
Insertar datos usando REST en un topic Kafka mediante DataFlow
Hoy os queremos mostrar cómo se puede permitir la inserción de datos en un topic Kafka usando nuestra herramienta de DataFlow. Para ello, vamos a definir un flujo en el DataFlow que tenga como origen un nodo REST y como destino un productor Kafka.
Por tanto, a lo largo de esta entrada trataremos los siguientes objetivos:
- Validar los datos recibidos usando el esquema de una ontología definida en la Onesait Platform.
- Usar el framework de autenticación y autorización de la Onesait Platform a la hora de exponer el endpoint REST.
Dataflow para el ejemplo
En primer lugar, vamos a ver el flujo de datos que usaremos en el ejemplo:

Este flujo define un endpoint REST al que se le puede invocar con un método POST. Después, valida que el dato recibido en el «body» de dicho POST sea un JSON bien formado. Si es así, comprueba el esquema usando un script Groovy y, finalmente, inserta en Kafka.
Validación de datos
La Onesait Platform valida todos los datos insertados usando el «json-schema» definido en las ontologías. Este es un proceso que se realiza automáticamente en cada inserción de información. Pero, ¿podríamos usar ese mismo esquema para validar datos que no se van a insertar en una ontología? Seguidamente vamos a ver el código del script Groovy del flujo de datos anterior, para ver cómo se podría hacer esto de forma sencilla.
Empezaremos por el script de inicialización. Éste se ejecutará una vez al arrancar el flujo de datos:
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.github.fge.jsonschema.main.JsonSchema;
import com.github.fge.jsonschema.main.JsonSchemaFactory;
import groovy.json.JsonSlurper;
import groovyx.net.http.RESTClient;
def token = ${token}
RESTClient client = new RESTClient('http://controlpanelservice:18000')
def path = "/controlpanel/api/ontologies/apiTest"
def headers = ["X-OP-APIKey": token]
def response = client.get(path: path, headers: headers)
ObjectMapper mapper = new ObjectMapper()
JsonSchemaFactory factory = JsonSchemaFactory.byDefault()
JsonNode jsonSchemaNode = mapper.readTree(response.getData().jsonSchema)
state['jsonSchema'] = factory.getJsonSchema(jsonSchemaNode)
state['mapper'] = mapper
Lo que realiza este proceso de inicialización es conectarse a la Plataforma usando las APIs de gestión del Control Panel para descargar la información de la ontología que queremos usar. En este ejemplo se trataría de «apiTest».
Una vez que hemos obtenido los datos de la ontología, lo que se hace es usar la librería de «json-schema-validator» para validar los datos JSON, generando el objeto con el esquema y dejándolo listo para ser usado en la ejecución de cada petición. Para ello, se usa el mapa «state», que se puede usar durante el procesamiento de cada batch del flujo de datos para obtener dichos objetos.
Una vez inicializado, el script que se ejecutará en cada batch es el siguiente:
import com.github.fge.jsonschema.core.report.ProcessingReport;
import com.github.fge.jsonschema.core.report.LogLevel;
import com.github.fge.jsonschema.core.report.ProcessingMessage;
for (record in records) {
try {
def body = state.mapper.readTree(record.value.jsonBody)
ProcessingReport report = state.jsonSchema.validate(body)
if (report != null && !report.isSuccess()) {
def errors = state.mapper.createArrayNode();
Iterator<ProcessingMessage> it = report.iterator();
while (it.hasNext()) {
ProcessingMessage msg = it.next();
if (msg.getLogLevel().equals(LogLevel.ERROR)) {
errors.add(msg.asJson());
}
}
throw new Exception("Invalid JSON format: " + state.mapper.writeValueAsString(errors));
}
output.write(record)
} catch (e) {
// Write a record to the error pipeline
log.info(e.toString(), e)
error.write(record, e.toString())
}
}
Básicamente, lo que se hace es obtener el «body» de la petición, que en este caso viene en el campo «jsonBody» de cada uno de los registros, y comprobarlo con el validador que hemos inicializado en el script de inicialización. Dicha validación se hace en esta línea:
ProcessingReport report = state.jsonSchema.validate(body)El resto de código sirve para obtener los errores de validación, en caso de que haya alguno, y está basado en la documentación de la propia librería.
