
Schema Registry
Cuando se usa un broker de mensajería como por ejemplo Kafka, no se realiza ninguna verificación de los datos a nivel de clúster; de hecho ni siquiera sabe que tipo de datos se están enviando o recibiendo pues la transferencia de datos se hace en formato de bytes.
Imaginemos que un publicador de mensajes (producer) comenzara a enviar datos incorrectos a nuestro topic o cambiara el tipo de datos de éste. ¿Qué ocurriría? Los consumidores (consumers) que están atendiendo a ese topic empezarían a fallar, por lo que sería necesario una forma de acordar los datos que se envían y se reciben.
De este problema nace la solución: Schema Registry. Se trata de una aplicación que reside fuera del clúster de Kafka y maneja la distribución de esquemas (y sus versiones) a los producers y consumers de mensajes almacenando estos esquemas en una caché local.
Funcionamiento
Añadiendo Schema Registry, el productor, antes de enviar los datos a Kafka contacta con el Schema Registry y verifica que el esquema esté disponible. En caso de no encontrarlo, lo registra y lo almacena en caché y, una vez que el productor obtiene el esquema, serializará los datos con el esquema y lo enviará a Kafka en formato binario junto al identificador del esquema único. Cuando el consumidor interpreta este mensaje, se comunicará con el Schema Registry utilizando el identificador del esquema que recibió del productor, y lo des-serializará utilizando el mismo esquema. En caso de haber discrepancia, se producirá un error, que comunicará al productor que está incumpliendo el acuerdo del esquema.
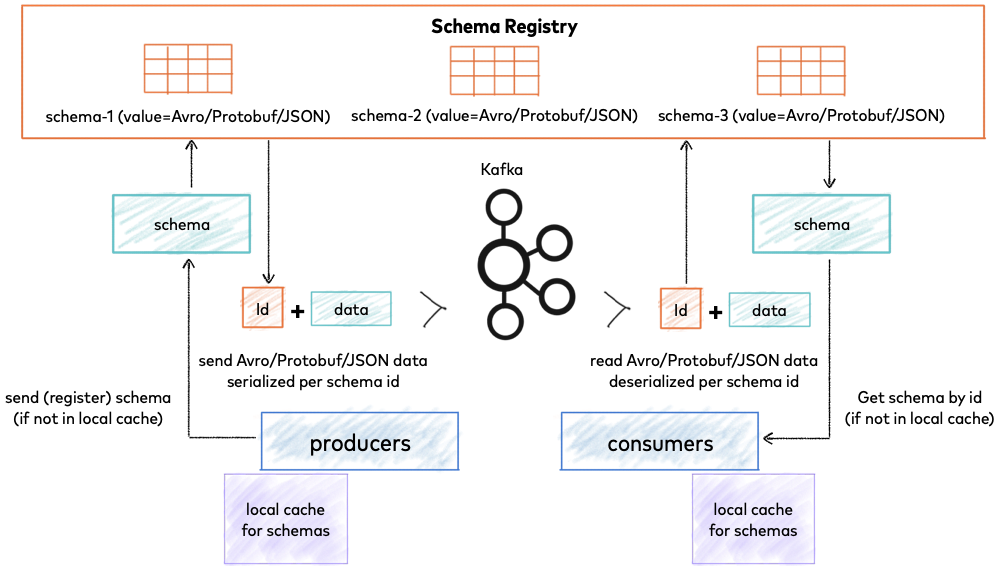
Gracias a este componente, facilitamos el cambio e incrementamos la agilidad de éste ya que podemos añadir, eliminar y modificar campos teniendo una garantía gracias al versionado. Además los cambios producidos en los esquemas de nuestra aplicación estarán cacheados, por tanto también es eficiente.
Evolución y compatibilidad
Cuando hablamos de la evolución de un esquema, es importante tener en cuenta la gestión de los datos. Una vez se define el esquema inicial, es bastante posible que las aplicaciones deban evolucionarlo tras un tiempo. Cuando este sucede, es necesario para los consumidores poder manejar los datos con el esquema nuevo y antiguo sin problemas.
La compatibilidad de los esquemas es verificada mediante la versión de cada uno. El tipo de compatibilidad determina como Schema Registry compara el nuevo esquema con versiones anteriores para un topic determinado. Cuando se crea un esquema por primera vez, se obtiene una identificación única y se obtiene un número de versión, que en este caso sería la 1. Al actualizarse el esquema, pasando las verificaciones de compatibilidad según el tipo asignado, obtiene una nueva identificación única y se incrementa el número de versión, que en este caso sería la 2. Ellada
A continuación veremos los tipos de compatibilidad contemplados.
