
Ejecutar una aplicación Spark con StreamSets
A la hora de procesar grandes cantidades de datos en un tiempo reducido, Spark se convierte en una plataforma interesante para realizar todo este procesado, ya que permite realizar operaciones sobre un gran volumen de datos en clústeres de forma rápida y con tolerancia a fallos.
StreamSets ofrece un procesador llamado Spark Evaluator que permite realizar un procesamiento personalizado dentro de un pipeline basado en una aplicación Spark. Para ello, es necesario crear una aplicación Spark usando el lenguaje de Java o Scala, y encapsularlo en un JAR. El siguiente ejemplo se ha extraído del blog de StreamSets, y muestra los pasos a seguir para ejecutar tu aplicación. Para descargarte los datos de entrada del ejemplo puedes acceder a los tutoriales que ofrece StreamSets.
En primer lugar, hay que desarrollar la aplicación Spark, en la que hay que incluir el método «transform»; este método se llama por cada lote de registros que procesa el pipeline y es en el que se procesa los datos de acuerdo con el código personalizado. El procesador Spark Evaluator transforma los datos procesados en un conjunto de datos distribuido resistente (RDD). Además, existen dos métodos más, uno para realizar conexiones a sistemas externos o leer datos de configuración o de sistemas externos, «init», que se llama una vez al inicio, y «destroy», que se llama al detener el pipeline y sirve para cerrar las conexiones que se hayan realizado en el «init» a sistemas externos.
En este ejemplo, el método «transform» lee un conjunto de datos en los que está informado un número de tarjeta de crédito. Según el número por el que comience dicho campo, se determinará el tipo de tarjeta que es, realizando un control de errores si el campo viene vacío. La configuración que relaciona el número con el tipo de tarjeta se ha añadido en el propio Spark Evaluator:
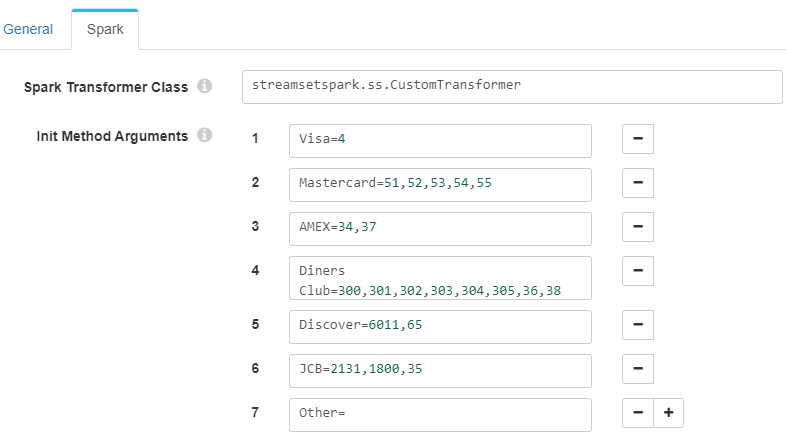
Para leer esta información, es necesario incluir el método «init», que guarda la información en el mapa «ccTypes» para después poder usarlo en el procesado de datos:

El método «transform» realiza, en primer lugar, la validación de los datos, devolviendo como error aquellas entradas cuyo valor del número de la tarjeta no venga informado o esté vacío.
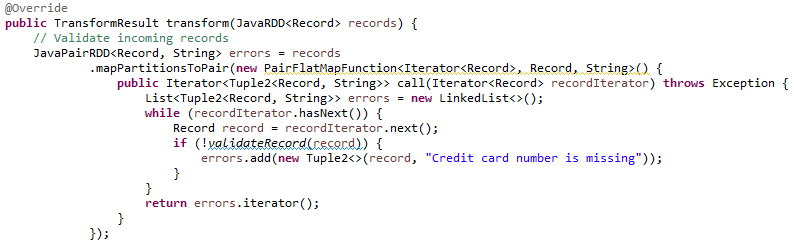
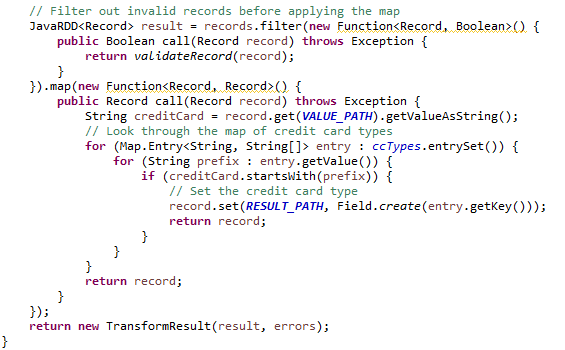
Después, para generar la respuesta la cual añade el campo de tipo de tarjeta al conjunto de datos recibido, se realiza el filtro para no procesar aquellos datos clasificados como erróneos, y con la información extraída de la configuración del Spark Evaluator se añade el nuevo campo, devolviendo el «TransformResult» con los RDD de respuesta y errores:
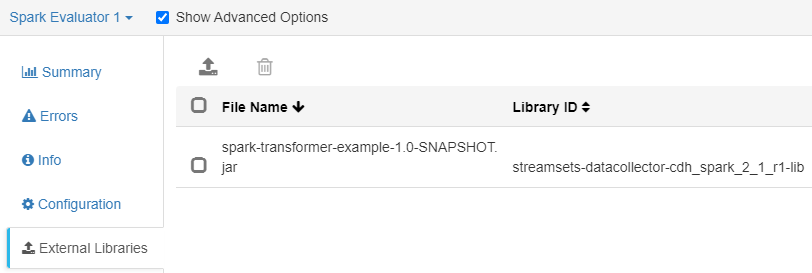
Para poder usar la aplicación en StreamSets, hay que empaquetarla en un JAR, compilándola con la misma versión de la biblioteca que se usa para el procesador Spark Evaluator. Este JAR se añadirá como librería externa en el componente de StreamSets:
Resumiendo, el componente Spark Evaluator queda con la siguiente configuración:
- Spark Transformer Class: streamsetspark.ss.CustomTransformer (corresponde al nombre de la clase que contiene el método «transform»).
