
Integration of PrestoDB as a multi-repository query engine
As you shall remember, in release 3.1.0 of the Onesait Platform we integrated Presto+MinIO to support DataLake-type storage for migration scenarios from Hadoop.
Como recordaremos, en la release 3.1.0 de Onesait Plataform integramos Presto+MinIO como soporte para el almacenamiento tipo DataLake para escenarios de migración desde Hadoop.
Well, in this release, we are working to support Presto as a multi-repository SQL query engine, which will allow us to make analytical queries on all the Platform Entities, regardless of the repository where they are stored. This will allow us, for example, to do JOINs between a PostgreSQL and a MongoDB, or between a MinIO and an Oracle.
How will we support it on the Platform?
On the one hand, we will be able to create a new type of Entity called «Presto Entity»:
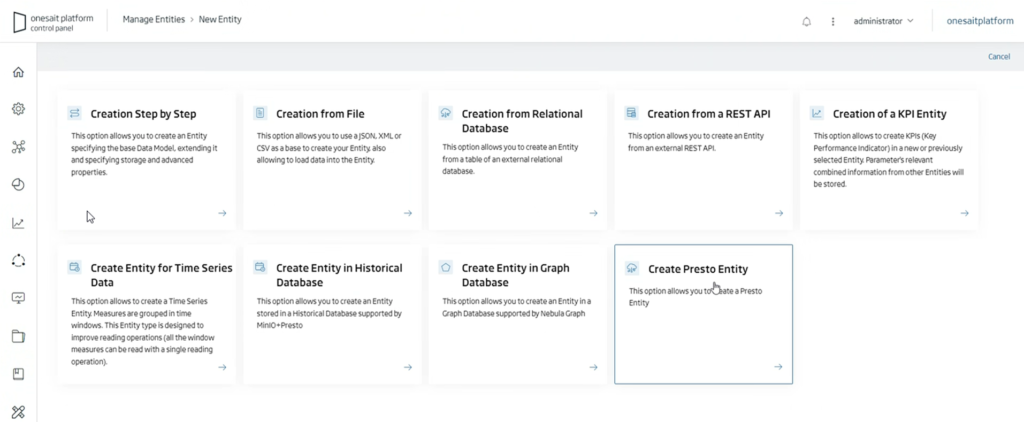
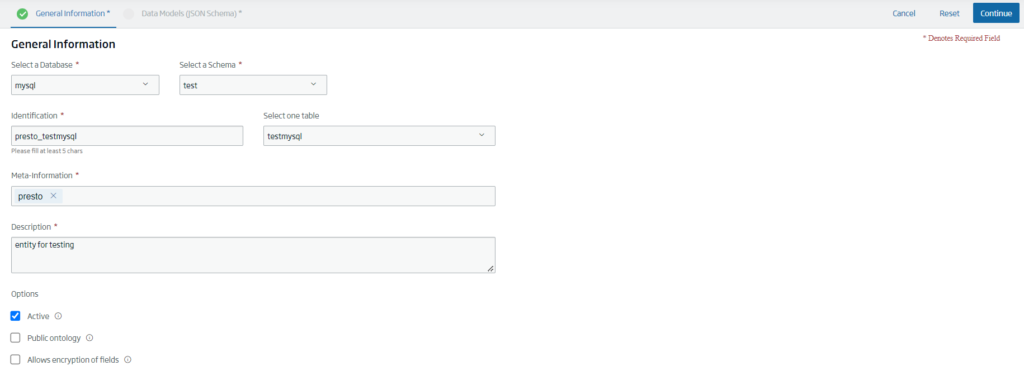
This will allow users to connect to the different catalogs registered in Presto by the Platform administrator, creating «Presto» entities:
Once these Presto entities are created, we will be able to do JOINS between them transparently to the repository:
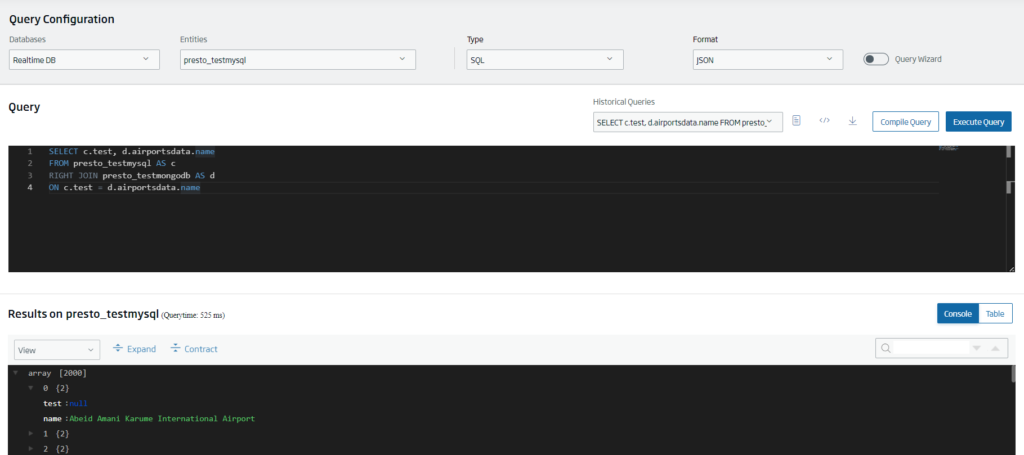
These Presto entities are handled like the rest of the Platform Entities, so you can create Dashboards on them, ingest data, publish them as REST API, etc.

