
Onesait Platform Release 3.1.0-kickoff
The second quarter of 2021 is over, and with it comes a new iteration of Onesait Platform Release 3.1, full of new features and improvements.
The Platform Community has decided to call this version «KickOff», the most voted name in the poll we conducted a couple of weeks ago to choose the name. As usual, the choice of the name follows our established versioning policy.
For this release, we have completed what we had in mind to carry out in the Roadmap throughout this quarter:
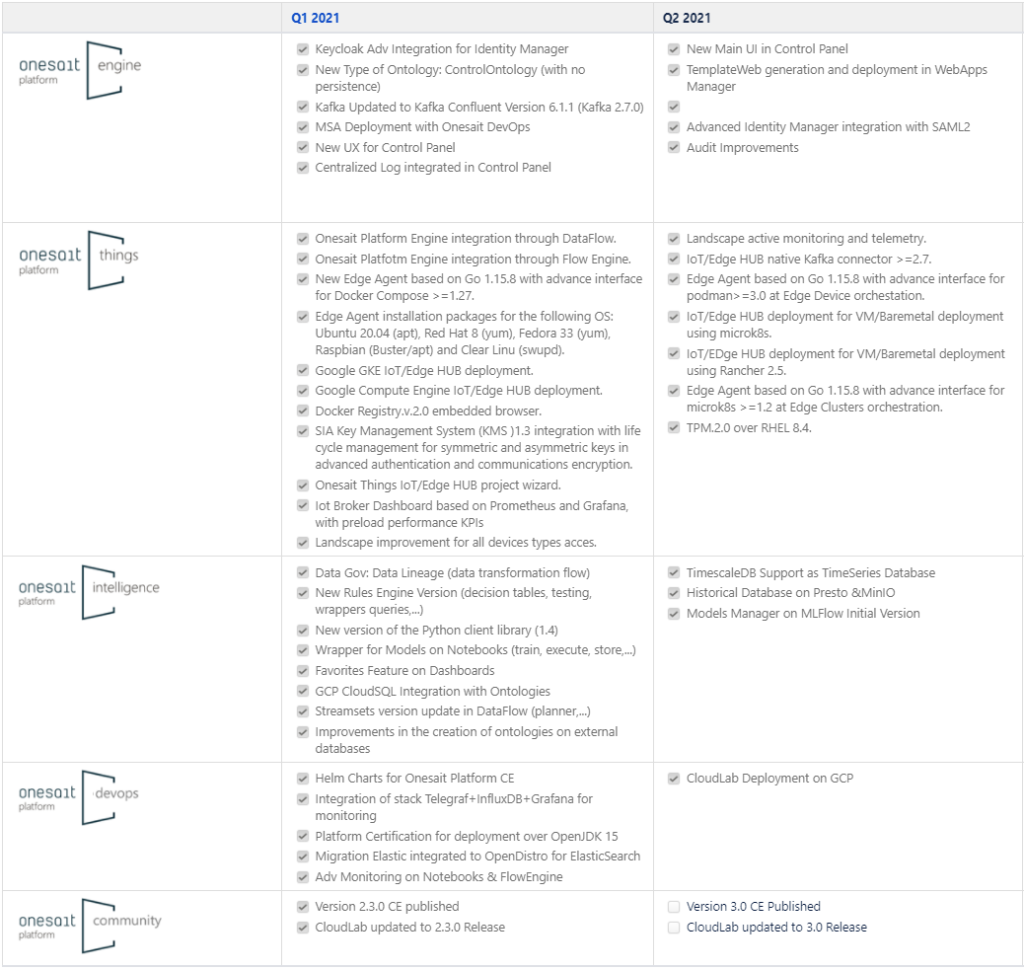
Having said that, let’s see what new and interesting features we have in this new version.
Engine
This distribution of the Platform supports the development of microservices and all kinds of applications. To help in this type of development, the Platform allows a visual development with a LowCode approach incorporating a centralized web console that supports administration, configuration, development and deployment.
