
Orquestación de notebooks desde el motor de flujos: Procesamiento de imágenes con Onesait Platform
Dentro de la Onesait Platform tenemos la posibilidad de orquestar la ejecución de notebooks (o incluso párrafos sueltos de los mismos).
Con esta característica, se pueden orquestar procesos basados en notebooks e incluso paralelizar los mismos distribuyendo la carga de trabajo. Es posible pasar parámetros dinámicos a estos notebooks, pudiendo incluir información fija o generada por un flujo sobre cualquier lenguaje usado en los notebooks y más adelante iniciar una ejecución con los mismos.
Al igual que los parámetros de entrada, se posibilita la salida de los datos generados por uno o varios párrafos de un notebook, incluyendo información generada por un proceso analítico dentro del flujo, y así tomar decisiones en base al mismo.
En este tutorial vamos ver cómo podemos hacer procesamiento de imágenes en notebooks con Python PIL. Además lo orquestaremos y disponibilizaremos como API desde el motor de flujos. Por ultimo construiremos un dashboard para lanzar el proceso y visualizar el resultado.
Para ello usaremos los siguientes componentes de la Onesait Platform:
- Notebooks: crearemos varios notebooks usando la librería PIL de procesamiento de imágenes para Python.
- Flow Engine: orquestaremos las llamadas a los distintos notebooks para poder procesar una imagen de entrada y generar un histograma y aplicar varios filtros (Blur, escala de grises y combinado de ambas). Además publicaremos una API que gestionará el lanzamiento del procesado de las imágenes.
- Binary Files: almacenaremos tanto la imagen de partida como los resultados del procesamiento.
- Ontologías: almacenarán el resultado del proceso, guardando los IDs de las imágenes generadas, así como un histograma de la imagen de partida.
- Dashboards: crearemos un Dashboard que nos permitirá subir una imagen a los Binary Files y lanzará el procesamiento de la misma. Al finalizar, podremos ver el resultado, mostrando las imágenes e histograma.
NOTEBOOKS
Empezaremos creando los notebooks que procesarán las imágenes. Crearemos los siguiente cuatro notebooks:
ImageBlur
Este notebook será el encargado de aplicar un filtro de desenfoque a una imagen de entrada. Crearemos cinco párrafos:
- Definición de variables: las entradas serán:
- binaryID: identificador del fichero de entrada.
- Token: token Oauth del usuario.
- fileName: nombre del fichero de salida.
- Lectura de la imagen desde Binary Files.
- Aplicar filtro de desenfoque (Blur filter).
- Almacenar el resultado del filtro en Binary Files.
- Devolver el ID de la nueva imagen generada.





ImgRGBToGreyscale
Este notebook será el encargado de aplicar un filtro de escala de grises a una imagen de entrada. Tendrá cinco párrafos al igual que el notebook anterior, cambiado solamente el tercer y cuarto párrafos para indicar el nuevo filtro y formato del fichero:


ImageHistogram
Este notebook generará un histograma a partir de la imagen de entrada y consta de tres párrafos:
- Definición de variables: las entradas serán:
- binaryID: identificador del fichero de entrada.
- Token: token Oauth del usuario.
- Lectura de la imagen desde Binary Files
- Generación del histograma.

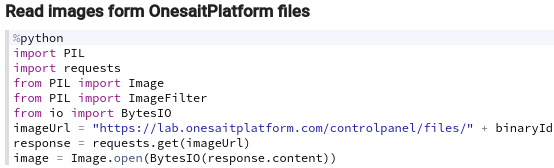

GroupImagesData
El último notebook se encargará de agrupar la información generada por los tres anteriores y crear una instancia de ontología con ellos para que podamos insertar los datos generados en la ontología destino. Consta de un único párrafo donde se leerán los parámetros de entrada:
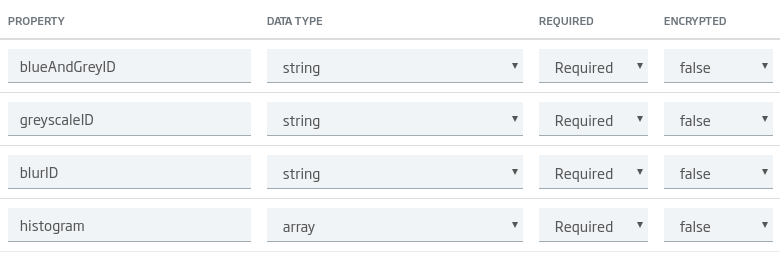
- greyID: ID del fichero en Binary Files que contiene la imagen en escala de grises.
