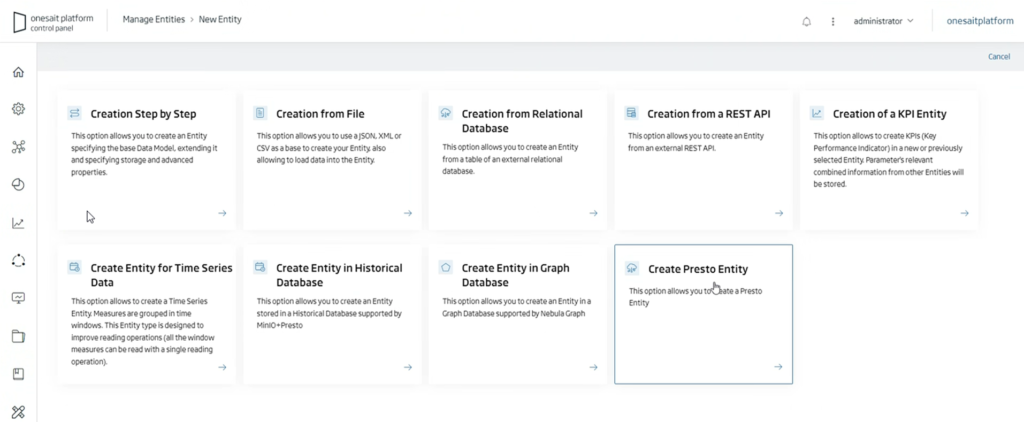
Esto va a permitir a los usuarios conectarse a los diferentes catálogos dados de alta en Presto por el administrador de la Plataforma creando entidades «Presto»:
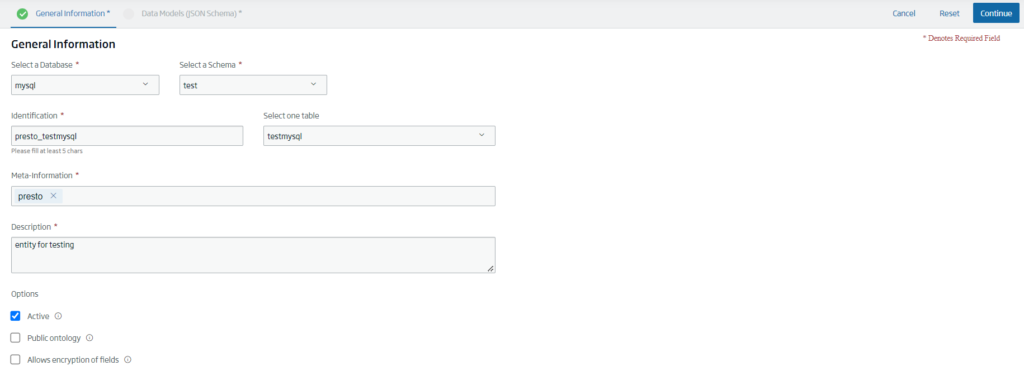
Una vez creadas estas entidades Presto, vamos a poder hacer JOINS entre ellas de forma transparente al repositorio:
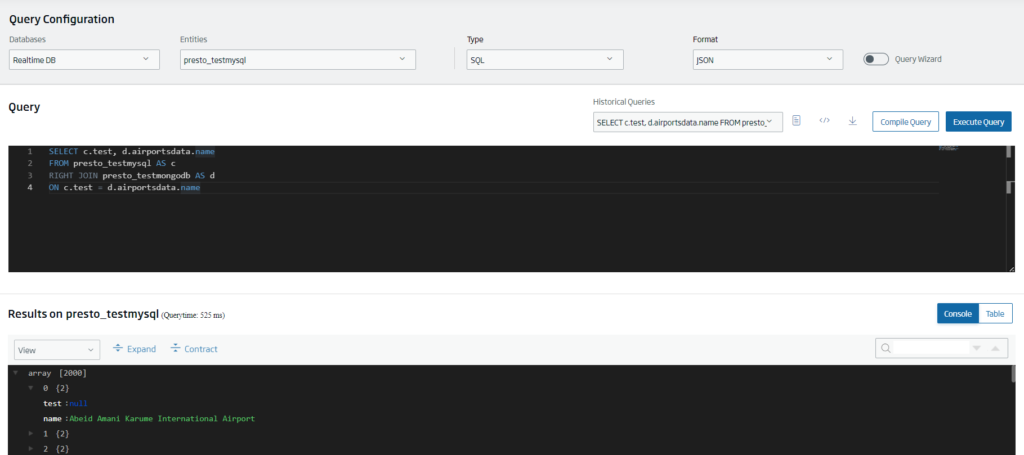
Estas entidades Presto se manejan como el resto de Entidades de la Plataforma, pudiendo crear Dashboards sobre ellas, ingestar datos, publicarlas como API REST, etc.