In this version, we have incorporated the following features:
Renaming of the Ontology concept to Entity.
Until now, in the Platform, we used the name Ontology to refer to the Entities managed by the Platform, a name that came from the origins of the Platform in the European R&D environment. As you have told us on several occasions, the term was sometimes confusing, so from this version, in the Control Panel, you will see that we now refer to the Platform Entities:
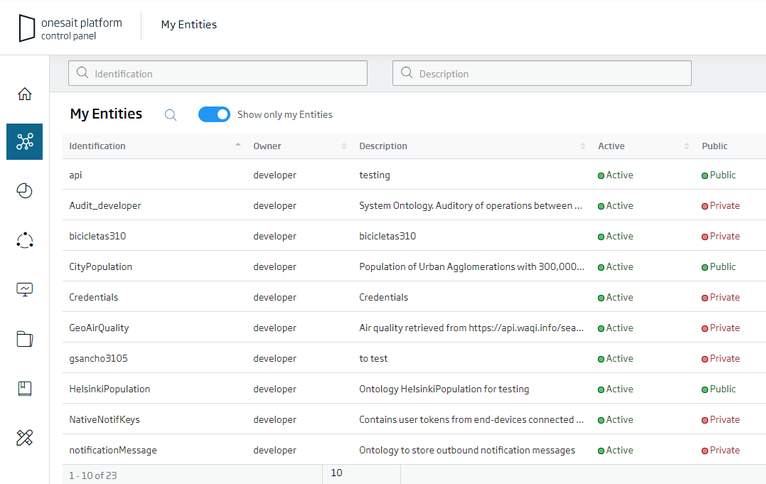
New «Home» user interface of the Control Panel
This new functionality gives administrator users relevant information about the overall status of the Platform. Using the metrics provided by Prometheus, the new user interface allows the user to have a unified view of the status and performance of each of the components that are deployed in their installation.
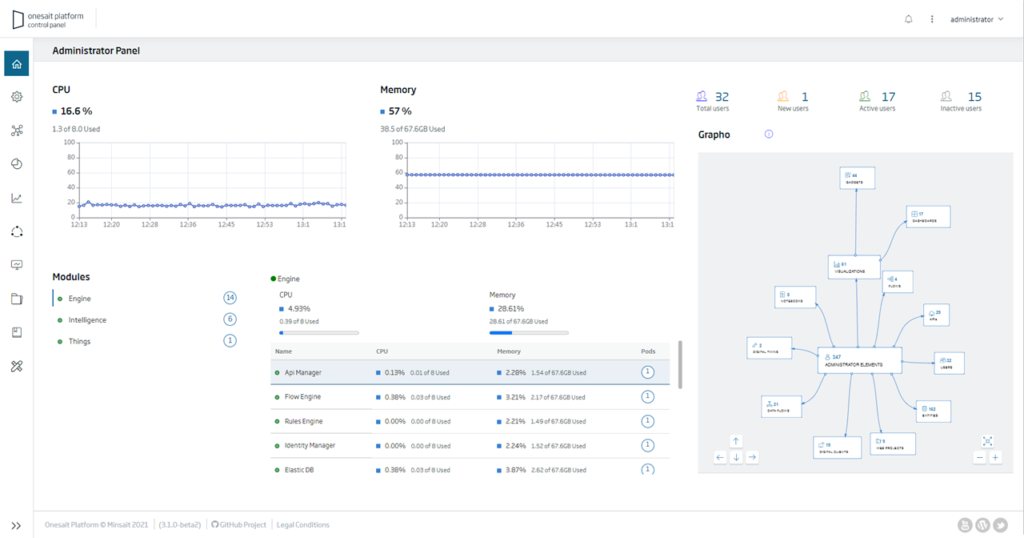
You can find more information about this in this guide in the Developer Portal.