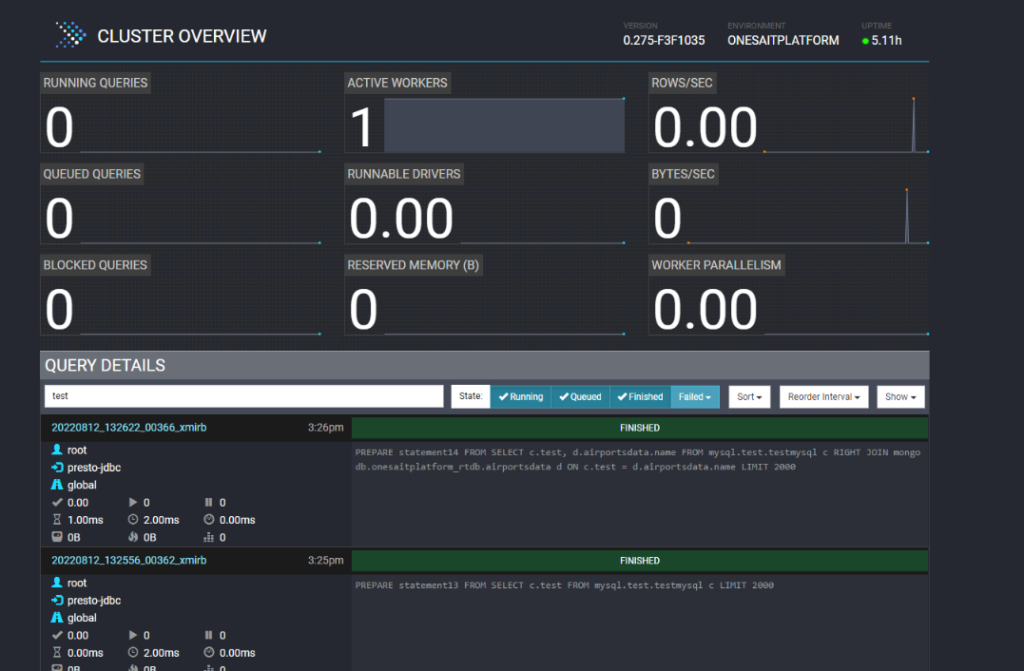
We are also going to integrate the Presto UI, which will be accessible to administrator users and will allow them to see the queries executed on Presto:
Ok but: what is this Presto?
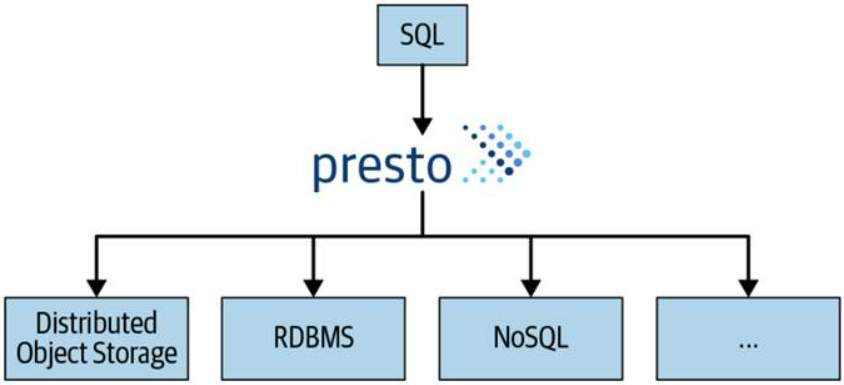
PrestoDB is an open source-distributed SQL query engine built in Java, designed to launch interactive analytical queries against a large number of data sources (through connectors), supporting queries on data sources ranging from gigabytes to petabytes.
