
Data Fabric: concepto, capacidades y estado del arte
No es fácil definir el concepto de Data Fabric porque la definición va cambiando según evoluciona el concepto que ha pasado de estar asociado inicialmente a un producto a un enfoque arquitectónico y de diseño para la gestión e integración de datos. De hecho, muchos proveedores han creado su propia definición de Data Fabric adaptándolo a su oferta, lo que ha generado más confusión aún.
Actualmente, el interés en torno al concepto de Data Fabric es muy grande, ya que existe una necesidad real de gestionar mejor los datos por motivos como:
- La escasez de ingenieros de datos cualificados, lo que hace que la automatización sea una necesidad.
- La adopción de soluciones en la nube ha introducido muchos almacenes de datos de propósito especial para capturar y gestionar datos.
- El aumento del número de fuentes de datos que hay que integrar y la diversidad de estas (estructuradas, semiestructuradas y no estructuradas).
- La creación de más silos de datos.
- Las empresas se enfrentan a la intrusión de eventos y fuerzas externas que requieren un rápido análisis en el entorno de datos. Esto impulsa la necesidad de poder integrar fuentes de datos nuevas de forma ágil.
- La necesidad de reducir los costes a largo plazo debido al aumento de la competencia.

Estos y otros factores impulsan la necesidad de un Data Fabric, ya que este puede ayudarnos en la automatización y optimización de los datos, permitiendo gestionar e integrar mejor los datos, al tiempo que proporciona una capa uniforme a la que pueden acceder todos los consumidores de datos.
Capacidades de un Data Fabric
Para facilitar el análisis, vamos a agrupar las capacidades esperadas de un Data Fabric en estas categorías:
- Catálogo de datos ampliado: ser capaz de encontrar, conectar, catalogar e integrar todos los tipos de datos y metadatos es una de las capacidades principales de un Data Fabric. El catálogo de datos se conecta a los metadatos de todas las fuentes y automatiza algunas de las tareas relacionadas con el uso de un catálogo de datos, como el descubrimiento y la ingestión de metadatos.
- Grafo de conocimiento enriquecido con semántica: este grafo está diseñado y construido para almacenar y visualizar la compleja relación entre múltiples entidades. Además, las taxonomías y ontologías utilizadas en los grafos de conocimiento deben ser intuitivas de interpretar y mantener para los recursos no técnicos.
- Activación de los metadatos: tradicionalmente, sólo se han considerado los metadatos pasivos que se generan en el momento en que se crean los objetos de datos individuales (por ejemplo, el tipo de datos, la longitud y la descripción). En un Data Fabric se consideran metadatos técnicos adicionales, como registros de transacciones, registros de usuarios y planes de optimización de consultas. En combinación con el grafo de conocimiento, los metadatos técnicos se utilizan para crear lo que se denomina metadatos activos. Los metadatos activos se utilizarán como entrada para el motor de recomendación.
- Motor de recomendación: basándose en los metadatos activos, se aplican rutinas de inteligencia artificial (IA) y aprendizaje automático (ML) para recomendar optimizaciones de la integración y la entrega de datos. Por ejemplo, el motor de recomendación puede proponer la conversión de un flujo de datos implementado a través de la virtualización a un modo de entrega near-real-time debido al deterioro del rendimiento.
- Preparación y entrega de datos: un Data Fabric permite la preparación de datos en régimen de autoservicio, permitiendo a los usuarios acceder a la capa semántica común, representada por el grafo de conocimiento, en un entorno donde pueden explorar y transformar los datos para crear nuevos conjuntos de datos. El segundo elemento, la entrega de datos, es la capacidad de soportar diferentes estilos de entrega de datos a los consumidores de datos (por ejemplo: soporte para streaming, bulk/batch y virtualización).
- Orquestación y DataOps: la capa de orquestación apoyará una mejor sincronización de los flujos de datos. El uso de los principios de DataOps en todo el proceso permite una entrega de datos ágil y repetible. Секс с девушками, ЖМЖ и МЖМ, коллекция сладострастных шлюхи Луганск и длинноногие проститутки ЛНР. Хороший интим за небольшие деньги.
Estas categorías o pilares de un Data Fabric constituyen una arquitectura Data Fabric diseñada para soportar todo el espectro de gestión y tratamiento de datos.
Estado del arte
Como hemos dicho, actualmente el concepto de Data Fabric se define más como un patrón de diseño emergente de gestión e integración de datos que como un producto. La implementación de un Data Fabric requiere una combinación de diferentes tecnologías de gestión de datos, tanto conocidas como emergentes.

Según el Hype Cycle for Data Management (2021), el Data Fabric tiene una penetración estimada en el mercado de entre el 1% y el 5% y se sitúa en la cima del Pico de Expectativas Infladas. Tiene un horizonte de cinco a diez años para alcanzar su plena madurez.
Además, algunos de los componentes de un Data Fabric están aún menos maduros y, por tanto, también tienen una penetración de mercado aún menor. Por ejemplo, DataOps todavía se define como un activador de la innovación con una penetración en el mercado inferior al 1%.
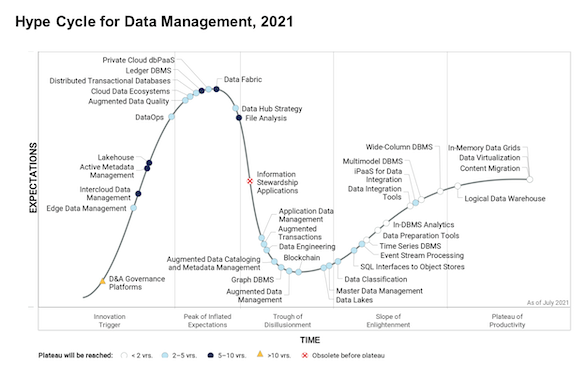
En la actualidad, ningún proveedor es capaz de proporcionar una cobertura completa de todos los pilares de un Data Fabric en una sola plataforma totalmente integrada, esto significa que no es posible simplemente comprar un producto Data Fabric que cubra todas las capacidades.
¿Cómo lo veis? ¿Pensáis que esto se podrá acelerar por el interés generado, o habrá que esperar esos cinco a diez años que se comentan?
Imagen de cabecera de 🇸🇮 Janko Ferlič en Unsplash