- blurID: ID del fichero en Binary Files que contiene la imagen con el filtro de desenfoque.
- greyAndBlurID: ID del fichero en Binary Files que contiene la imagen a la que se le han aplicado ambos filtros.
- histogram: histograma de la imagen origen.

ONTOLOGÍAS
Para almacenar el resultado del procesamiento de imágenes crearemos una ontología con la siguiente estructura:
MOTOR DE FLUJOS
Dividiremos el flujo a crear en tres etapas: creación de la API, orquestación de notebooks e inserción del resultado en ontología.
Creación de la API
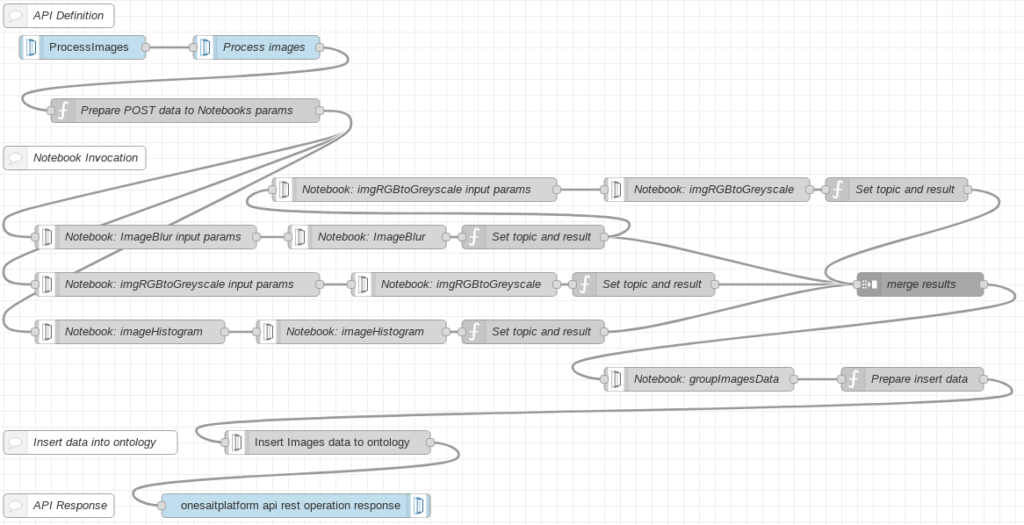
Para crear una API, usaremos al menos tres nodos.
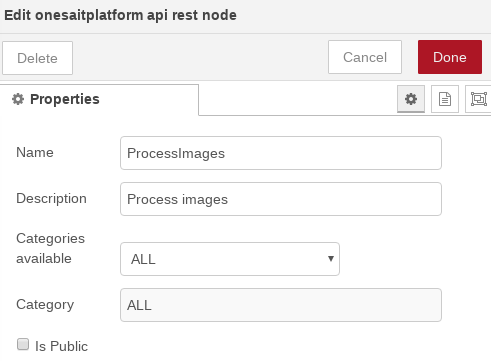
- OnesaitPlatform REST API: este nodo representa la API a crear. Los campos obligatorios a rellenar son el nombre, descripción, categoría y si queremos que sea pública:
- OnesaitPlatform REST API Operation: este nodo representa una operación dentro de la API. Los parámetros a rellenar son:
- Method: método de la operación: POST, GET, PUT o DELETE.
- Accepts file uploads?: check que indica si queremos aceptar subidas de ficheros (solo disponible para método POST).
- URL: path de la operación.
- Name: nombre que damos a la operación.
- Description: descripción de la misma.