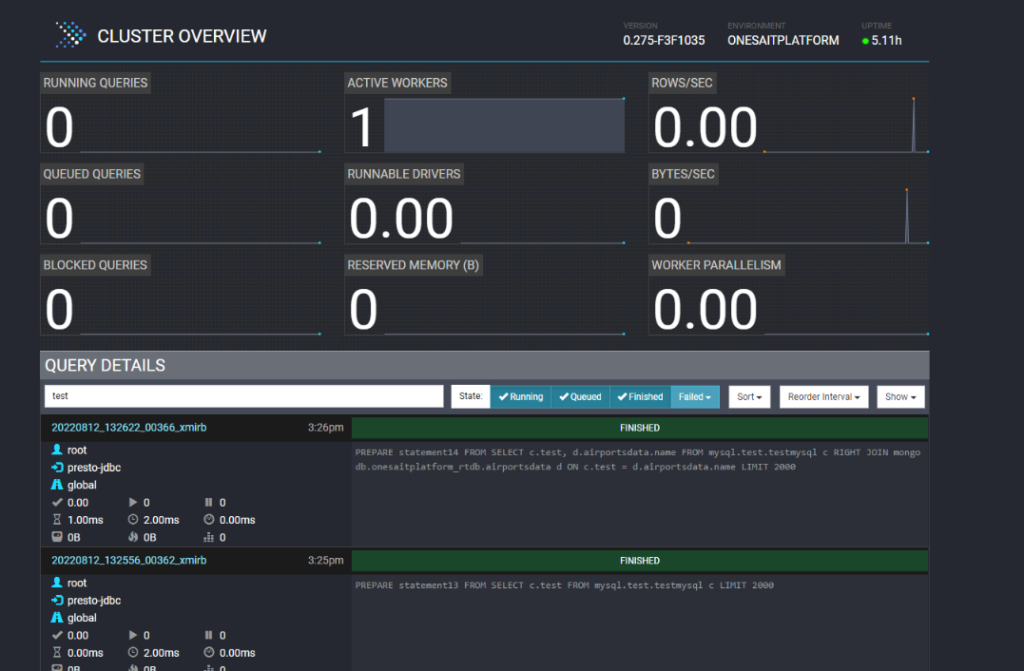
También vamos a integrar el Presto UI, el cual será accesible para usuarios administradores y les va a permitir ver las consultas ejecutadas sobre Presto:
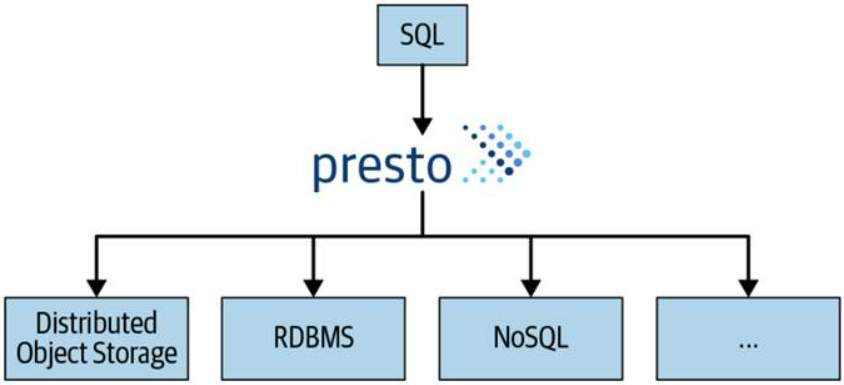
Vale pero, ¿qué es Presto?
PrestoDB es un motor de consultas SQL distribuido como Open Source y construido en Java, pensado para lanzar consultas analíticas interactivas contra un gran número de fuentes de datos (a través de conectores), soportando consultas sobre fuentes de datos que van desde gigabytes hasta petabytes.
Es un motor de consulta ANSI-SQL, permite consultar y manipular datos en cualquier fuente de datos conectada con las mismas sentencias, funciones y operadores SQL.
Como curiosidad, PrestoDB fue creado en 2012 en Facebook, donde inicialmente se pensó para para resolver el problema de la lentitud de HIVE al acceder a un Data Warehouse de 300 PB. Para resolver este problema, se construyó un motor MPP basado en SQL que fuera fácil de usar a partir de los conocimientos existentes, fácil de conectar a cualquier base de datos, almacén o Datalake, y fácil de integrar con cualquier herramienta de BI.