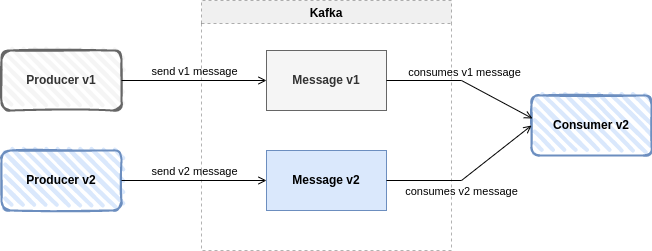
Compatibilidad Backward
Significa que los consumidores que utilizan el nuevo esquema pueden leer los datos generados con el último esquema. Se usa cuando se quieren actualizar consumidores pero todavía hay productores que no se van a actualizar. Traduciéndolo a versiones, los consumidores utilizarían el esquema nuevo en la versión 2 y los productores utilizarían el antiguo en la versión 1.
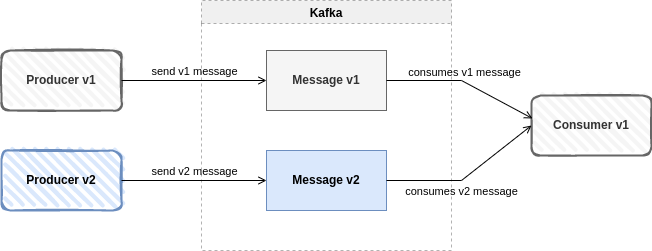
Compatibilidad Forward
Significa que los consumidores pueden leer los datos producidos con un nuevo esquema utilizando el último esquema, aunque no puedan utilizar todas las capacidades del nuevo esquema. Se trata del patrón más común, cuando se quiere actualizar un productor porque se necesitan incorporar nuevos datos, pero los consumidores no cambian. Traduciéndolo a versiones, los consumidores seguirían consumiendo la versión 1 mientras que el productor trabajaría con el esquema en la versión 2.
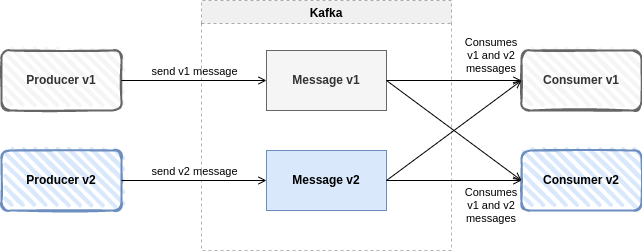
Compatibilidad Full
Une los dos anteriores. Los esquemas evolucionan de una manera totalmente compatible: los datos antiguos se pueden leer con el nuevo esquema y los nuevos datos también se pueden leer con el último esquema. Se trata del patrón que deberíamos buscar siempre, en el que queremos actualizar los datos y se pueden actualizar tanto consumidores como productores.
Sin verificación de compatibilidad
La compatibilidad NONE significa que las comprobaciones de compatibilidad están deshabilitadas. Este patrón conviene evitarlo, aunque a veces no es posible.
Resumen
| Tipo de compatibilidad | Cambios permitidos | Verificación de los esquemas | Qué actualizar primero |
|---|---|---|---|
| BACKWARD | Borrar campos Añadir campos opcionales | Última versión | Consumers |
| BACKWARD_TRANSITIVE | Borrar campos Añadir campos opcionales | Todas las versiones previas | Consumers |
| FORWARD | Añadir campos Borrar campos opcionales | Última versión | Producers |
| FORWARD_TRANSITIVE | Añadir campos Borrar campos opcionales | Todas las versiones previas | Producers |
| FULL | Añadir campos Borrar campos opcionales | Última versión | Cualquier orden |
| FULL_TRANSITIVE | Añadir campos Borrar campos opcionales | Todas las versiones previas | Cualquier orden |
| NONE | Todos los cambios están permitidos | Deshabilitado | Depende |
Conclusiones
- Para aplicaciones asíncronas, se hace imprescindible su uso para la gestión de los datos y evolución de los esquemas.
- Ayuda a gobernar los cambios en los datos que se manejan entre productores y consumidores, garantizando la compatibilidad entre estos y evitando errores.
- Mantiene un versionado entre distintos esquemas que permite evolucionar de una forma ordenada los componentes del sistema.
Imagen de cabecera: John Mark Arnold en Unsplash