Finalmente, el tratamiento de errores dentro del DataFlow dependerá de cómo se esté haciendo en dicho proyecto. En el ejemplo que estamos llevando a cabo, hemos incluido una línea al registro del DataFlow a nivel «Info», y generado un registro de error que enviaremos al flujo de errores. Como podemos ver, con muy poco esfuerzo se pueden validar los datos sin ningún problema.
Ahora, vamos a probar el siguiente pipeline, y para ello veremos la configuración del conector REST que hemos creado:
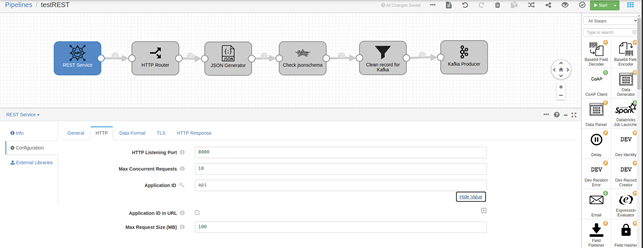
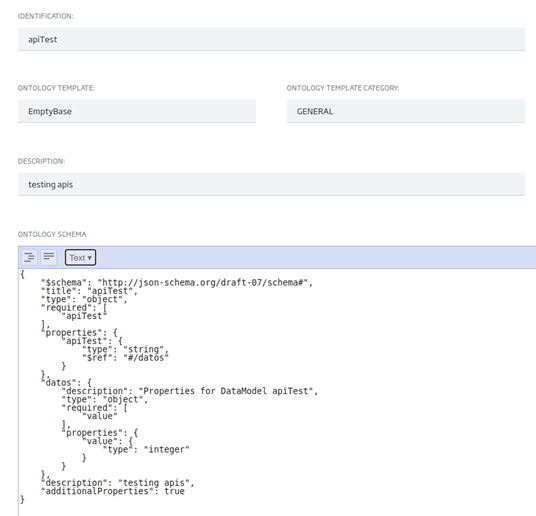
También hay que considerar el esquema de datos que estemos usando, que en este caso es muy sencillo:
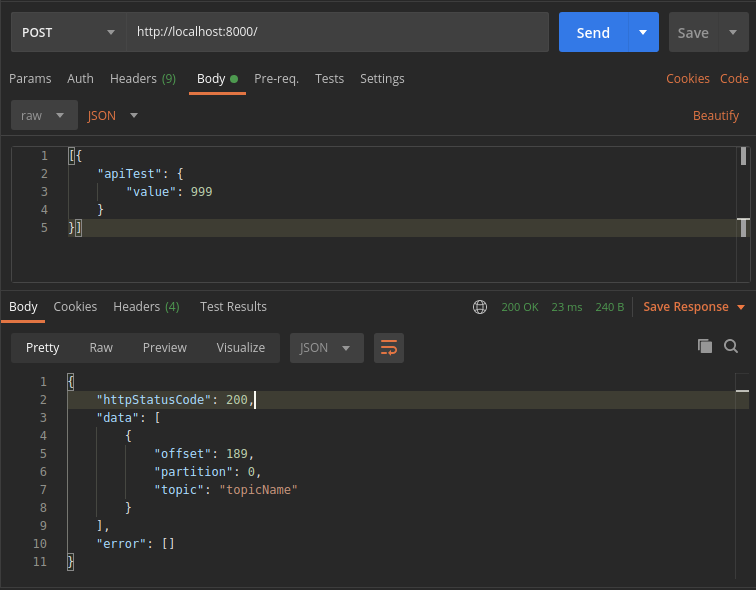
Para este ejemplo, vamos a usar Postman para invocar al método POST. Hay que tener en cuenta que para invocar el endpoint, tenemos que incluir una cabecera específica del DataFlow:

Su valor será el que esté configurado en el componente REST, concretamente en el campo «Applicaton ID». Este campo es un «secret» que debe mantenerse en secreto. Y por supuesto, para algo que no sea una mera prueba como esta, tenemos que usar un valor pseudo aleatorio y lo suficientemente largo. Cuando mandemos un valor correcto, el resultado será un 200:
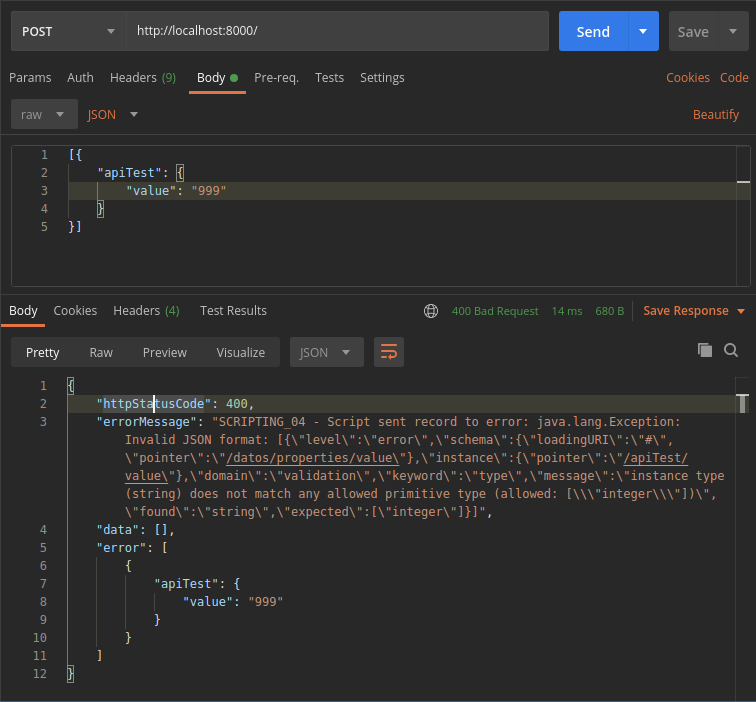
Si mandamos un dato incorrecto, el resultado será un error con código 400 (Bad Request), e incluirá la descripción del error:
Añadiendo autenticación y autorización