- Query params: en caso de que sea necesario definir query params, se acepta un JSON con el formato {«param_name»:»param_type»}
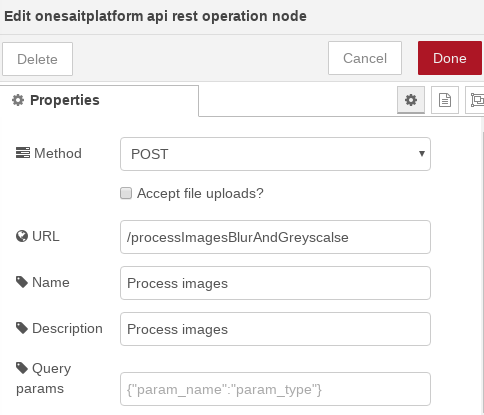
- OnesaitPlatform REST API Operation: este nodo es necesario que esté al final de cada flujo que se desencadene desde una operación de API. Es el encargado de devolver el resultado a la invocación de dicha operación. En él indicamos el código de retorno que queremos devolver o «msg.statusCode» por defecto:
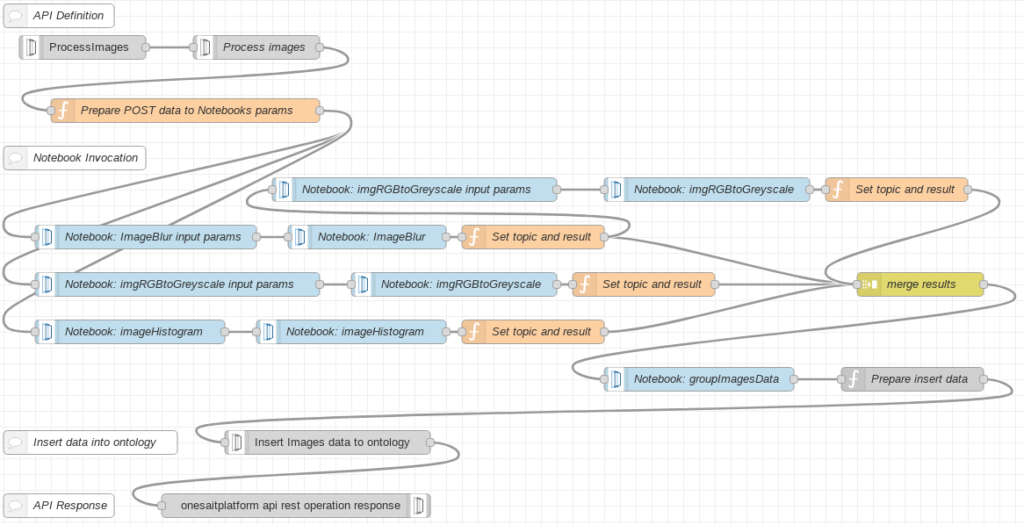
Orquestación de Notebooks
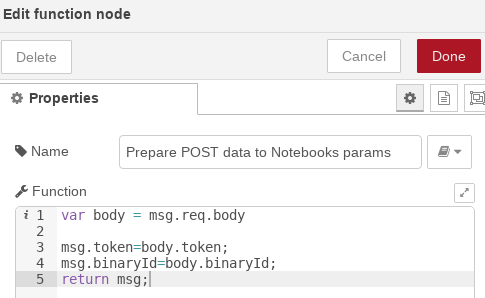
Antes de empezar a invocar los distintos notebooks, vamos a preparar los datos de entrada que nos llegan desde la operación POST de la API creada. El «body» de la petición REST debe de darnos el ID de la imagen a tratar y el token:
Desde este nodo «function» enlazaremos la ejecución de los tres notebooks en paralelo. Cada invocación del notebook se realizará en tres etapas: Preparación de parámetros, ejecución del notebook completa y preparación de resultados.
Ejecución del histograma

- Preparación de parámetros: usaremos un nodo de invocación de notebooks en modo párrafo, selecionando el primero de ellos (Variable definition). Al cambiar la selección de párrafo aparecerán los inputs del notebook. En el paso «function» predecesor ya preparamos el id de la imagen y el token en el «msg» entrante. La pestaña de salidas se deshabilita, ya que solo ejecutamos un párrafo:
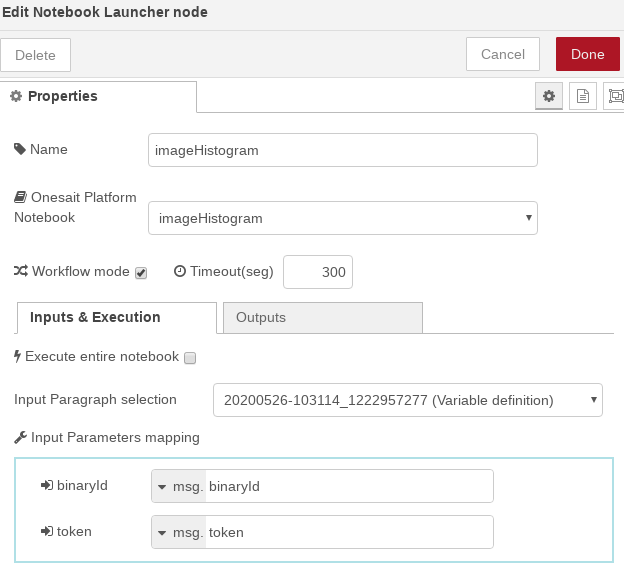
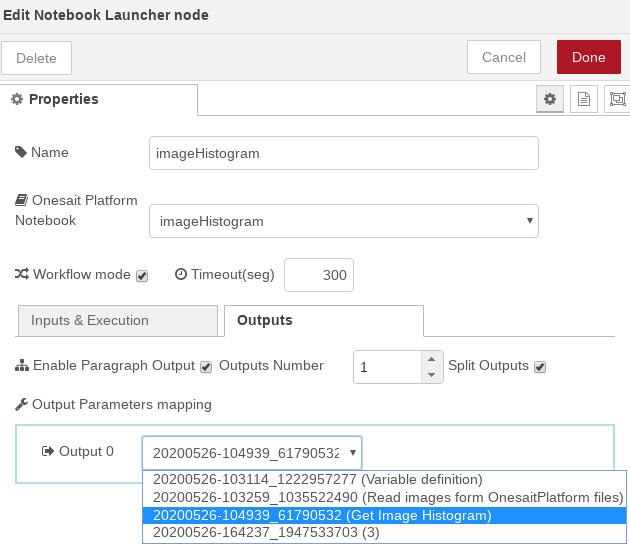
