
Kafka Connect
Kafka Connect es un componente Open Source de Apache Kafka que funciona como un centro de datos centralizado para una integración de datos simple entre bases de datos, almacenes de clave-valor, índices de búsqueda y sistemas de archivos.
Hasta el momento ofrece las siguientes ventajas:
- Pipelines centrados en los datos: utiliza abstracciones de datos útiles y completas para consumir o crear datos en Kafka.
- Flexibilidad y escalabilidad: se ejecuta con sistemas orientados al streaming y a los lotes (batch-oriented) en un solo nodo (standalone) o escalado a un servicio para toda la organización (distribuido).
- Reutilización y extensibilidad: aprovecha los conectores existentes o los amplía para adaptarse a sus necesidades y proporcionar un menor tiempo de producción.
Kafka Connect se centra en la transmisión de datos desde y hacia Kafka, lo que simplifica la escritura de plugins de conectores de alta calidad, fiables y de alto rendimiento. Kafka Connect también permite que el marco de trabajo ofrezca garantías que son difíciles de conseguir utilizando otros marcos de trabajo.
¿Cómo funciona?
Kafka Connect se puede desplegar como un proceso independiente (standalone) que se ejecuta en una sola máquina (por ejemplo, la recogida de registros de una tabla), o como un servicio distribuido (distributed), escalable y tolerante a fallos que da soporte a toda una organización. Además, ofrece una baja barrera de entrada y una baja sobrecarga operativa. Se puede empezar con un entorno independiente para el desarrollo y las pruebas, y luego escalar a un entorno de producción completo para soportar la canalización de datos de una gran organización.
Incluye dos tipos de conectores:
- Source connector: ingieren bases de datos enteras y transmiten las actualizaciones de las tablas a los topics de Kafka. Habitualmente este proceso se realiza a través del mecanismo de CDC (Change Data Capture) de las bases de datos. También pueden recopilar métricas de todos sus servidores de aplicaciones y almacenar los datos en topics de Kafka, haciendo que los datos estén disponibles para el procesamiento streams con baja latencia.
- Sink connector: envían los datos de los topics de Kafka a otros sistemas de gestión de datos, como Elasticsearch, o a sistemas de batch, como Hadoop, para su análisis fuera de línea.
Habitualmente Kafka Connect viene integrado dentro de una instalación de Kafka con lo mínimo y necesario para arrancarlo. Únicamente hay que ejecutar el script de inicialización de este sistema para poder hacer uso de él, siempre y cuando Kafka esté funcionando de forma correcta. Posteriormente lo normal sería configurar los conectores adecuadamente según se necesite, de forma standalone o distributed, además de instalar los plugins necesarios para funcionar con los distintos sistemas que se precise.
¿Cómo se usa?
En este apartado se podría profundizar muchísimo más, pero nos quedaremos con los conceptos básicos que necesitamos para entender como hacer funcionar Kafka Connect. Para un detalle más amplio recomendamos hacer uso de su extensa documentación.
Modo Standalone vs Distributed
Los conectores son unidades lógicas de trabajo que se ejecutan como un proceso. El proceso se llama worker en Kafka Connect y hay dos modos de ejecutarlos:
- Standalone: es útil para desarrollar y probar en una máquina local o en un entorno de desarrollo.
- Distributed: ejecuta los workers en varias máquinas (nodos), que forman un clúster. Kafka Connect distribuye los conectores en ejecución por el clúster. Puede añadir o eliminar nodos a medida que evolucionen sus necesidades a través de una API de forma sencilla.
Este modo también es más tolerante a los fallos. Por ejemplo, si un nodo abandona inesperadamente el clúster, Kafka Connect distribuye el trabajo de ese nodo a otros nodos del clúster. Además, como Kafka Connect almacena las configuraciones de los conectores, el estado y la información de compensación dentro del clúster de Kafka, donde se replica de forma segura, la pérdida del nodo donde se ejecuta un worker no supone ninguna pérdida de datos.
Instalación de plugins
Un plugin de Kafka Connect es un conjunto de archivos JAR que contienen la implementación de uno o más conectores, transformadores o convertidores. Kafka Connect se encarga de aislar cada plugin de los demás para que las bibliotecas de un plugin no se vean afectadas por las bibliotecas de otros. Esto es muy importante cuando se mezclan y combinan conectores de múltiples proveedores.
Pueden organizarse de las siguientes formas:
- Directorio: que contiene todos los archivos JAR necesarios y las dependencias de terceros para hacer funcionar el plugin. Esta forma es la más común y preferible.
- Archivo JAR único: que contiene todo lo necesario para hacer funcionar el plugin.