It is an ANSI-SQL query engine, allowing you to query and manipulate data in any connected data source with the same SQL statements, functions, and operators.
As a bit of trivia: PrestoDB was created in 2012 by Facebook, where it was initially intended to solve the slow problem of HIVE when accessing a 300-PB data warehouse. To solve this problem, an SQL-based MPP engine was built, designed so that it was easy to use from existing knowledge, easy to connect to any database, warehouse, or datalake, and easy to integrate with any BI tool.
What are we going to be able to do?
Presto will allow us to query the data about its origin, including among other connectors, Hive, Cassandra, Kafka, relational databases, Kudu, Redis, MongoDB… One single Presto query can combine data from multiple sources, allowing for multi-store analytics. It is focused on analytical queries that expect response times ranging from less than a second, to minutes.
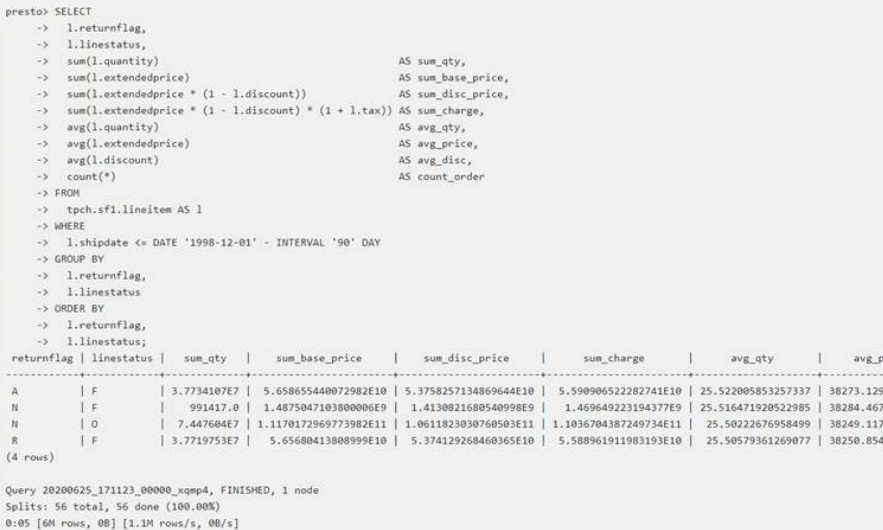
It offers a command line to make the queries:
Connectors
Presto offers us a number of connectors, available to access data from different data sources. They have a list of available connectors in their documentation page.
Some of these connectors are for: Accumulo, Cassandra, Druid, Elasticsearch, HIVE, JMX, Kafka, Kudu, local files, MongoDB, MySQL, Oracle, Postgresql, Redis, Redshift, SQL Server, etc.
JDBC Driver
Presto offers a JDBC driver that allows access to the underlying data sources from any application that uses the driver.

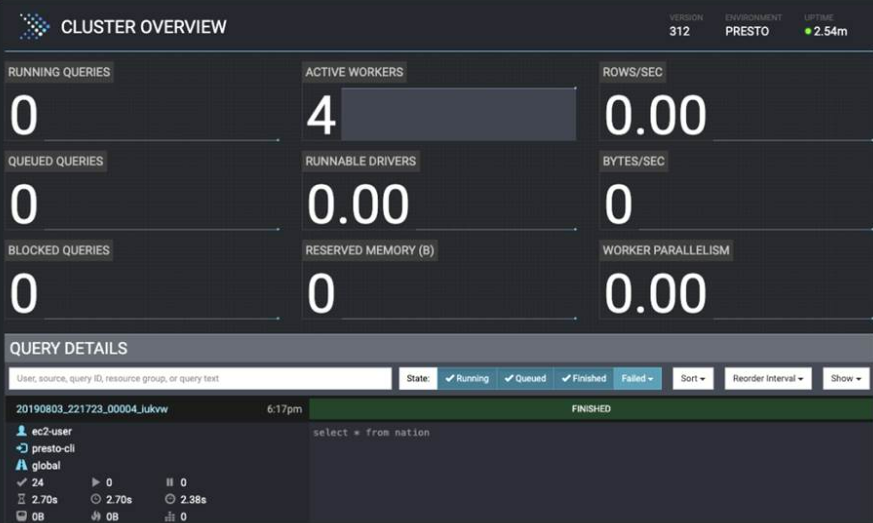
Presto Web UI
Presto provides a web interface to monitor and manage queries. The web interface is accessible in the Presto coordinator through HTTP.
The UI will indicate its status for each query:
Header image: GitHub Presto.


