Buenas prácticas en Grafana
Grafana es la G del stack EFG (Elasticsearch-Fluentd-Grafana). Una vez que un artefacto envía trazas de logs a Fluentd, quien filtra y transforma dichos datos, los mismos son indexados en Elasticsearch. Grafana se encarga de consumir las trazas de Elasticsearch para monitorizar en un entorno gráfico muy avanzado y con múltiples posibilidades.
La configuración básica de Grafana en Kubernetes se puede encontrar en el artículo sobre Configuración en Kubernetes que escribimos previamente.
En esta entrada vamos a hablar de algunas de las posibilidades básicas que ofrece Grafana. En todo momento se describen escenarios reales que se han dado durante el trabajo llevado a cabo en 2020Q3-4.
Escenario de estudio
Se asume que Grafana está correctamente instalado y corriendo en un servidor. En esta documentación se explica cómo hacerlo correr en Kubernetes.
Se asume un escenario en el que se han indexado en Elasticsearch, previo paso por Fluentd, logs estructurados en formato JSON. El trabajo realizado para que los logs queden correctamente indexados y parseados en Elasticsearch se asume como conocido. Los artículos que explican las configuraciones en las que dicho flujo llega a Elasticsearch son:
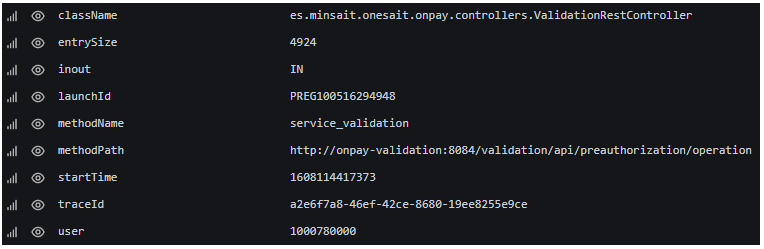
Cada uno de los campos de la estructura JSON representan una clave en la traza básica indexada en Elasticsearch. Veámoslo en un ejemplo básico desgranando el input y output.
Input
En este ejemplo se supone que hemos enviado desde un artefacto Springboot vía Fluentd a Elasticsearch la siguiente traza:
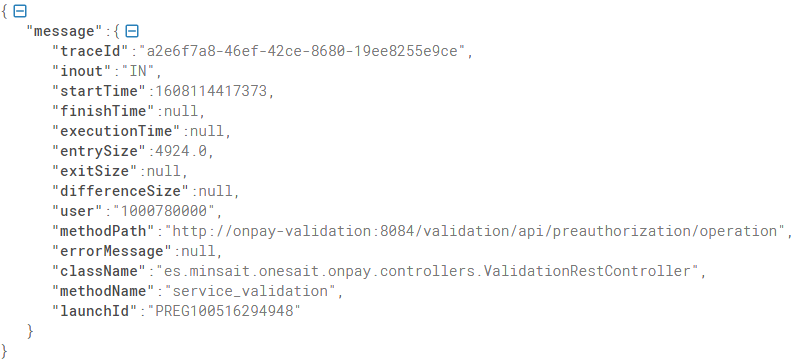
Output
En Grafana, el ejemplo de la traza anterior se visualizaría de la siguiente forma:
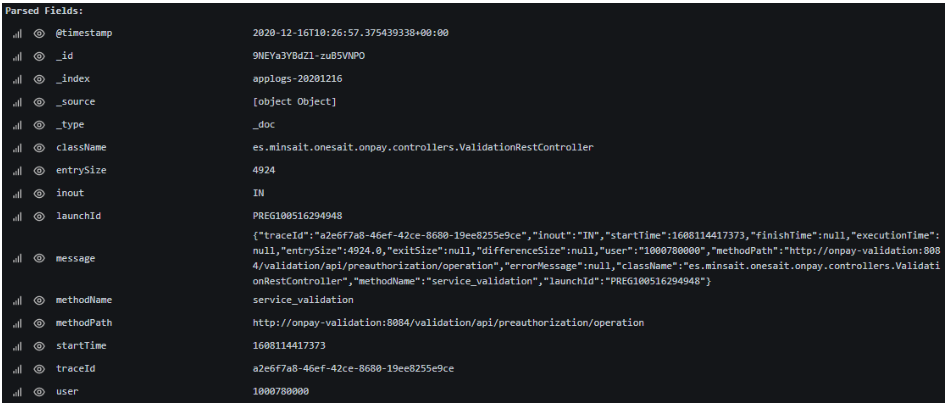
Podemos observar tres partes:
- Metainformación: información de control e identificación indexada por Fluentd y Elasticsearch.