¿Qué vamos a poder hacer?
Presto nos va a permitir consultar los datos sobre su origen, incluyendo entre otros conectores Hive, Cassandra, bases de datos relacionales, Kafka, Kudu, Redis, MongoDB… Una sola consulta de Presto puede combinar datos de múltiples fuentes, lo que permite realizar análisis multi-store. Está enfocado a consultas analíticas que esperan tiempos de respuesta que van desde menos de un segundo hasta minutos.
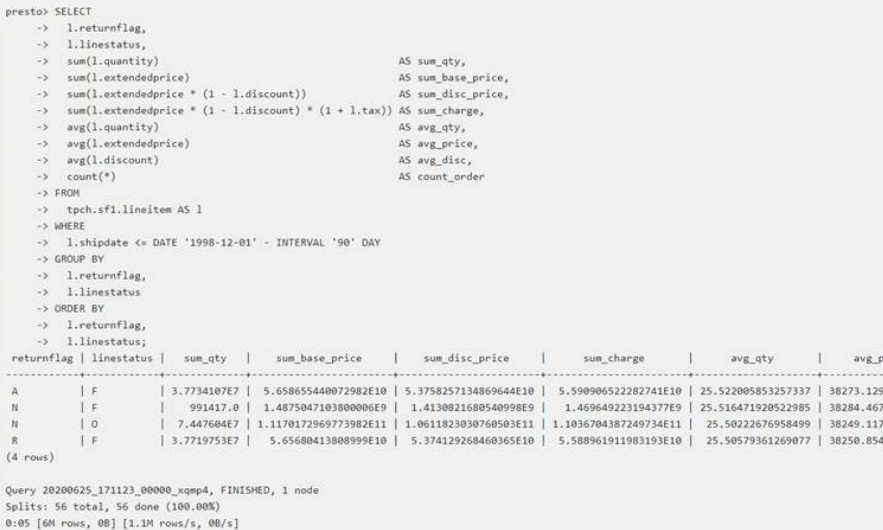
Ofrece una línea de comandos para hacer las consultas:
Conectores
Presto nos ofrece una serie de conectores disponibles para acceder a los datos de diferentes fuentes de datos. En su página de documentación tienen un listado de los conectores disponibles.
Algunos de estos conectores son para: Accumulo, Cassandra, Druid, Elasticsearch, HIVE, JMX, Kafka, Kudu, ficheros locales, MongoDB, MySQL, Oracle, Postgresql, Redis, Redshift, SQL Server, etc.
Driver JDBC
Presto ofrece un driver JDBC que permite acceder a las fuentes de datos subyacentes desde cualquier aplicación que use el driver.

Presto Web UI
Presto proporciona una interfaz web para supervisar y gestionar las consultas. La interfaz web es accesible en el coordinador de Presto a través de HTTP.
El UI nos indicara para cada consulta su estado:
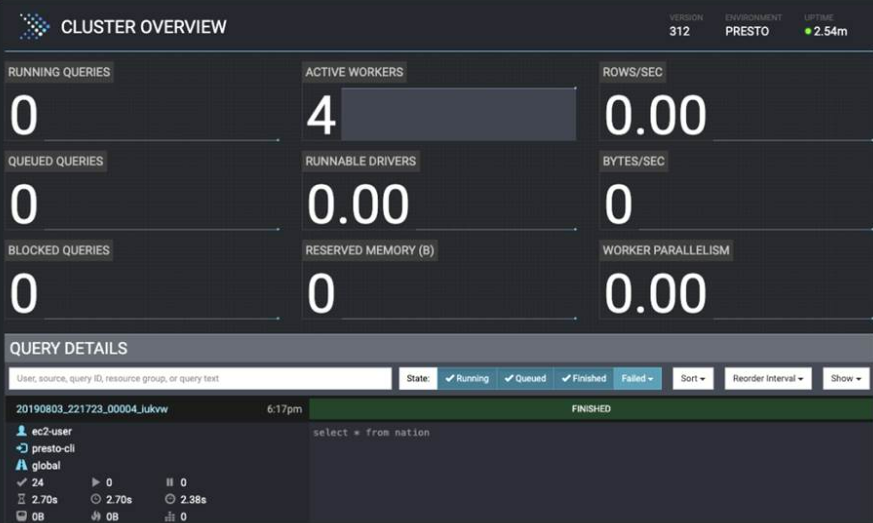
Imagen de cabecera: GitHub Presto.