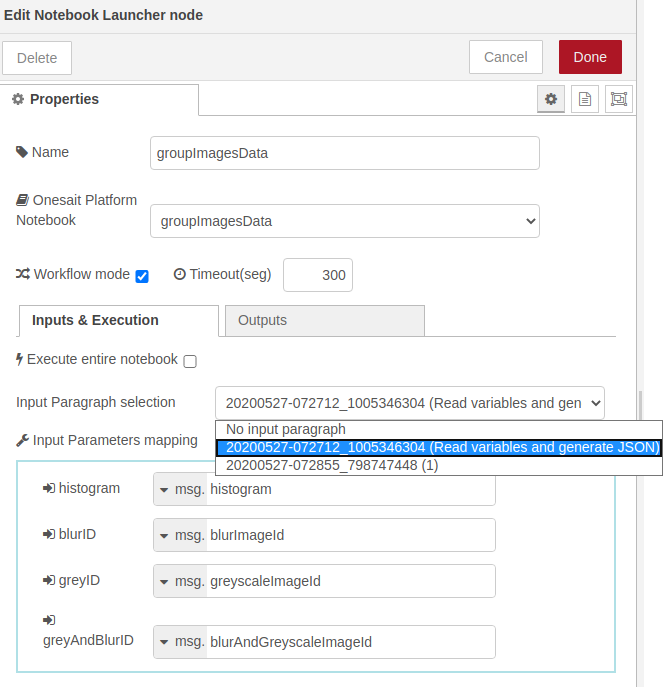
- Ejecución del Notebook completo: una vez definidos los parámetros de entrada, para que se genere el histograma, invocaremos el notebook completo marcando el check «Execute entire notebook». Al hacer esto, las opciones de entrada desaparecen y se nos permite seleccionar las salidas. En nuestro caso solamente nos interesa la salida del tercer párrafo (Get Image Histogram).
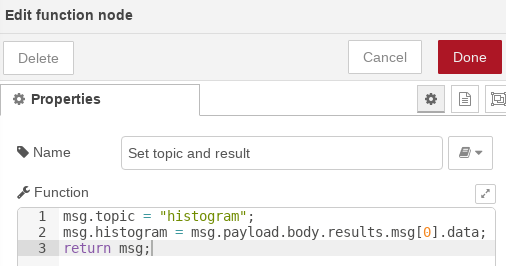
- Preparación de resultados: por último obtendremos el resultado de dicho párrafo y lo pasaremos a una variable del mensaje por comodidad. Además anotaremos el mensaje como perteneciente al tópico «histogram»:
Ejecución del filtro de escala de grises

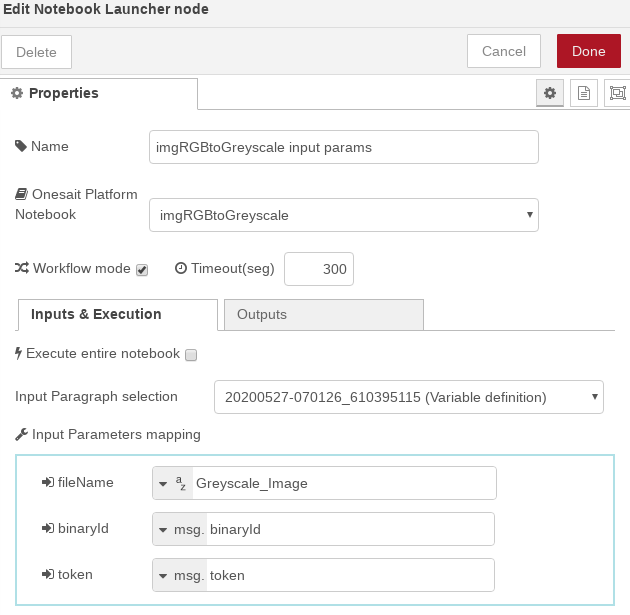
- Preparación de parámetros: usaremos un nodo de invocación de notebooks en modo párrafo, seleccionando el primero de ellos (Variable definition). Al cambiar la selección de párrafo aparecerán los inputs del notebook. En el paso «function» predecesor ya preparamos el id de la imagen y el token en el «msg» entrante. El nombre de la imagen resultado lo pondremos a mano como un String:
- Ejecución del Notebook completo: una vez definidos los parámetros de entrada, para que se genere la imagen en escala de grises, invocaremos el notebook completo marcando el check «Execute entire notebook». Al hacer esto, las opciones de entrada desaparecen y se nos permite seleccionar las salidas. En nuestro caso solamente nos interesa la salida del quinto párrafo (Return saved image ID).