La forma de encontrar la localización de estos plugins es a través de la configuración de los propios workers a través de la variable plugin.path. Por ejemplo, en una instalación de Bitnami podrían estar ubicados en la siguiente localización:
plugin.path=/opt/bitnami/kafka/pluginsHay diferentes alternativas para conectores, entre las que destacamos las siguientes:
- Debezium: plataforma open source donde se pueden encontrar conectores para sistemas de gestión de base de datos relacionales y no relacionales. Incluye una extensa y detallada documentación sobre cada uno de los conectores y como hacerlos funcionar.
- MongoDB Kafka Connector: conector open source para MongoDB, verificado por Confluent.
- Confluent Hub: para cuando se usa Confluent como plataforma.
Arranque de workers
Previamente se ha explicado que hay dos modos de lanzar Kafka Connect: standalone y distributed. La diferencia para ejecutar un tipo de modo u otro es por lo general lanzar un script distinto dentro de la instalación de Kafka que indica en que modo se desea ejecutar Connect. Este script debe ser lanzado con una configuración concreta, pues según se haya elegido hay más variables que se deben incluir dentro de las propiedades configurables.
La diferencia radica en que en el modo standalone es necesario indicar por cada conector un archivo de propiedades que cargar, mientras que en el modo distributed simplemente se inicia y posteriormente a través de una API centralizada en un puerto concreto se van gestionando los conectores y sus configuraciones.
Suponiendo que hemos elegido una distribución de Bitnami, estos serían ejemplos válidos para cada tipo:
Modo Standalone
/opt/bitnami/kafka/bin/connect-standalone.sh worker.properties connector1.properties [connector2.properties connector3.properties...]Donde worker.properties contendría la configuración del worker en modo standalone y el/los archivo/s siguiente/s serían las configuraciones concretas de cada conector.
Modo Distributed
/opt/bitnami/kafka/bin/connect-distributed.sh worker.propertiesEn este caso solo sería necesario incluir la configuración del worker en modo distribuido. Incluye más opciones necesarias como definición de grupos, puerto y ruta donde se localizará la API, etc.
Ejemplo con MongoDB
Visto todo lo anterior ahora veamos un ejemplo práctico con MongoDB usando su conector oficial. Lo primero que necesitarás, por tanto, es tener una instancia de MongoDB, y en modo réplica dado que es un requerimiento necesario para los conectores de este tipo de base de datos.
Configuración del worker
En primer lugar hay que crear una simple configuración para poder arrancar el worker. Puedes hacerlo de forma sencilla con el modo standalone.
standalone-worker.properties
########################
# GLOBALES
########################
bootstrap.servers=<URL_DEL_BROKER_DE_KAFKA>:<PUERTO_DEL_BROKER_DE_KAFKA>
plugin.path=/opt/bitnami/kafka/plugins
########################
# SEGURIDAD
########################
# Sin seguridad óptima, para realizar pruebas en un entorno local
# Se recomienda configurar apropiadamente estas variables de seguridad para un entorno de desarrollo y productivo
sasl.mechanism=PLAIN
security.protocol=PLAINTEXT
consumer.sasl.mechanism=PLAIN
consumer.security.protocol=PLAINTEXT
########################
# CONVERSIONES
########################
# A nivel centralizado podemos definir como resolver las claves y los valores,
# pero también se puede indicar a nivel de conector
# key.converter=org.apache.kafka.connect.json.JsonConverter
# value.converter=org.apache.kafka.connect.json.JsonConverter
# key.converter.schemas.enable=true
# value.converter.schemas.enable=true
########################
# OFFSET SETUP
########################
offset.storage.file.filename=/tmp/connect.offsets
offset.flush.interval.ms=10000Configuración del conector
Vamos a añadir una configuración sencilla que escuche una colección concreta dentro de MongoDB y registre sus cambios.
mongodb-connector.properties
name=<NOMBRE_IDENTIFICATIVO_CONECTOR>
connection.uri=mongodb://<IP_MONGODB>:<PUERTO_MONGODB>/<COLECCION_MONGODB>
connector.class=com.mongodb.kafka.connect.MongoSourceConnector
database=<BASE_DE_DATOS_A_ESCUCHAR>
collection=<COLECCION_DE_LA_BASE_DE_DATOS_A_ESCUCHAR>
tasks.max=2
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.storage.StringConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
publish.full.document.only=false
pipeline=[{"$match":{"$or":[{"operationType":"insert"},{"operationType":"update"},{"operationType":"delete"}]}}]- Los valores de conversión se han definido como
StringConverterporque son más fáciles de procesar por Spring Boot que si sonJSONConverter. Hay distintos tipos clases de conversión y pueden usarse a gusto del consumidor. - Se ha indicado que queremos que no solo necesitamos que nos muestre el documento que ha cambiado. De esta forma podremos controlar los tipos de operaciones que se hacen sobre los documentos de MongoDB, mientras que de la otra forma solo veríamos el resultado del cambio.
- Se ha añadido un pipeline donde básicamente decimos que solo queremos escuchar operaciones de inserción, actualización y borrado. Dentro del pipeline pueden definirse muchos tipos de operaciones, siempre y cuando MongoDB lo permita.
