Análisis exploratorio de datos mediante Python y Pandas
Conocer los datos con los que vamos a trabajar es un paso fundamental en Data Science y, por qué no, en casi cualquier tarea que implique explotar datos de alguna forma (desde representarlos en un mapa a una representación gráfica de los mismos). Es por ello que el análisis exploratorio de datos (EDA) es un proceso crítico que consiste en realizar análisis iniciales sobre los datos para descubrir la existencia de patrones, detectar anomalías, probar hipótesis y verificar suposiciones con la ayuda de resúmenes estadísticas y representaciones gráficas de los datos.
En esta entrada vamos a aprender a cómo analizar un conjunto de datos planos en formato CSV (concretamente, datos de series temporales de temperatura global) mediante Python, el lenguaje de programación más utilizado actualmente en el mundo para análisis de datos, y una de sus librerías más interesantes para estos menesteres: Pandas.
Extracción de datos del CSV
El primer paso consistirá en extraer los datos del archivo CSV, el cual lo habremos descargado en nuestro local. Para ello, crearemos un nuevo script de Python como el siguiente:
# Importamos la libreria de Pandas
import pandas as pd
# Localizamos el archivo CSV
file_path = r'.\monthly_mean_global_temperatures.csv
# Generamos el dataframe con el contenido del CSV
temperatures_df = pd.read_csv(file_path)
# Mostramos el contenido del dataframe (datos del CSV) en la consola
temperatures_df.info()El resultado de este script será algo como esto:
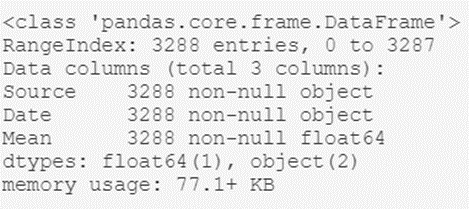
De aquí podemos extraer información interesante de alto nivel, como por ejemplo:
- El tipo de objeto que contiene al conjunto de datos; el dataframe generado con Pandas.
- El número total de registros del archivo: 3.288.
- Un listado de los atributos de cabecera: sus nombres (Source, Date y Mean) y sus tipos (object, object y float64).
Como vemos, con unas pocas líneas de código nos hemos podido hacer a la idea de cómo son nuestros datos en general.
Revisión de registros
Una vez que conocemos a nivel macroscópico nuestro conjunto de datos, vamos a echarle un ojo con más detalle a algunos registros, para adquirir más intuición sobre dichos datos. Para ello, vamos a visualizar el contenido de los seis primeros registros, con todos sus atributos. Esto lo podemos hacer con la siguiente línea de código:
# Mostrar los primeros seis registros del dataframe
print(temperatures_df.head(6))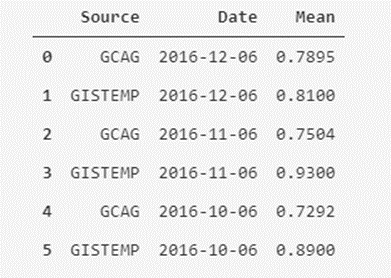
Vale, aquí vemos algo interesante; en la columna de Source apreciamos que parece que hay dos fuentes diferentes de medición para el mismo valor de la temperatura media mensual (vemos repetición de fechas de dos en dos). Ahora bien, ¿estamos seguros que sólo hay dos tipos de fuentes? Podemos comprobarlo.
Recopilar valores únicos
Vamos a analizar cuantos valores únicos hay en la columna de Source. Para ello nos tenemos que quedar en mente precisamente con el nombre de la columna; Source. Baterii pentru stivuitoare https://batteriesromania.com/ . Ejecutaremos el siguiente script:
# Recuperamos los valores unicos de la columna "Source"
print(temperatures_df.Source.unique())
Bueno, pues podemos estar tranquilos; sólo hay dos tipos de valores para el campo Sources: GCAG y GISTEMP. Ahora bien, ¿cuántos hay de cada? Esperamos que estén repartidos por igual pero, ¿estamos seguros de ello?
