
Schema Registry
When using a messaging broker such as Kafka, no data verification is performed at the cluster level; in fact, it doesn’t even know what type of data is being sent or received, since the data transfer is done in byte format.
Let’s imagine that a message publisher (a producer) started sending incorrect data to our topic or changed its data type. What would happen? The consumers that are serving that topic would start to fail, so we need a way of agreeing on the data that is sent and received.
The solution is born from this problem: Schema Registry. It is an application that resides outside of the Kafka cluster and handles the distribution of schemas (and their versions) to message producers and consumers, by storing these schemas in a local cache.
Operation
Adding the Schema Registry, the producer, before sending the data to Kafka contacts the Schema Registry and verifies that the schema is available. If it cannot find the schema, it logs and caches it and, once the producer gets the schema, it will serialize the data with the schema and send it to Kafka in binary format, along with the unique schema identifier. When the consumer interprets this message, it will communicate with the Schema Registry using the schema identifier it received from the producer, and deserialize it using the same schema. In the event of a discrepancy, an error will notify the producer that the scheme agreement is been breached.
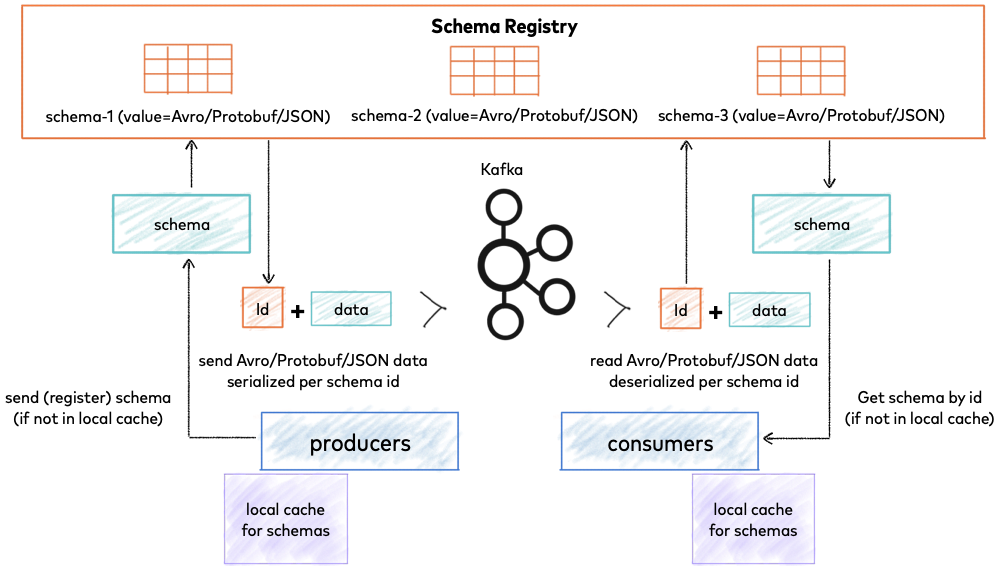
Thanks to this component, we facilitate the exchange and we increase its agility, since we can add, delete and modify fields with guarantee thanks to versioning. In addition, the changes produced in the schemes of our application, will be cached, therefore this is also efficient.
Evolution and compatibility
When we talk about the evolution of a scheme, it is important to take into account data management. Once the initial schema is defined, it is quite possible that applications will need to evolve it over time. When this happens, it is necessary for the consumers to be able to handle the data with both the new and old schema without problems.
The compatibility of the schemes is verified by the version of each one. The compatibility type determines how the Schema Registry compares the new schema with previous versions for a given topic. When a schema is first created, it gets a unique id and a version number, which in this case would be 1. When the schema is updated, passing compatibility checks depending on the assigned type, it gets a new unique id and the version number is incremented, which in this case would be to 2.
We will see next the types of compatibility contemplated.
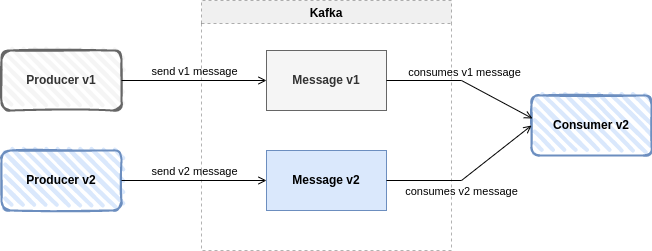
Backward compatibility
It means that consumers using the new schema can read the data generated with the latest schema. It is used when you want to update consumers, but there are still producers that are not going to be updated. By translating it into versions, consumers would use the new schema in version 2, and producers would use the old schema in version 1.
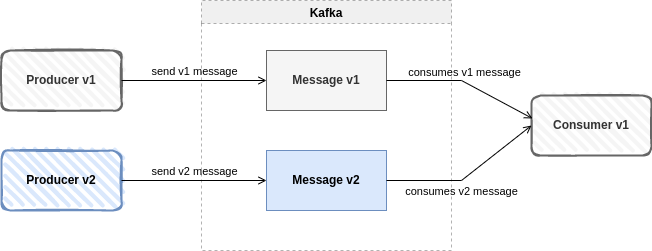
Forward Compatibility
It means that consumers can read data produced with a new schema using the latest schema, even though they cannot use the full capabilities of the new schema. This is the most common pattern, when you want to update a producer because new data needs to be added, but the consumers do not change. By translating it to versions, consumers would continue to consume version 1 while the producer would work with the schema in version 2.
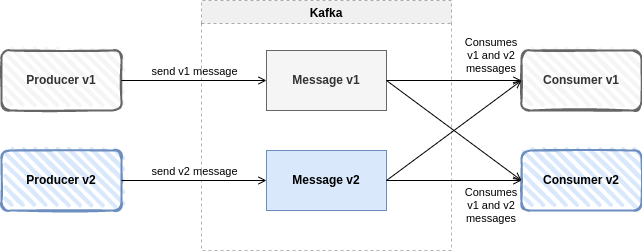
Full compatibility
It combines the two above. Schemas evolve in a fully compatible way: old data can be read with the new schema, and new data can also be read with the latest schema. This is the pattern we should always look for, where we want to update the data, and both consumers and producers can be updated.
No compatibility check
So-called NONE compatibility means that compatibility checks are disabled. This pattern should be avoided, although sometimes this is not possible.
Summary
| Compatibility type | Changes allowed | Schema verification | What to update first |
|---|---|---|---|
| BACKWARD | Delete fields Add optional fields | Latest version | Consumers |
| BACKWARD_TRANSITIVE | Delete fields Add optional fields | All previous versions | Consumers |
| FORWARD | Add fields Delete optional fields | Latest version | Producers |
| FORWARD_TRANSITIVE | Add fields Delete optional fields | All previous versions | Producers |
| FULL | Add fields Delete optional fields | Latest version | Any order |
| FULL_TRANSITIVE | Add fields Delete optional fields | All previous versions | Any order |
| NONE | Todos los cambios están permitidos | Disabled | Depends |
Conclusions
- For asynchronous applications, its use is essential for data management and schema evolution.
- It helps to govern the changes in the data that are handled between producers and consumers, guaranteeing compatibility between them, and avoiding errors.
- It maintains a versioning between different schemas, allowing the system components to evolve in an orderly manner.
Header image: John Mark Arnold at Unsplash



Pingback: Release 4.3.0-Quest for Onesait Platform – Onesait Platform Community