Lanzando el worker
Una vez tenemos las configuraciones y la base de datos correctamente configurada es momento de lanzar Connect. Para ello usaremos el siguiente comando:
/opt/bitnami/kafka/bin/connect-standalone.sh $RUTA_FICHEROS_CONFIGURACION/standalone-worker.properties $RUTA_FICHEROS_CONFIGURACION/mongodb-connector.propertiesEsto iniciara el conector que pondrá en escucha continua a la colección especificada de MongoDB en este caso. Una vez se vayan procesando los cambios, los irá registrando en un topic. ¿Cuál es el nombre de este topic? Por defecto es <DATABASE_NAME>.<COLLECTION_NAME>.
Probando el conector
Ahora solo quedaría lanzar una petición a MongoDB y consumir el topic, por ejemplo desde un consumidor de consola con el siguiente comando:
/opt/bitnami/kafka/bin/kafka-console-consumer.sh --bootstrap-server <IP_BROKER_KAFKA>:<PUERTO> --topic <NOMBRE_BD>.<NOMBRE_COLECCION>Posteriormente lanzar una petición, por ejemplo desde un IDE como MongoDB Compass:
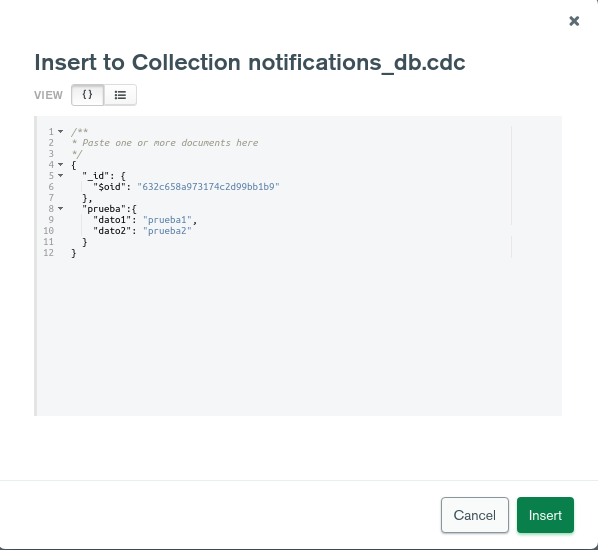
Y por último ver como efectivamente el conector registra este evento de inserción en el topic:
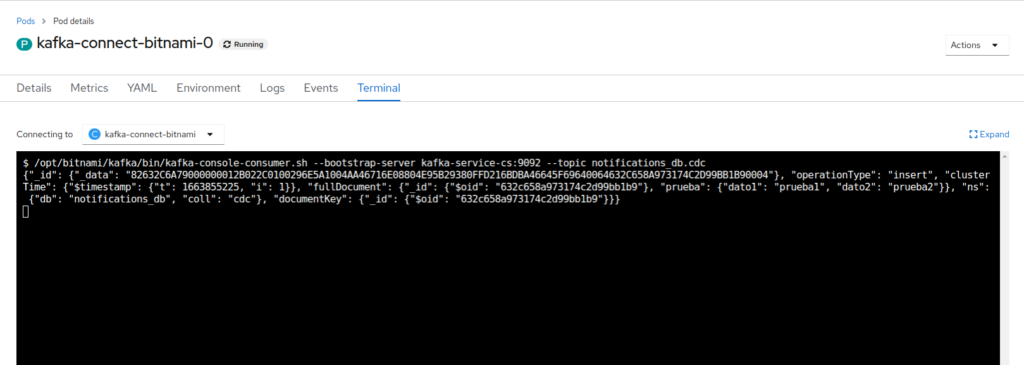
Como podemos observar, tal y como indicábamos en configuración, nos muestra información detallada sobre la operación que se ha realizado así como el documento generado. Este esquema cambia según el tipo de operación, así que hay que estar atentos a los eventos que se generan en Kafka a través del conector.
Conclusiones
Kafka Connect es una solución flexible, escalable, reutilizable y extensible que nos ayuda a monitorizar los cambios en nuestros datos y generar eventos con ellos, para luego tratarlos como se necesite. Encontramos ciertos escenarios de utilidad donde esta solución es bastante apropiada, como por ejemplo:
- Patrón Saga: para generar los eventos que permitan mantener la consistencia entre distintas entidades de forma óptima.
- Proceso de migración: útil para cuando tenemos un proceso de migración complejo y hay que mantener la consistencia de los datos entre las distintas entidades mientras se va completando la propia migración.
- Replicación de un sistema de persistencia para datos históricos desatendidamente.
- Envío de notificaciones cuando se produce un evento que se requiere monitorizar en tu base de datos, como por ejemplo la baja de un usuario.
Referencias
Imagen de cabecera: openlogic.com