Web Project Creation
Up until this version, the creation of web projects in Control Panel only allowed you to upload a file where the user attached all the files that will be needed for the operation of your web project. With this new improvement, the users can decide if they want to use the web template provided by the Platform as the basis of their web project, which gives them integrated and configurable via JSON login, security, menus, headers, etc.
Entities without ContextData
A new configuration has been added when creating an Entity (formerly Ontology) that allows to enable or disable the option to add the «ContextData» object to the information inserted in the Platform.
This is explained in detail in this article in the Development Portal.
Intelligence
This distribution of the Platform supports the development of systems that use the Platform’s Intelligence capabilities, either with its AI capabilities, ingest from different sources, analytics, visualization, etc.
In this quarter, we have worked on the following new features:
Big Data Storage on Presto + MinIO
Presto is an open-source distributed SQL query engine that allows to launch interactive analytical queries against a large number of data sources, and MinIO is a distributed storage that implements the AWS S3 API. These two technologies, together, allow us to replace Hadoop (HDFS) and Datawarehouse (HIVE) storage services. The use of these two technologies will also allow us to have a more elastic, dynamic and easily manageable solution than with Hadoop (more information).
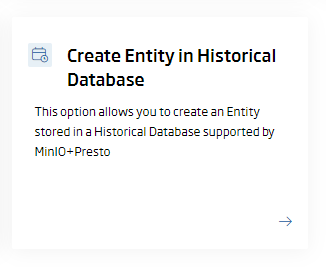