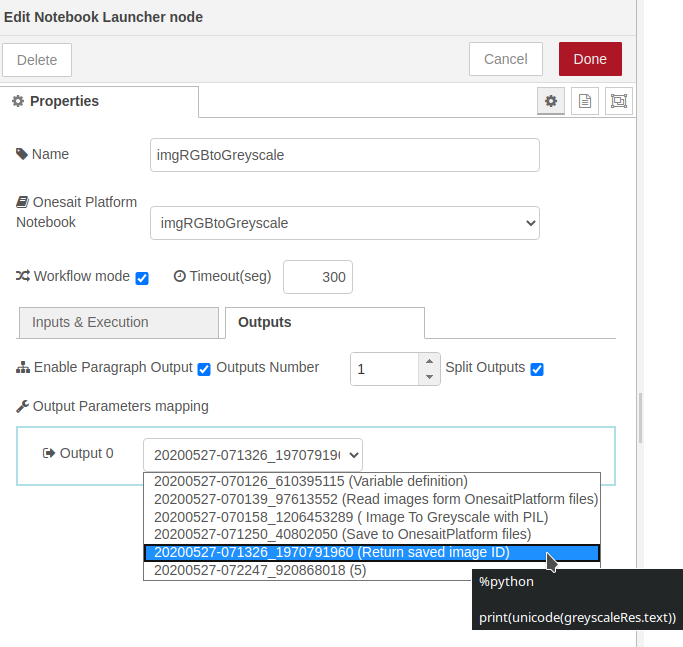
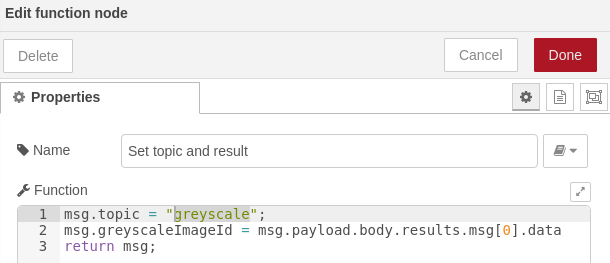
- Preparación de resultados: por último obtendremos el resultado de dicho párrafo y lo pasaremos a una variable del mensaje por comodidad. Además anotaremos el mensaje como perteneciente al tópico «greyscale»:
Ejecución del filtro de desenfoque

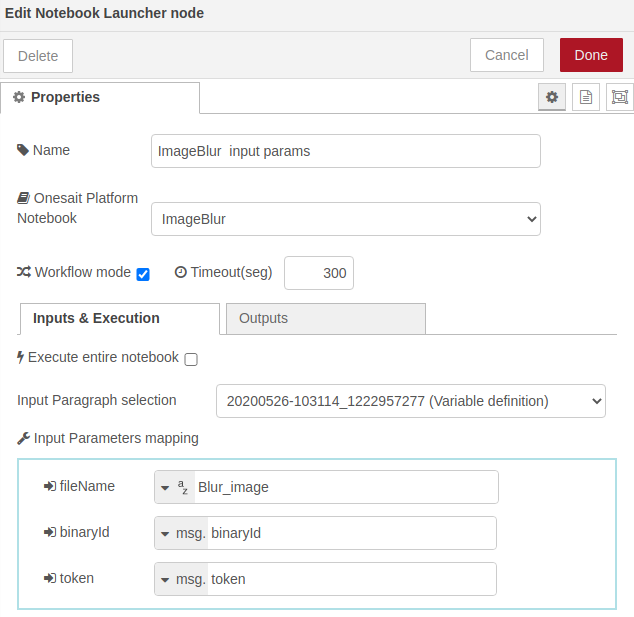
- Preparación de parámetros: usaremos un nodo de invocación de notebooks en modo párrafo, seleccionando el primero de ellos (Variable definition). Al cambiar la selección de párrafo aparecerán los inputs del notebook. En el paso «function» predecesor, ya habíamos preparado el id de la imagen y el token en el «msg» entrante. El nombre de la imagen resultado lo pondremos a mano como un String:
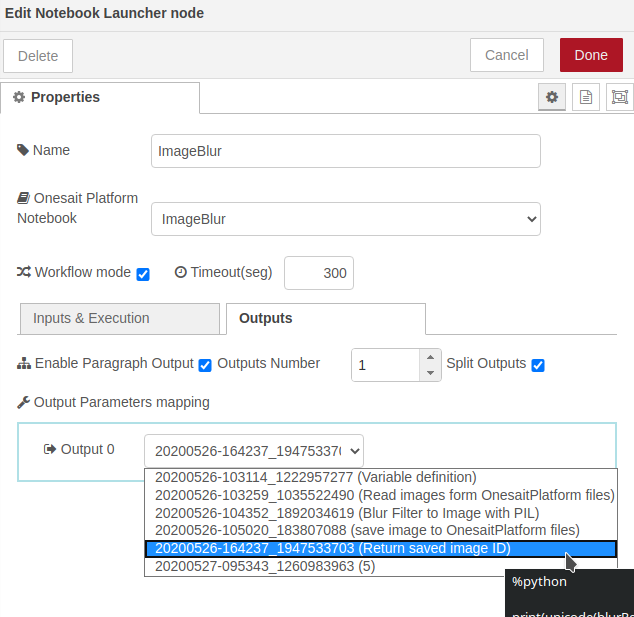
- Ejecución del Notebook completo: una vez definidos los parámetros de entrada, para que se genere la imagen desenfocada, invocaremos el notebook completo marcando el check «Execute entire notebook». Al hacer esto, las opciones de entrada desaparecen y se nos permite seleccionar las salidas. En nuestro caso solamente nos interesa la salida del quinto párrafo (Return saved image ID).