Ya hemos visto cómo podemos disponibilizar un método REST para insertar en Kafka usando el DataFlow y que, por defecto, se dispone de un «secret» para autorizar este método. En la mayoría de los escenarios, esto no será suficiente. Para usar los mecanismos estándar de autenticación y autorización de la Plataforma, bastará con integrar este método REST en el API Manager de Control Panel.
Para integrar APIs en el API manager, hacemos uso del estándar Open API, por lo que basta con describir nuestra API con dicho estándar. El siguiente ejemplo sería un ejemplo válido para nuestra API:
openapi: "3.0.0"
info:
title: "Platform API Manager"
description: "Platform - testAPI - v1"
contact:
name: "Platform Team"
url: "https://dev.onesaitplatform.com"
email: "support@onesaitplatform.com"
license:
name: "1.0.0"
url: "http://www.apache.org/licenses/LICENSE-2.0.html"
version: "Apache 2.0 License"
servers:
- url: http://streamsets:8000
description: "Rest to Kafka"
paths:
/:
post:
summary: Insert new data
description: Insert new data into kafka. The data format will be validated with the apiTest ontology
operationId: postApiTest
parameters:
- name: X-SDC-APPLICATION-ID
in: header
description: Streamsets X-SDC-APPLICATION-ID header
required: true
schema:
type: string
requestBody:
content:
application/json:
schema:
type: object
required: true
responses:
200:
description: New data inserted
400:
description: Bad request
403:
description: Not authorized
500:
description: Error processing request