If you are interested in this new functionality, we have created a user guide on how to use this feature.
Machine Learning Lifecycle Management with MLFlow
Aiming to offer new tools to data scientists and make their work more productive, we have integrated MLFlow to help with Machine Learning lifecycle management.
Therefore, now the user with an «Analytics» type role will be able to access this new tool from the new «My ML Lifecycle management» option:
Regarding MLflow, it is an Open Source platform to manage the Machine Learning development lifecycle, including tracking of experiments to record and compare parameters and results (MLflow Tracking), packaging the ML code in a reusable and reproducible way to share with other data scientists and deploy it in production (MLflow Projects), model management and deployment (MLflow Models) and central model repository to collaboratively manage the entire lifecycle of an MLflow model, including model versioning, stage transitions and annotations (MLflow Model Registry).
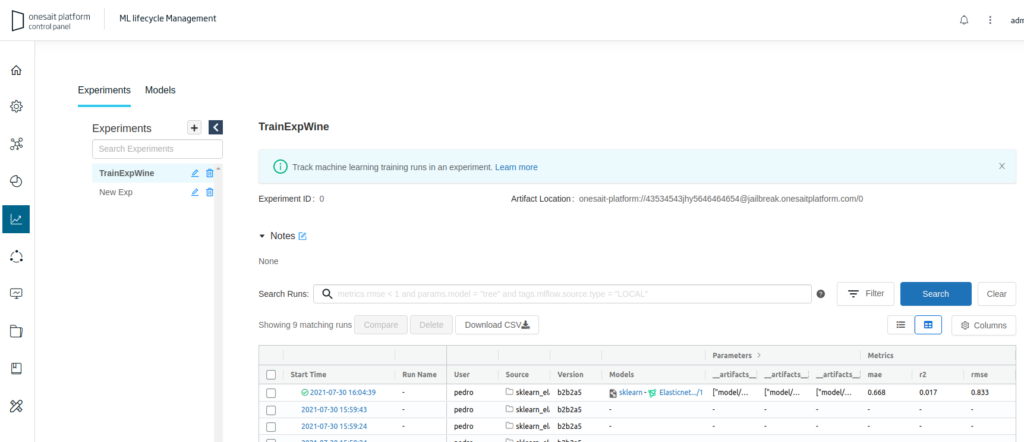
You can use MLFlow from the Notebooks that have already established the Platform as the Tracking Server:
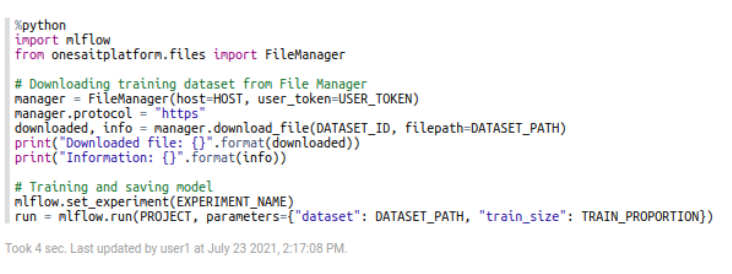
You can also use them from your own code in several languages, simply by setting the URL of our Tracking Server as a variable:
export MLFLOW_TRACKING_URI=https://jailbreak.onesaitplatform.com/controlpanel/mlflow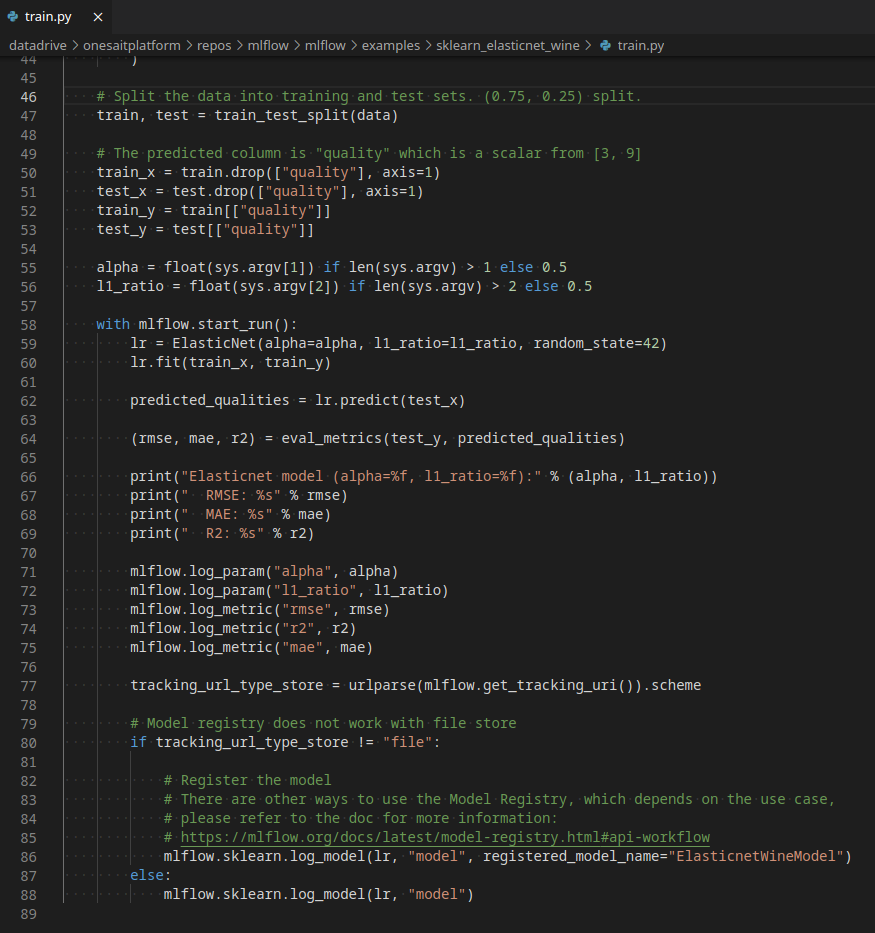
You can find more information about it in this article of the Development Portal: ML Lifecycle Management: MLFlow Platform Integration.