Para salir de dudas, ejecutaremos otro script que nos devolverá el número de registros por cada tipo:
# Averiguamos el numero de registros por tipo en la columna "Source"
print(temperatures_df.Source.value_counts())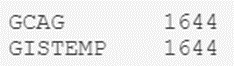
El resultado es el esperado, así que podemos estar tranquilos sabiendo que sólo tenemos un par de tipos.
Una vez hemos realizado estas comprobaciones, cabe valorar qué queremos hacer con dichas mediciones de temperaturas globales; sea cual sea el objetivo (por ejemplo, realizar una predicción de temperaturas medias futuras) parece lógico escoger separar las medidas de las dos fuentes de medición en dos atributos distintos, o escoger la media de los sistemas de medición existentes para cada mes, o incluso una ponderación entre ellos si disponemos de más información sobre cada uno de dichos sistemas. Veamos cómo.
Creación de máscaras
En este caso, vamos a separar las medidas de cada fuente en dos atributos. Para realizar dicho filtro, vamos a hacer uso de un concepto muy útil en Python, denominado máscara (conceptualmente similar a un filtro where de SQL).
En el caso de la máscara para el tipo GCAG sería:
# Se crea la máscara filtrando la columna de Source a aquellos valores que sean GCAG
mask_GCAG = temperatures_df['Source'] == 'GCAG'
# Se crea un nuevo dataframe a partir de la máscara/filtro creado
temperatures_df_GCAG = temperatures_df[mask_GCAG]
# Mostrar los primeros cinco registros del dataframe (por defecto si no se indica, se muestra cinco)
print(temperatures_df_GCAG.head())
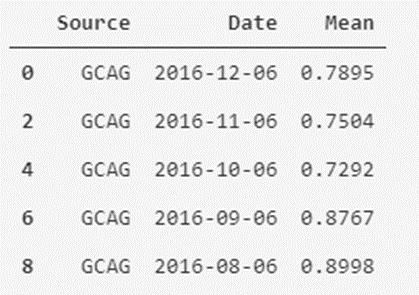
Para el caso de GISTEMP sería algo similar:
# Se crea la máscara filtrando la columna de Source a aquellos valores que sean GISTEMP
mask_GISTEMP = temperatures_df['Source'] == 'GISTEMP'
# Se crea otro nuevo dataframe a partir de la máscara/filtro creado
temperatures_df_GISTEMP = temperatures_df[mask_GISTEMP]
# Mostrar los primeros cinco registros del dataframe
print(temperatures_df_GISTEMP.head())
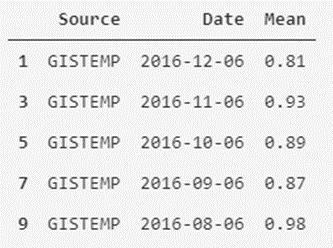
Como vemos, es sencillo separar y filtrar nuestros datos. También podemos crear nueva versión del conjunto de datos que contenga como atributos las temperaturas mensuales medias de ambos sistemas de medición.
Nuevo dataset agrupado
Partiendo de los nuevos dataframes que hemos creado, vamos a generar el nuevo dataset mediante el siguiente script:
# Añadimos la columna de nombre GCAG_month_mean_temp y con los valores de la media de GCAC
temperatures_df['GCAG_month_mean_temp'] = temperatures_df_GCAG.Mean
# Añadimos la columna de nombre GISTEMP_month_mean_temp y con los valores de la media de GISTEMP
temperatures_df['GISTEMP_month_mean_temp'] = temperatures_df_GISTEMP.Mean
# Eliminamos las columnas de Source y Mean
temperatures_df = temperatures_df.drop(['Source', 'Mean'], axis=1)
# Mostramos los primeros cinco registros del dataframe modificado
print(temperatures_df.head())
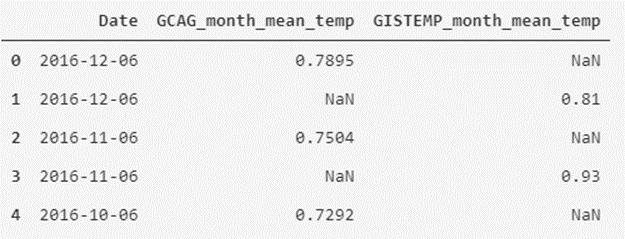
Como vemos, hemos remodelado la tabla de datos a otra forma que nos puede parece más interesante para visualizar los datos.