- Mensaje original: es el texto en JSON que se genera en el artefacto Java y que se conserva hasta el final. Cabe mencionar que Fluentd puede hacer que el mensaje en el formato original no se indexe en Elasticsearch.

- Campos parseados: como hemos dicho, cada campo del mensaje original es parseado y almacenado independientemente en la traza de Elasticsearch. Esto es lo que luego nos permitirá hacer búsquedas, mostrar resultados, agrupar, etc.
Datasource
Como es lógico, a nuestro aplicativo Grafana debemos decirle dónde debe buscar el origen de los datos. Grafana permite multitud de Datasources, pero nosotros nos centramos en Elasticsearch, como elemento básico de nuestro stack EFG.
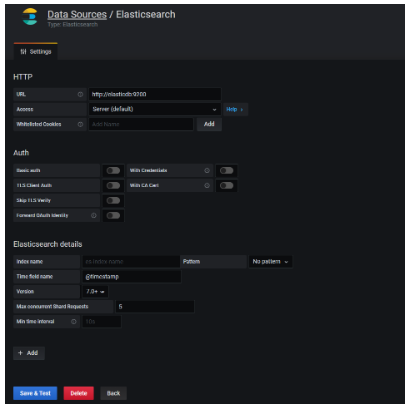
Para configurar el datasource, debemos seguir estos pasos:
- Configuración > Data Sources.
- Click en botón «Add Datasource».
- Seleccionamos Elasticsearch.
- Rellenamos los datos de nuestro servidor Elasticsearch. Los más importantes son:
- HTTP: por defecto: http://elasticsearch-host:9200
- Auth: credenciales de seguridad, si las tuviese.
- Elastic details: en este cuadro es muy importante especificar correctamente la versión de Elasticsearch a la que va a atacar Grafana.
- Una vez rellenos todos los datos básicos, click en «Save & Test».
Dashboards
Un Dashboard es un conjunto de paneles visuales que muestran diferentes juegos de la información de forma gráfica. En Grafana los dashboards gráficos son muy versátiles, permitiendo crearlos y agruparlos de diferentes formas, así como añadir varios gráficos a los mismos.
Como extensión de la sección «Explore», que veremos después, es una de las características más potentes de la herramienta, ya que te permite crear configuraciones fijas de gráficos que proporcionan la información deseada en un simple vistazo, además la posibilidad de crear «playlists» (paneles que van rotando automáticamente) o «snapshots».
El manejo visual de los dashboards es lo suficientemente intuitivo como para no necesitar una explicación adicional. Como decíamos, esa versatilidad es uno de sus fuertes, pero la verdadera potencia reside en el motor que tiene por debajo, el generador de queries, que es de donde salen los datos que se muestran en los dashboards. Esto es lo que vamos a ver extensamente en la siguiente sección.
Exportación
Los dashboards son especialmente útiles cuando queremos exportar los datos a Excel, CSV, etc.
Para hacerlo, hay que seguir los siguientes pasos:
- Pulsar sobre el título del panel que representa los datos a exportar.
- Seleccionar Inspect > Data.