TimescaleDB support as TimeSeries DB on Entities
TimescaleDB is an Open Source database for Time Series storage and analysis with the power and advantages of using SQL. It is built on PostgreSQL, which has the advantage of being able to use the tools of the Postgresql ecosystem. It also includes specific data management capabilities, such as data retention, downsamplings, native compression, data lifecycle management, aggregation policies as well as functions oriented to Time Series analytics, such as window creation, gap filling, LOCF queries, etc. Besides, as it is built on PostgreSQL, it can store your business data in the same database, thus allowing JOINS.
When creating the TimeSeries Entity, you can select TimescaleDB:

From there, you can configure the Timescale usage mode, such as the Chunk time interval, which defines the time window that is taken into account to create the chunks.

We can also define the Window frequency, indicating whether we want the TimeSeries to have discrete intervals when storing the measurements or not:

Another parameter that you can configure is the aggregation functions parameter. In the case of selecting a frequency, you can choose between different aggregation functions (LAST, SUM) to know how to aggregate the data of each signal if more than one record is received for a set of tags and a particular frequency/timestap.

Things
This distribution of the Platform supports the development of IoT systems, both Cloud and Edge.
Throughout the quarter, we made progress on the following points:
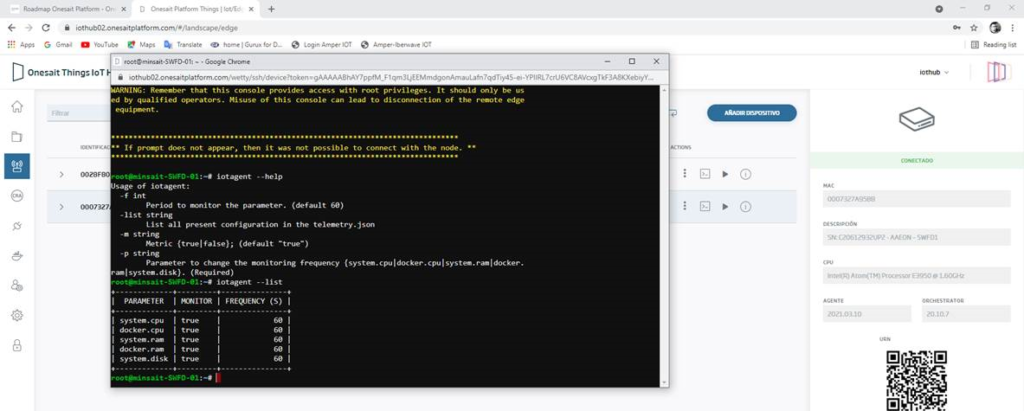
Landscape active monitoring and telemetry
We have added to the IoT/Edge Agent the ability to report through the Control Channel (Device2Cloud Flow) information regarding the use of resources (RAM, CPU and disk) of the corresponding Edge Device by each of the loads deployed on the device. This telemetry is configurable via CLI on the Edge Device itself and with the «iotagent» command.
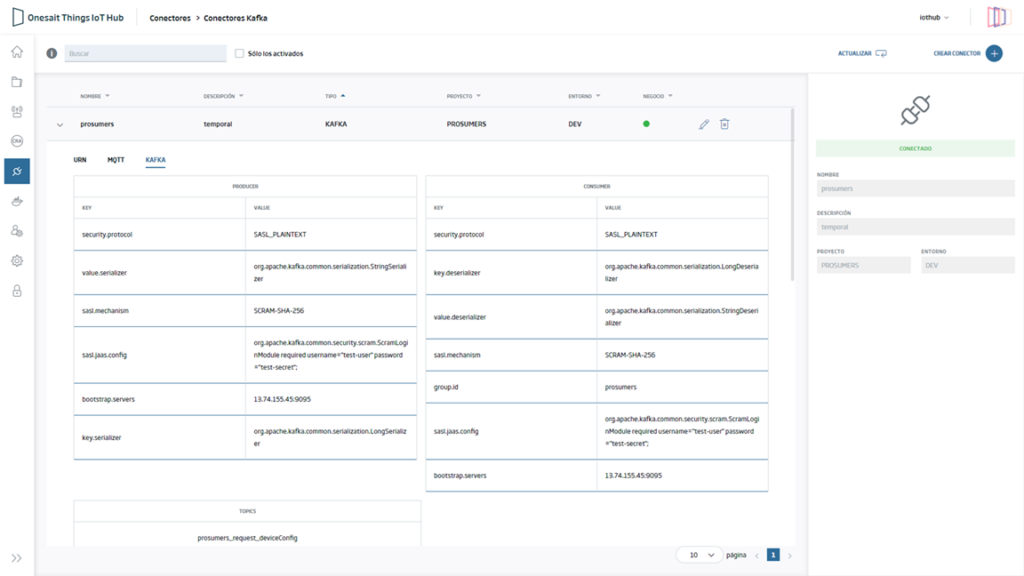
Kafka IoT/Edge HUB Native Connector
Within the connectors section, the creation and deployment of a bi-directional (Producer and Consumer), multi-topical Kafka<->MQTT connector is now available. It allows to easily connect the Business Channel of all types of devices included in the Lanscape. A properties management system allows dynamic configuration of all common Kafka parameters for version >= 2.7.