- Preparación de resultados: por último obtendremos el resultado de dicho párrafo y lo pasaremos a una variable del mensaje por comodidad. Además anotaremos el mensaje como perteneciente al tópico «blur»:
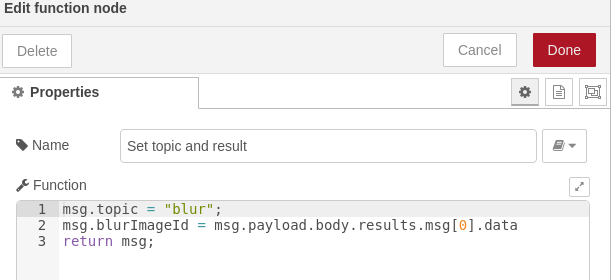
Ejecución del filtro de escala de grises sobre imagen desenfocada

- Preparación de parámetros: usaremos un nodo de invocación de notebooks en modo párrafo, seleccionando el primero de ellos (Variable definition). Al cambiar la selección de párrafo aparecerán los inputs del notebook. En el paso «function» predecesor ya preparamos el id de la imagen (Será el de la imagen con filtro de desenfoque) y el token en el «msg» entrante. El nombre de la imagen resultado lo pondremos a mano como un String:
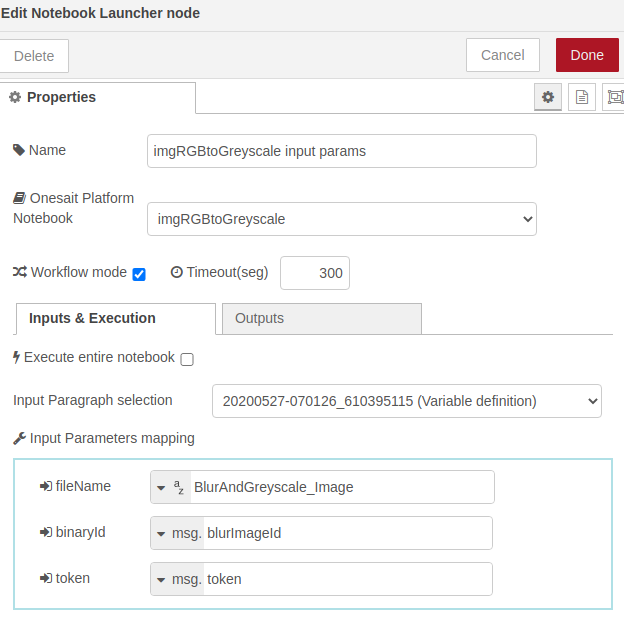
- Ejecución del Notebook completo: una vez definidos los parámetros de entrada, para que se genere la imagen en escala de grises sobre desenfoque, invocaremos el notebook completo marcando el check «Execute entire notebook». Al hacer esto, las opciones de entrada desaparecen y se nos permite seleccionar las salidas. En nuestro caso solamente nos interesa la salida del quinto párrafo (Return saved image ID).