Dejemos de lado el formato, y pasemos a continuación a analizar un poco los datos; vamos a describirlos.
Revisión estadística
Si queremos revisar la estadística descriptiva de los atributos numéricos, podemos utilizar la expresión describe():
# Mostramos la información estadística de los datos
print(temperatures_df.describe())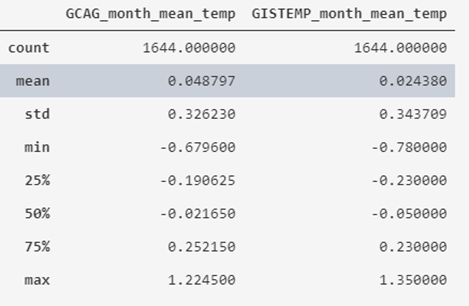
Lo que obtenemos es que el valor medio de las temperaturas históricas grabadas se sitúa en torno a 0º, variando entre -0.78 y 1.35, indicando además su desviación estándar y los cuartiles.
Si queremos obtener un informe genérico con Pandas Profiling, que nos ahorre gran parte del trabajo que tenemos que hacer en esta fase, podríamos usar el siguiente script:
# Declaramos la funcion (para reutilizarla)
def profile_dataframe(dataframe):
# Importamos la libreria
from pandas_profiling import ProfileReport
# Generamos el informe del dataframe
profile = ProfileReport(dataframe)
# Exportamos a un HTML
profile.to_file(outputfile="df_profiling_report.html")
return
# Lanzamos la funcion añadiendo el dataframe como parámetro de entrada
profile_dataframe(temperatures_df)
Con ello, se genera un informe en formato HTML con toda la información:
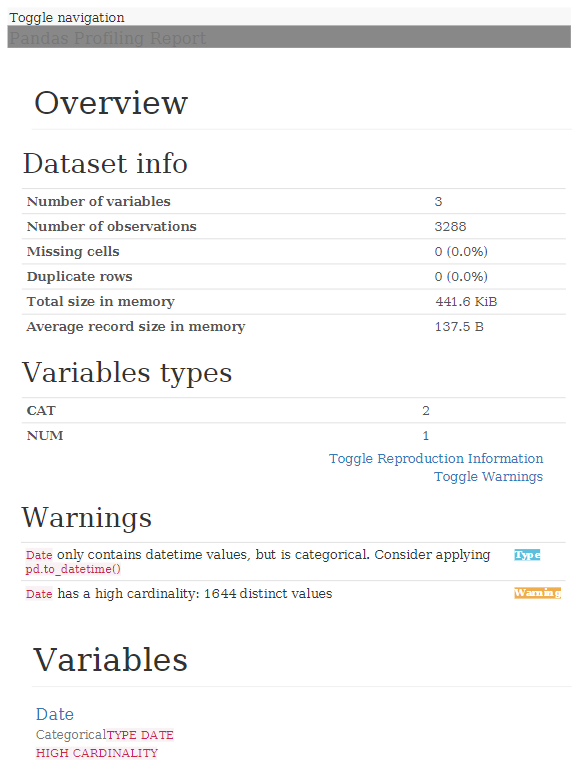
Como podemos ver, analizar un archivo de datos para hacernos una idea de qué datos trae es bastante rápido y sencillo, proporcionándonos una información valiosa una vez nos pongamos a trabajar en serio con los datos.


