Gestión de archivos binarios en la Onesait Platform
La Onesait Platform cuenta con un sistema de gestión de archivos binarios basado en GridFS. Esta tecnología de MongoDB nos permite almacenar los ficheros en un único punto, accesible desde todos los contenedores Docker de la Plataforma. Además, al estar almacenado en la base de datos de MongoDB, podremos tener los binarios en alta disponibilidad si configuramos MongoDB en modo «replicaset».
Esta funcionalidad está accesible desde el Control Panel de la Plataforma, a través de la opción de menú Herramientas de Desarrollo > Mis Ficheros:

Accederemos al listado de archivos binarios, pudiendo crear uno nuevo utilizando el botón «Nuevo» y seleccionando el archivo de nuestro equipo que queremos almacenar:
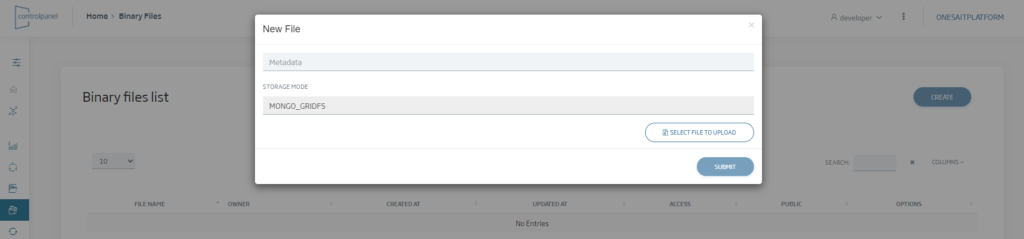
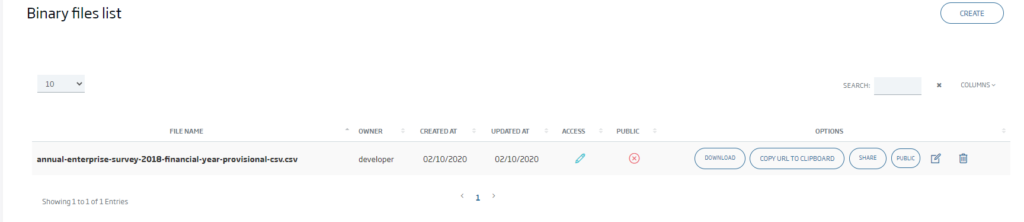
Una vez subido el fichero a la Plataforma, a través del propio listado de ficheros se puede:
- Descargar el fichero a través del botón «Descargar».
- Acceder al fichero mediante una URL de la Plataforma a través del botón «Copiar enlace».
- Dar permisos a otros usuarios sobre el archivo a través del botón «Compartir».
- Hacer público el archivo para que todos los usuarios de Plataforma tengan acceso a él a través del botón «Público».
- Modificar o eliminar el fichero a través de sus botones correspondientes.
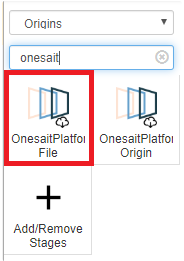
Desde la versión 2.1.0-gradius estos ficheros son accesibles también desde el Dataflow, ya que se incorporó un nuevo componente de tipo «Origin: OnesaitPlatform File».
Para utilizarlo, basta con acceder a la opción de menú Herramientas Analíticas > Gestión de Dataflows, crear un nuevo «Pipeline» y añadir dicho componente de la paleta.