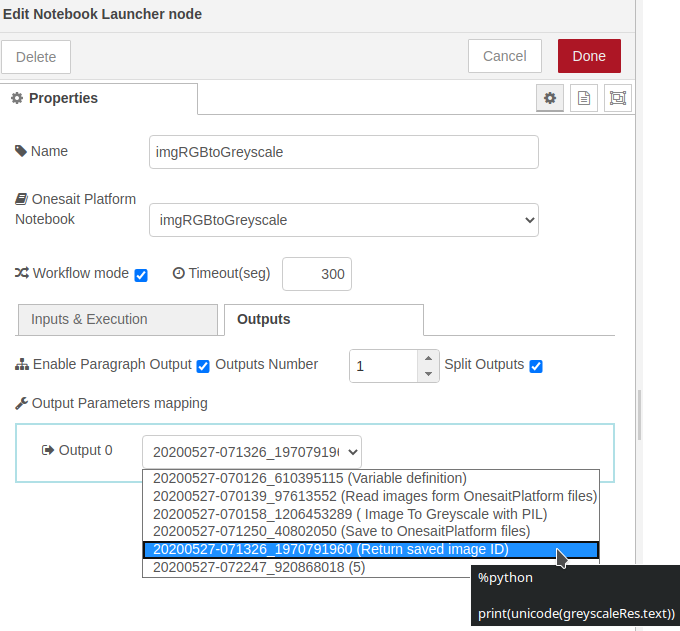
- Preparación de resultados: por último obtendremos el resultado de dicho párrafo y lo pasaremos a una variable del mensaje por comodidad. Además anotaremos el mensaje como perteneciente al tópico «blurAndGreyscale»:
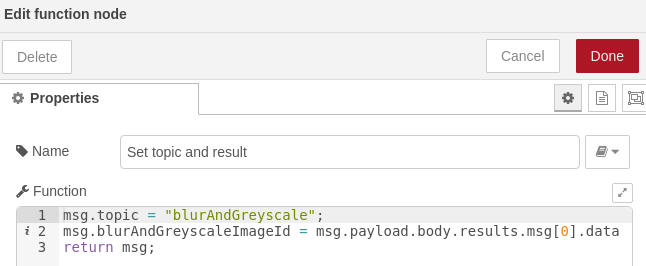
Unificación de resultados y generación de instancia de ontología
Este nodo unificará los cuatro mensajes previos (blur, greyscale, blurAndGreyscale y histogram) en un único mensaje, separando las propiedades por los tópicos de cada mensaje.