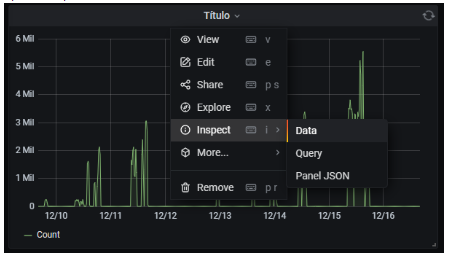
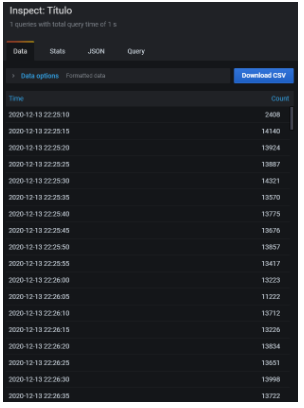
- En el panel que aparece a la derecha, seleccionar el formato en el que se quiere exportar y pulsaremos en «Download CSV».
Explore
Como decimos, la potencia de Grafana reside en el generador de queries, que se encuentra en la sección Explore. Cabe aclarar que lo mismo que encontramos en Explore lo encontraremos también en la parte de los dashboards, pero podemos considerar Explore como un «campo de entrenamiento» con el que generar queries que luego llevaremos al dashboard para montar las representaciones visuales deseadas.
Por defecto, la herramienta Explore se carga con una búsqueda general que muestra los resultados en los formatos Histograma y Tabla para las muestras de la última hora.
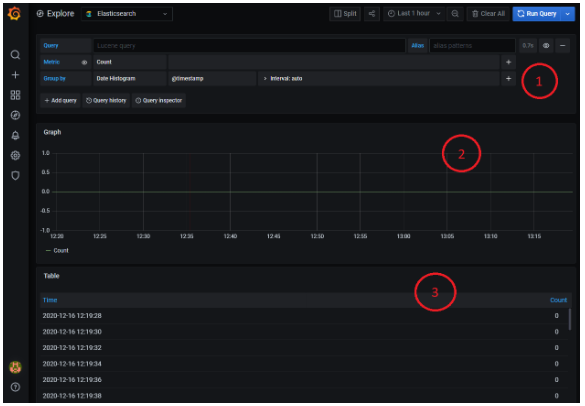
Analizamos las diferentes partes de la imagen:
- En la esquina superior derecha está el rango de tiempo para el que se configura la búsqueda. El mismo se puede seleccionar a través del propio selector de la parte superior de la pantalla o bien seleccionando con el ratón un rango en el histograma.
- A la izquierda del selector de rango temporal, hay un botón que permite dividir la pantalla en dos, lo que es útil para comparar dos queries.
- El área rotulada con un «1» representa el generador de queries como tal. Un poco más adelante entramos en su detalle.
- El área rotulada con un «2*» es la representación gráfica en histograma de la muestra solicitada. En este caso inicial, es una simple cuenta de trazas por unidad de tiempo.
- El área rotulada con un «3*» es la representación en forma de tabla del mismo resultado. Cada fila representa en este caso las trazas cada 20 centésimas.
- Los paneles de resultados (2 y 3) cambian su formato y layout en función de qué información sea solicitada en el generador de queries. No se representa de igual forma las trazas de logs, que un panel de tiempos que un histograma. Lo veremos un poco más en detalle cuando hablemos del generador de queries.
* Nótese que la imagen representa una búsqueda que no ha obtenido resultados.
Generador de queries
El generador de queries es la parte superior de la pantalla. En él se configuran las búsquedas como tal. El mismo está compuesto por:
- Query: permite introducir queries sobre los campos indexados en Elasticsearch. La sintaxis es la descrita por el proyecto Apache Lucene (Query Parser Syntax).