- Init Method Arguments: con la configuración que clasifica cada tipo de tarjeta, como se muestra en la primera imagen (Configuración del Spark Evaluator).
- Parallelism (Standalone Mode Only): 4.
- Application Name (Standalone Mode Only): SDC Spark App.
El flujo que se ha representado empieza con la lectura del fichero csv comentado anteriormente, un filtro que identifica qué operaciones se han realizado con tarjeta y cuales no, la ejecución del código Spark, y la inserción de la nueva información en un fichero local.
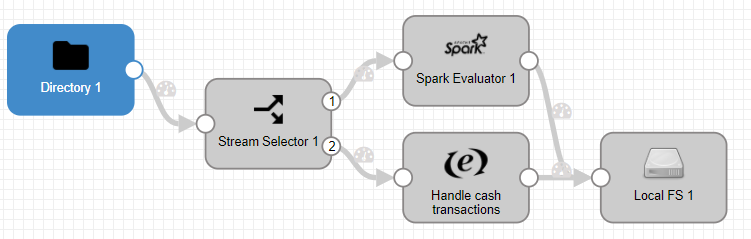
- Directory 1: en la pestaña Files hay que seleccionar el directorio en el que se localiza el fichero, y su nombre.
- Stream Selector 1: en la pestaña Conditions se añade
${record:value("/payment_type")=="CRD"}para filtrar aquellos datos que se han realizado con tarjeta de crédito. - Spark Evaluator 1: tiene la configuración comentada anteriormente, con el JAR de la aplicación Spark instalada como librería externa.
- Handle cash transactions: simplemente añade el campo «credit_card_type» con valor «n/a» para que todos los datos guardados en el fichero final tengan este campo informado.
- Local FS 1: guarda el fichero en la ruta especificada en formato JSON.
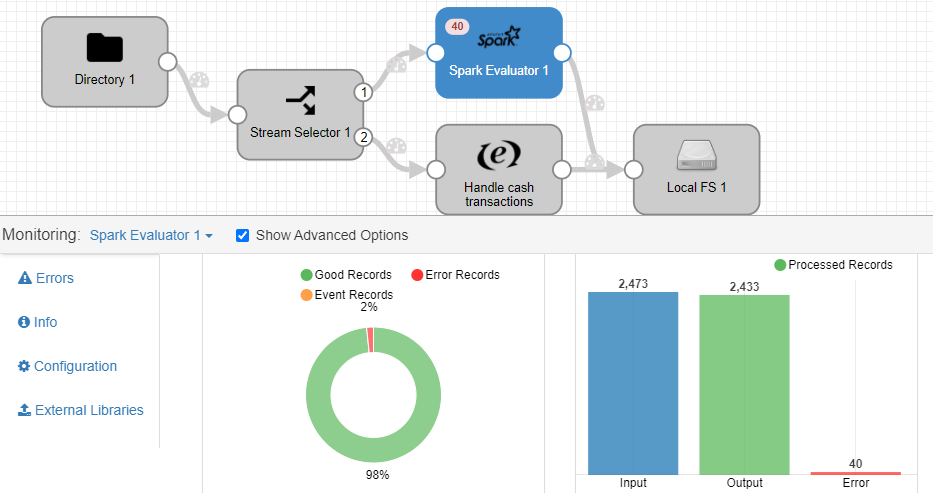
Una vez se ejecuta el pipeline, podemos observar que al componente Spark Evaluator le llegan 2473 datos realizados con tarjeta de crédito, de los cuales 40 han fallado a causa de no venir informado el campo «credit_card»:
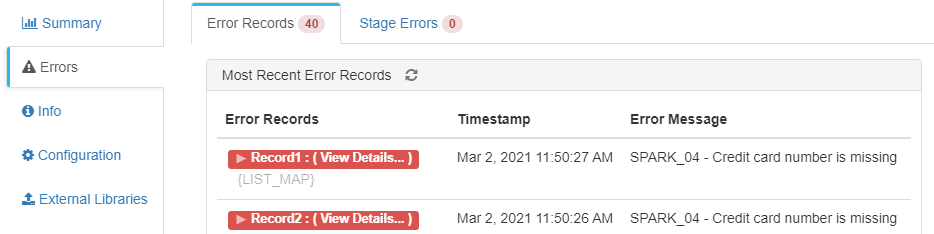
De esta manera, el fichero final tendrá los datos procesados por Spark Evaluator sin errores, más los filtrados por no ser de tipo «credit_card» con la clasificación de tipo de tarjeta añadido con la aplicación Spark.


Cool!