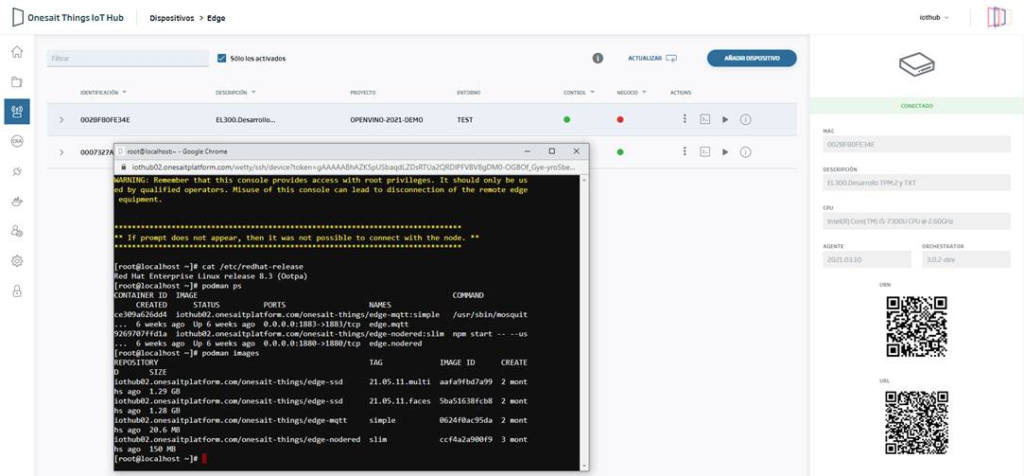
Edge Agent (based on Go 1.15.8) in Edge Device Orchestration with advanced Podman interface
We have made an update of IoT/Edge Agent to be able to interact with Podman deployments >=3.0 on RHEL 8 or related distributions. It is now possible to run containers in isolation or using docker-compose emulation, available in Podman.
IoT/Edge HUB deployment on VM/Baremetal using microk8s
We have certified and released IoT/Edge HUB deployment on microk8s using VMs or Baremetal. The Helm deployment parameterized for a deployment using microk8s Helm v.3 Addon is now available.
IoT/Edge HUB deployment for VM/Baremetal using Rancher 2.5
We have also certified and released the IoT/Edge HUB deployment on Rancher 2.5 using VMs or Baremetal. Parameterized Helm deployment is now available for two different ingresses, Traefik (default in Rancher) and Apache Kong.
Edge Agent (based on Go 1.15.8) in Edge Cluster Orchestration with interfaces to microk8s
It is now possible to orchestrate workloads on microk8s in remote clusters with the deployment of the new version of IoT/Edge Agent. We can now design our deployments with Helm v.3, including them in the IoT/Edge HUB deployment framework, and the agent will take care of distributing and lifting the load securely, giving access to the remote cluster through kubectl.
