Programación reactiva: Spring WebFlux
La programación reactiva es un paradigma de la programación enfocado en el trabajo de datos finitos o infinitos de forma asíncrona. Los sistemas que se desarrollen bajo este tipo de programación cumplen una serie de requisitos, por lo que tienen que ser:
- Responsivos: deben asegurar la calidad del servicio cumpliendo unos tiempos de respuesta establecidos.
- Resilientes: deben mantenerse responsivos incluso en casos de error.
- Elásticos: deben mantenerse responsivos incluso en casos de aumento de carga de trabajo.
- Orientados a mensajes: deben minimizar el acoplamiento entre componentes para las interacciones de manera asíncrona.
Beneficios
El uso de este tipo de programación nos proporciona las siguientes ventajas en nuestros desarrollos:
- Escalabildad: el uso de la programación reactiva nos permite mantener implementaciones débilmente acopladas entre ellas de modo que haya un mejor aislamiento a los fallos. Esto nos permite añadir o quitar nuevos módulos de forma sencilla gracias al desacoplamiento generado.
- Ahorro: la programación reactiva está desarrollada de modo que se haga un mejor uso de los recursos disponibles, dado que son liberados con mayor rapidez para su posterior uso en las nuevas peticiones entrantes.
¿Cómo implementarla en nuestros proyectos?
Para poder hacer uso de las funcionalidades de la programación reactiva dentro de nuestros proyectos Spring podemos hacer uso del framework de Spring Webflux, con las funcionalidades para el desarrollo de aplicaciones basadas en este tipo de programación.
Spring WebFlux
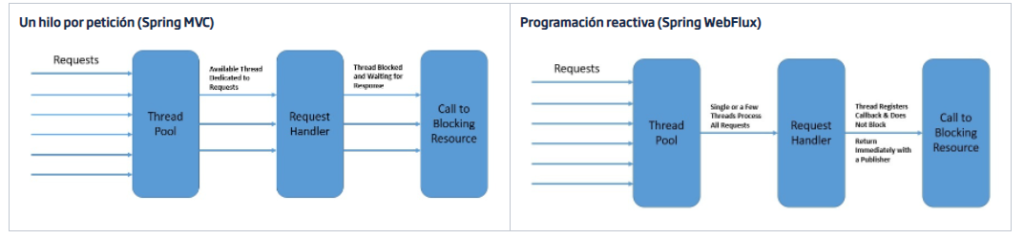
Spring WebFlux es un framework web reactivo desarrollado por Spring para la creación de aplicaciones basadas en el paradigma de la programación reactiva. Coexiste junto a Spring MVC ya que cada módulo es opcional, por lo que las aplicaciones pueden usar tanto cada framework por separado como junto, ya que uno puede utilizar funcionalidades del otro.
Este framework cambia la forma de trabajar con los hilos de modo que mientras que Spring MVC hace uso de hilos bloqueantes (una petición ocupa un hilo y lo bloquea hasta que este termina su ejecución y lo libera), en Spring WebFlux un hilo almacena y puede ejecutar una o varias peticiones a la vez, devolviendo un publisher el cual devolverá los datos cuando ocurran, en vez de mantener el hilo bloqueado esperando la respuesta.
Para incluir Spring Webflux dentro de nuestros proyectos basta con añadir las siguientes dependencias en el pom.xml:
<!-- En el caso de que nuestro proyecto sea una librería -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webflux</artifactId>
</dependency>
<!-- En el caso de que nuestro proyecto sea un módulo-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>Spring WebFlux vs Spring MVC
Como se ha comentado previamente, Spring WebFlux ha sido desarrollado para coexistir junto a Spring MVC. Las funcionalidades que ambos presentan están diseñadas para poder trabajar complementariamente aprovechando las ventajas y funcionalidades que ambos nos pueden ofrecer.
En el siguiente diagrama podemos ver que tienen ambos modelos en común y que les hace únicos con respecto al otro:
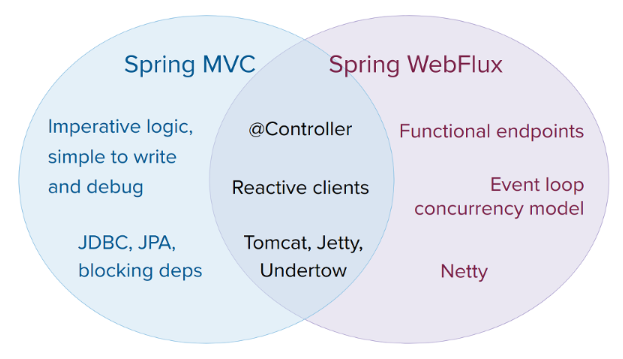
La dos principales diferencias que existen entre ambos son:
- El modo de programar: ya que con Spring MVC la lógica es imperativa y más fácil de desarrollar, mientras que Spring WebFlux aprovecha las ventajas de las lambda de Java 8 (o Kotlin) para utilizar un lenguaje más funcional.