Volvamos al ejemplo en el que tenemos los siguientes campos mapeados:
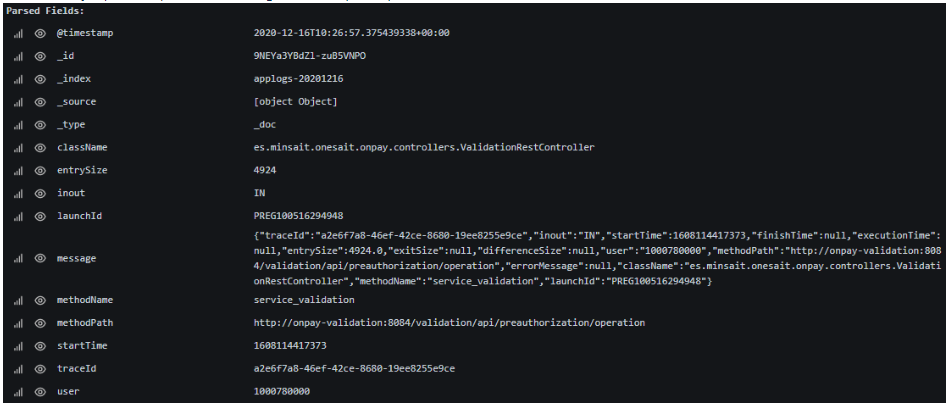
Una posible query a introducir en el campo Query, que obtendría la traza de la imagen, entre posiblemente muchas otras es:
launchId:PREG100516294948 AND startTime:[1608114410000 TO 1681608114420000]
- Metric: en este campo se selecciona la métrica que queremos representar, a aplicar sobre los datos que se obtengan de la query. Los diferentes valores son los de la siguiente imagen. A continuación, detallamos los más utilizados:
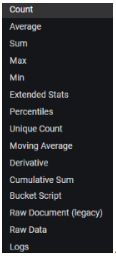
Aquellos que se aplican sobre campos numéricos requieren la selección adicional del campo sobre el que se quiere aplicar la métrica. Por ejemplo, si se selecciona Average, se habilitará un campo a la derecha de este en el que se da a elegir entre los diferentes campos numéricos que se encuentran en la traza indexada.
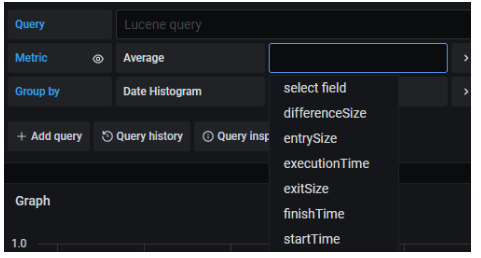
Una excepción es el valor Count (el primero de la lista), que no requiere seleccionar el campo adicional, ya que se trata de contabilizar por unidad de tiempo el número de trazas encontradas según la query especificada en Query.
Otro de los valores relevantes que se pueden escoger en el campo Metric es «Logs». Este es el valor que hay que seleccionar si queremos entrar en el contenido completo de las trazas. Por aclararlo, en este artículo hay una imagen recurrente a la que acudimos frecuentemente. Pues bien, dicha imagen es el detalle de una traza completa, y se obtiene poniendo el mencionado valor «Logs» en el campo Metric. Como se ve en la imagen a continuación, se obtiene un listado estructurado de todas* las trazas que cumplen una determinada query y, al pulsar sobre una de ellas, se despliega el detalle de la misma:
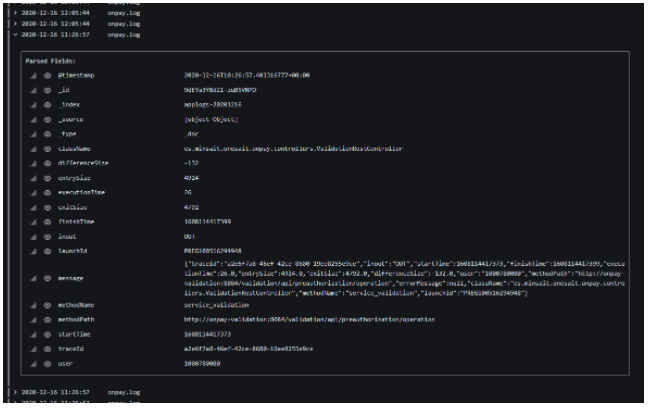
* Quede claro que esta visualización en formato «Logs» tiene un límite establecido. Para ver cualquier traza, hay que encontrarla acotando correctamente la búsqueda en el campo Query.