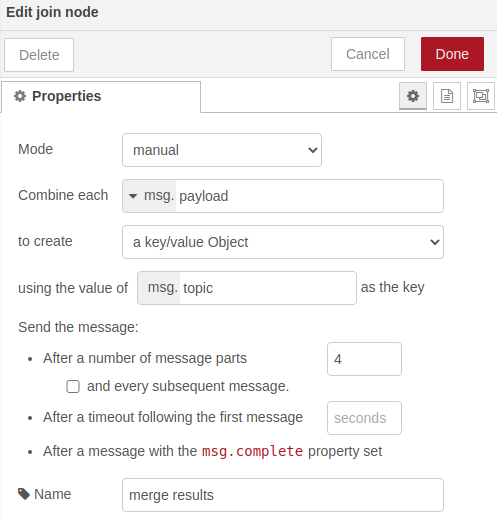
Una vez combinados los mensajes en uno solo, invocaremos el párrafo que nos generará la instancia de ontología a insertar con todos los datos del procesado de imágenes:

Inserción de resultado en la ontología
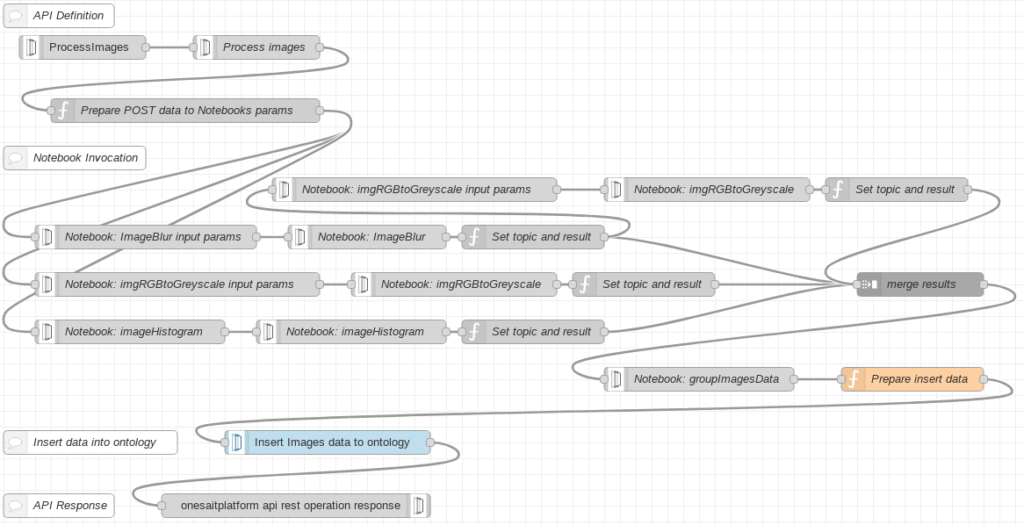
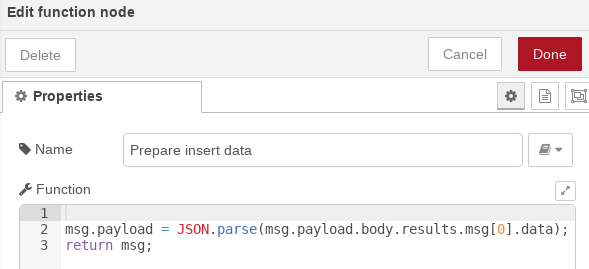
Primero obtenemos la instancia de ontología generada por la última llamada a notebook. El nodo «function» prepara el msg.payload necesario para la inserción de datos en la ontología destino:
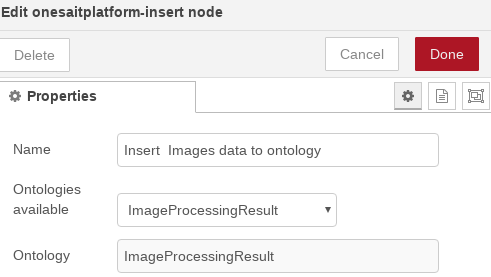
En el nodo «onesaitplatform-insert», especificamos la ontología de destino:
El resultado de la inserción (ID) será devuelto para la llamada a la operación de la API.
DASHBOARD
Además, ya que hemos creado todo esto como una API REST, podemos usarlo bajo demanda, por ejemplo en un Dashboard de la Plataforma:
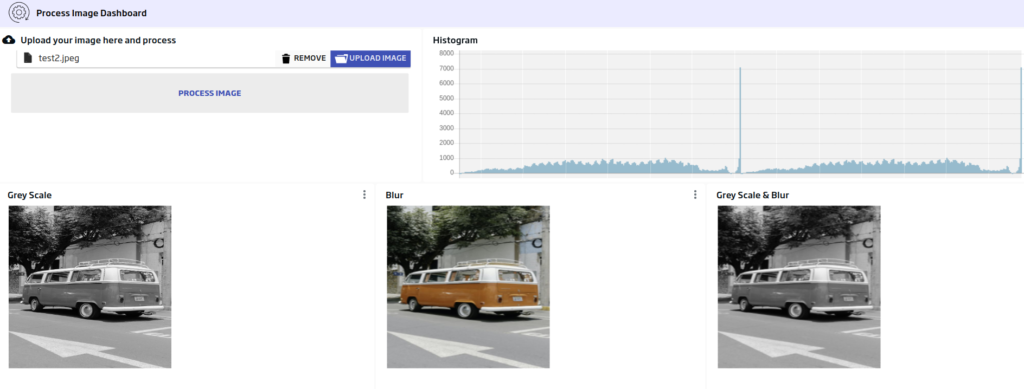
En el Dashboard hemos aunado la funcionalidad de subida de imágenes, así como la ejecución de la API que filtra la imagen subida.