A continuación podemos ver el resto de campos de la API configurados:
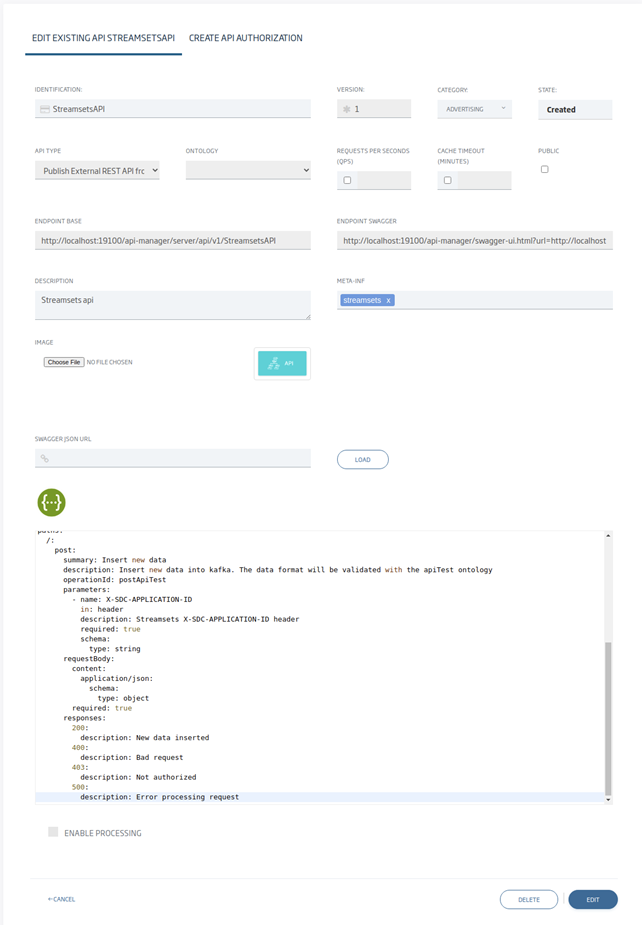
Una vez creado, ya estaría listo para usarse desde cualquier sitio con acceso al API Manager. En la mayoría de las instalaciones, el API Manager se configura con acceso externo mediante HTTPS, por lo que el API se podría usar desde otros sistemas de forma segura. En este ejemplo, se está haciendo todo en local y sin HTTPS.
Veamos como usar el API desde el Swagger del propio API Manager, para confirmar que se ha integrado correctamente:
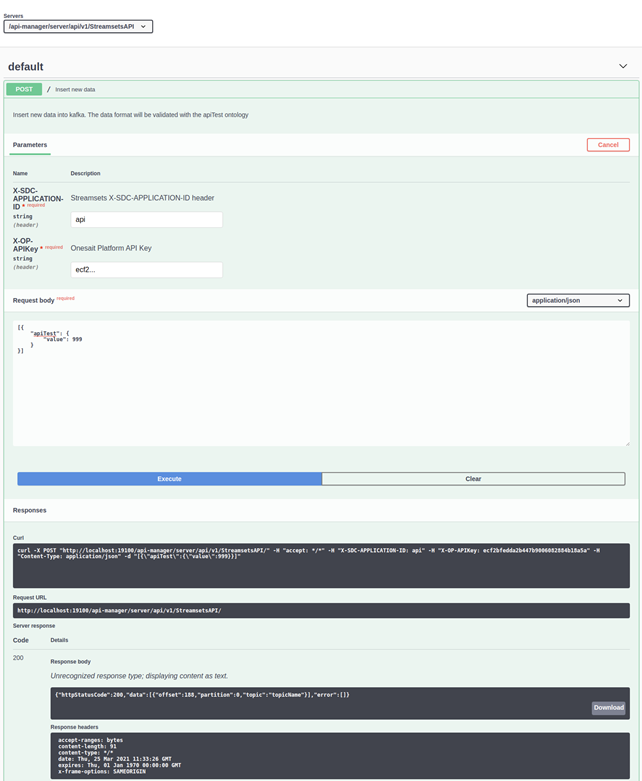
Como podemos observar, para usar este método ahora nos haría falta utilizar el token de usuario X-OP-APIKey o, si se prefiere, un token Oauth 2.0 como con cualquier otro API de la Platforma.
Conclusiones
Como hemos podido ver, de forma muy sencilla hemos expuesto un método REST para insertar datos en un topic Kafka validando los datos antes de insertarlos, pero se podría hacer de forma similar sobre cualquier otro destino.
Para validar los datos hemos usado el esquema de una ontología definida en la Onesait Platform. Para el ejemplo con Kafka, se podría usar también un esquema Avro definido para Kafka, pero si se usa otro destino, esa posibilidad no está disponible. Para exponer de forma segura el API, hemos usado el API Manager de la Onesait Platform. De la misma forma, cualquier otro API que se cree dentro de la Plataforma, o un Microservicio desplegado junto con la Onesait Platform, se puede exponer de forma similar.