Este componente cuenta con la siguiente configuración:
Conexión
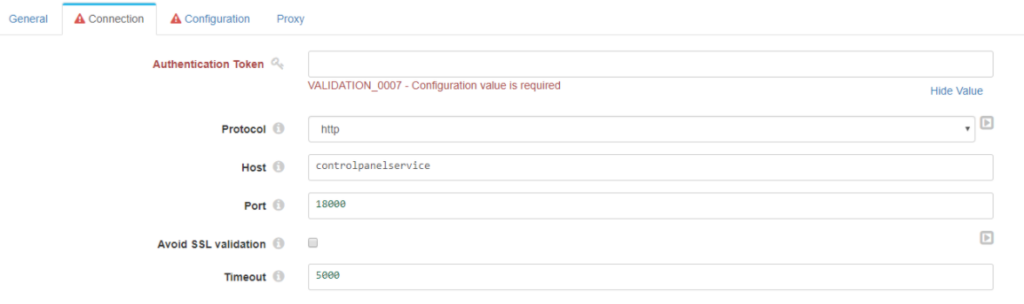
- Authorization: token OAuth del usuario. Es necesario que el usuario tenga permisos sobre el fichero que se quiere consultar.
- Protocol: si vamos a trabajar sobre HTTP o HTTPS.
- Host: por defecto será «controlpanelservice», ya que el DataFlow se conectará internamente con el Control Panel por su nombre de servicio. Si quisiéramos que el componente atacara a otro Control Panel, bastaría con poner aquí la IP.
- Post: puerto de conexión con el controlpanel. Por defecto 18000.
Configuración
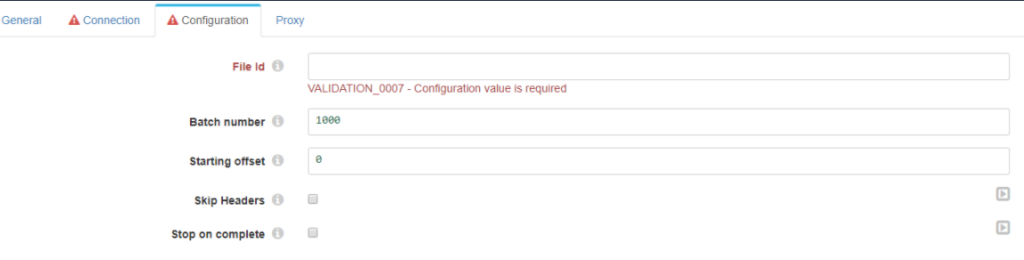
- File Id: id del fichero que se quiere leer.
- Batch number: número de líneas que se van a leer de cada vez.
- Starting offset: línea por la que se va a empezar a leer el fichero.
- Skip Headers: Si se quiere o no devolver el resultado con las cabeceras.
- Stop on complete: parar el pipeline una vez termine de leer el documento.
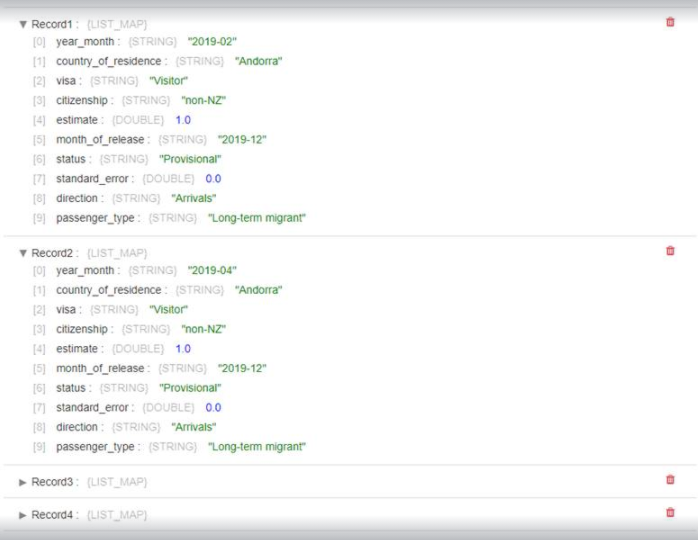
Resultado
A continuación se muestra el resultado de la ejecución de un pipeline que lee el fichero incluyendo las cabeceras:
En el siguiente enlace puedes ver un videotutorial de cómo funciona esta herramienta y cómo leer archivos desde un Pipeline del DataFlow.
Esperamos que encuentres útil esta herramienta y si tienes alguna inquietud o sugerencia, ¡no dudes en dejarnos un comentario!