- El modo de trabajar: como se ha comentado en la introducción, una de las novedades que incluye Spring WebFlux es el modo de trabajar con los hilos del programa, ya que mientras que en Spring MVC se utilizaba un hilo para cada petición y este quedaba bloqueado a la espera de que dicha petición termine, en Spring WebFlux esto se cambia de modo que se trabaje de una forma más dinámica con hilos no bloqueantes.
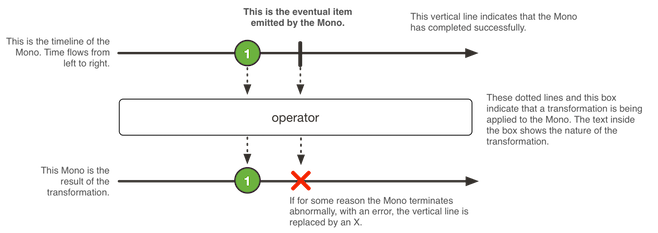
Flux y Mono
Spring WebFlux introduce dos nuevas implementaciones de Publisher: «Mono» y «Flux». Estas dos clases son las que serán utilizadas para trabajar con los elementos de nuestras aplicaciones al hacer llamadas entre ellas para obtener la información necesaria.
- Flux: genera series de 0 a N elementos.
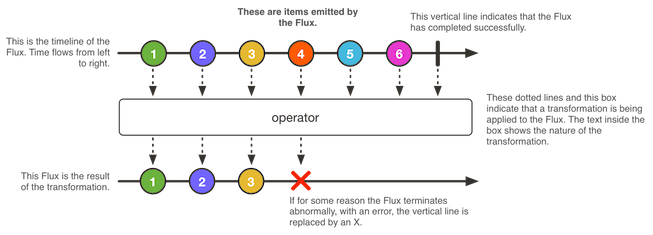
- Mono: Genera series de 0 a 1 elementos.
Construir una API Rest Reactiva
Supongamos que queremos desarrollar una API la cual haga peticiones a una dirección destino de la cual obtiene la información necesaria para devolver por los endpoints de su propia API. Para desarrollar esta aplicación habría que seguir los siguientes pasos:
Importar la dependencia
Primero de todo, deberemos agregar la dependencia correspondiente a nuestro proyecto.
Crear el servicio
Dentro del service de nuestra aplicación tendremos que crear los métodos con los cuales se realizarán las llamadas para obtener los datos de nuestra BB.DD., API externa, etc.
Para ello tendremos que hacer uso de las clases «Mono» y «Flux» explicadas anteriormente y de la clase «WebClient» que se encargará de realizar las llamadas, como en el siguiente ejemplo:
Service.java
@Override
public Flux<User> getAllUsers(String token) {
WebClient client = WebClient.create("http://localhost:8081/webfluxexample-server");
Flux<User> userFlux = client.get()
.uri("/")
.header("Authorization", token) //Opcional: Está añadida para mostrar como se podrían añadir cabeceras a las peticiones que lancemos con el WebClient
.retrieve()
.bodyToFlux(User.class);
userFlux.subscribe(System.out::println); //Opcional: Muestra por consola los cambios que recibe del WebClient
return userFlux;
}
@Override
public Mono<User> getUserById(String token, String id) {
WebClient client = WebClient.create("http://localhost:8081/webfluxexample-server");
Mono<User> userMono = client.get()
.uri("/{id}", id)
.header("Authorization", token) //Opcional: Está añadida para mostrar como se podrían añadir cabeceras a las peticiones que lancemos con el WebClient
.retrieve()
.onStatus(HttpStatus::isError, response -> { //Opcional: En caso de que no se encuentre el usuario especificado se puede indicar el flujo a seguir al recibir el status de error de la API invocada
if(response.statusCode() == HttpStatus.NOT_FOUND) {
throw new UserNotFoundException("User not found with that id");
}
throw new RuntimeException();
})
.bodyToMono(User.class);
userMono.subscribe(System.out::println); //Opcional: Muestra por consola los cambios que recibe del WebClient
return userMono;
}Con este ejemplo se está invocando a la API de otro microservicio el cual tiene dos endpoints, uno para devolver todos los usuarios y otro para devolver un usuario filtrando por su ID.
Como se puede ver, la principal diferencia entre un método y otro es el uso de las clases «Flux» y «Mono». En el caso del «getAllUsers» es necesario usar Flux ya que el resultado que vamos a obtener es una lista de User la cual podrá contener entre 0 y N elementos. En cambio, en el caso del «getUserById» utilizamos «Mono» ya que solo nos va a devolver un User (el cual hemos filtrado por su ID).
Este último caso nos puede devolver una respuesta de error con el código 404 al no existir el usuario que estemos buscando, por ello a la hora de realizar la petición se añade el método «.onStatus()» en el cual se le está indicando, en el ejemplo mostrado, que cuando reciba un 404 saque una excepción en la respuesta.
Mensaje de las excepciones
Se puede dar el caso de que al recibir la respuesta de una petición que ha dado una excepción no incluya el mensaje que se le ha especificado en el código. Para ello es necesario añadir la siguiente línea en el fichero application.yml de la aplicación que ha generado la excepción:
server.error.include-message: ALWAYS