DevOps
Within this line of work, we include all the tools, utilities and platform capabilities that help in Development and Operation.
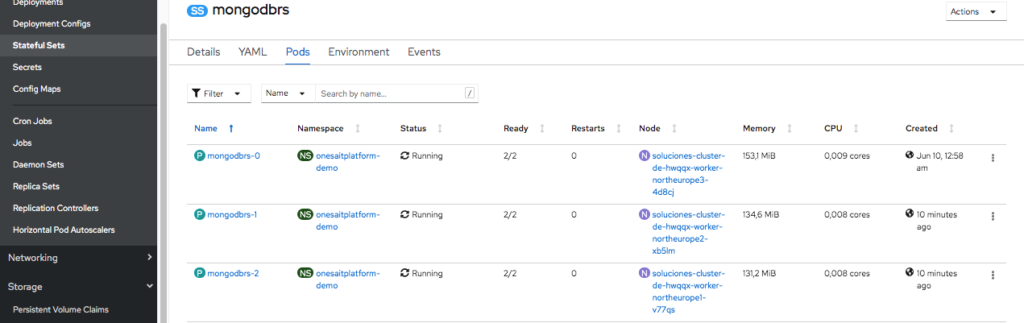
Helm Charts for high availability Platform resources deployment
In this version we have created Helm charts to deploy different Platform components in high availability, both in Kubernetes and Openshift. We can highlight the Chart to deploy a MongoDB Replica-Set in Kubernetes.
Onesait Platform Community
This line of work includes the tasks we carry out in relation to the Platform Community, of which the Open Source version of the Onesait Platform is a part, as well as the different communication channels of the Platform.
Throughout this quarter, we have been working on:
Version 2.3.0-ce on Github.
We have published version 2.3.0 of our Community version, which you can find in our GitHub repository for free download.
The list of changes that this version brings is as follows:
- Ontology Attribute Level Profiling.
- Default deployment on MongoDB 4.4 and new SQL Engine.
- FlowEngine Node to use platform management APIs.
- Improvements in integration between DataFlow and FlowEngine.
- Various improvements to the Platform in the field of security.
- New and great improvements in the Dashboard Engine.
- WebApps Vue.js generation from FIGMA designs.
- Upturns on Centralized Configuration.
- Queries Export from Query Tool.
- Cache at APIs.
- DocumentDB support in Semantic DataHub.
- AuroraDB support in Semantic DataHub.
CloudLab Update
Do you remember that, in the last release, we brought important visual changes? Well, version 3.0.0-jailbreak is now available in our free CloudLab test environment.
Don’t you know yet what CloudLab is? We recently told you about it in this article.
Onesait Platform Webcast
In each release, we carry out a webcast in which we explain first-hand the new features of the new version. This quarter, we did the webcast of version 3.0.0-jailbreak, which we leave below in case you haven’t seen it yet.
Surely, after the summer we will carry out the webcast of this release, so if you do not want to miss it, subscribe to our Meetup community, where there are already more than 700 subscribers.
Community Channels
These channels are the ones we use to keep in touch with you, and we continue to grow in both content and followers (thank you all very much!). Throughout this second quarter of the year we have:
- Reached 1,073 users in the Onesait Platform CloudLab, our free, experimental environment.
- Grown by +16 new subscribers on our YouTube channel, surpassing 145 total subscribers, adding +70 hours of viewing and achieving +8,000 impressions during this quarter.
- Surpassed 80 clones on GitHub of our Community version of the Platform, gaining +4 new developers, reaching a total of 248 developers following the project.
- Continued preparing content for DZone, and at the moment our articles have a total of +50,000 reads.
- Published a total of 24 entries in our Blog, reaching +30,000 reads quarterly.
- Reached 287 followers on Twitter, tweeting 165 times, getting 50 retweets and exceeding 30,000 impressions.