- Group by: la mayoría de las métricas que se pueden seleccionar según lo explicado en el punto anterior, por defecto tienen un output en forma de histograma (puntos por unidad de tiempo):
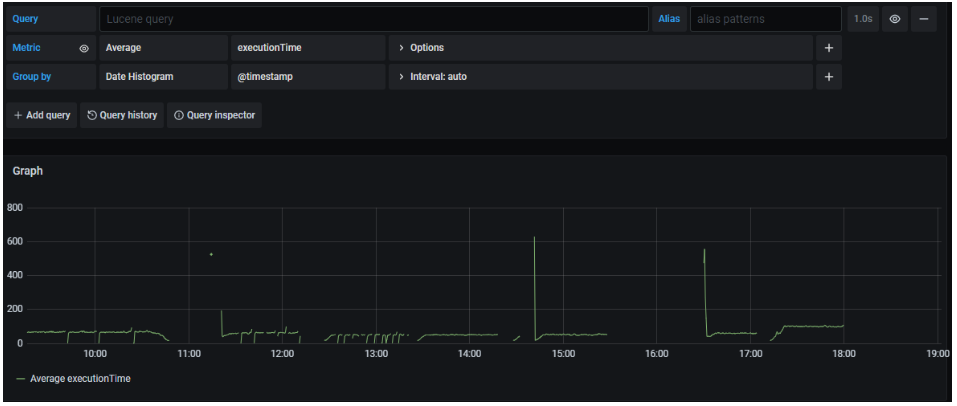
El campo Group by permite agrupar esos valores obtenidos en base a un criterio de agrupación.
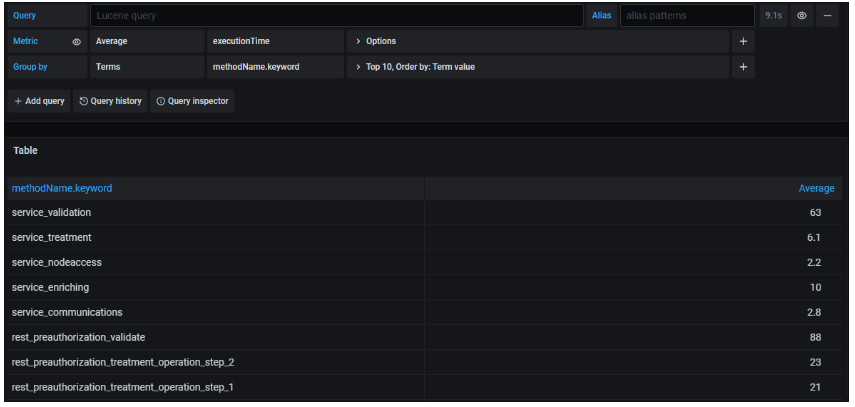
En la imagen anterior podemos ver cómo los valores obtenidos para la media (average) del campo executionTime ya no están plasmados en un histograma, sino que en su lugar se muestra una tabla. Cada fila representa un valor distinto del campo seleccionado para agrupar (methodName.keyword), estableciendo para cada uno de ellos cuál es la media de executionTime.
Tanto executionTime como methodName son dos claves existentes en cada traza indexada en Elasticsearch.
El generador de queries tiene muchas posibles configuraciones más, como la visualización del histórico de queries, el inspector y numerosas opciones según las métricas y agrupaciones escogidas. También permite crear varias queries (+ Add query), que mostrarían sucesivamente varios paneles de resultados (uno por cada query configurada).
Imagen de cabecera: Grafana.