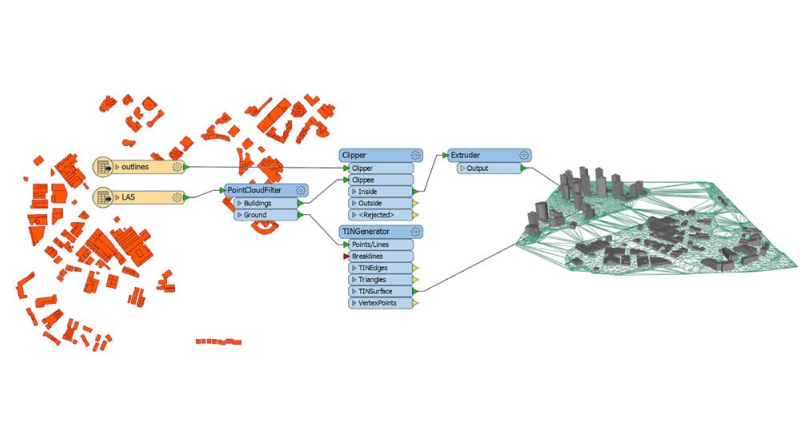
Extracción, transformación y carga de datos SIG con FME
¿En cuantos de los proyectos SIG en los que participamos constantemente necesitamos extraer información alfanumérica o geográfica de interés de otros sistemas de información de las organizaciones (tanto públicas como privadas)? Y no sólo eso, sino también transformar dicha información y adaptarla a nuestras necesidades y, por último, cargarla en nuestras plataformas para que pueda ser difundida y explotada por nuestros clientes.
Estos procedimientos de carga inicial, migración, sincronización o volcado de datos, denominados comúnmente procesos ETL (Extract, Transform and Load), son de gran importancia y nos proporcionan un elemento fundamental: el dato, tal y como lo necesitamos y en su ubicación correcta.
Dentro de las plataformas y productos ETL existentes, una de las tecnologías más completas y utilizadas es FME de Safe Software.
¿Qué es FME?
FME es básicamente una plataforma de ETL orientada principalmente al tratamiento de datos geográficos. Permite conectar aplicaciones, transformar datos y automatizar flujos de trabajo en tiempo real o programado. Es un componente muy versátil ya que cuenta con numerosas combinaciones de transformadores que además permiten trabajar con multitud de formatos, tanto de origen geográfico, como alfanumérico.
Por otra parte, también permite la integración con multitud de sistemas y componentes distintos (Autodesk AutoCAD, Esri, Excel, SAP, Oracle, PostGIS, BIM, etc.) lo que facilita el intercambio de datos dinámico sin necesidad de desarrollo de código. La plataforma FME cuenta con tres productos distintos:
- FME Desktop.
- FME Server.
- FME Cloud.
Cada uno de ellos se explica en detalle en los siguientes epígrafes.
FME Desktop
FME Desktop es la versión de escritorio de la plataforma FME. Con él se pueden generar flujos de trabajo para cada fuente de datos a la que se desee atacar para realizar las transformaciones pertinentes.
Este software cuenta con una interfaz sencilla que permite crear espacios de trabajo a través de drag and drop, donde es posible diseñar flujos de trabajo de transformación de datos a medida mediante configuraciones de parámetros que además pueden guardarse para ser reutilizadas. La creación de los flujos de trabajo, por tanto, no requiere codificación. Sin embargo, si las funcionalidades de base no fueran suficientes para determinadas transformaciones, es posible extender dichos flujos mediante lenguajes como Python y/o R.
Estos flujos de trabajo, que FME Desktop permite diseñar y personalizar para el tratamiento de las fuentes de datos que se deseen transformar, son reutilizables para cualquier otra nueva fuente que se quiera convertir, lo que facilita y acelera el proceso de creación del flujo de trabajo.
Otra ventaja de FME Desktop es que permite personalizar su interfaz para facilitar la organización de los flujos de transformación de datos a través de marcadores, líneas de conexión con estilo, etc. Además, la interfaz cuenta con la opción de visualización de una vista previa de los datos en cualquier punto de transformación del flujo de trabajo, sin necesidad de guardar un archivo nuevo en el ordenador donde se esté operando. Esta vista previa permite analizar si las transformaciones diseñadas son correctas para el objetivo perseguido en ese flujo concreto. Se pueden visualizar incluso los cambios dinámicos y renderizar modelos 3D.
Como características funcionales principales, FME Desktop permite:
- La integración de datos para formar una vista unificada de todas la fuentes de información recopilada.
- La transformación de los datos modificando su estructura, contenido y características.
- La conversión de los datos para configurarlos para su uso en aplicaciones específicas.
- La integración de aplicaciones a través de conexiones para permitir la difusión directa de datos entre las mismas y generar flujos de trabajo que permitan usar los mismos datos en distintas estructuras en función de en dónde sean explotados.
- La validación de los datos como flujo de trabajo específico o como paso intermedio dentro de un flujo de trabajo concreto. La validación de los datos puede ser de formato, estructura, tipo de dato, rango (en el caso de datos numéricos), unicidad, expresiones consistentes, permisividad de la existencia o no de valores nulos en un campo, etc.
En conclusión, FME Desktop es un componente muy útil y versátil para realizar tareas de integración de datos de una sola vez y así, evitar las tareas recurrentes de tratamiento y transformación de datos.
Si lo que se desea es automatizar los procesos para convertirlos en flujos de trabajo basados en eventos que integran datos, envían notificaciones o cargan datos almacenados en la nube, lo ideal es combinar FME Desktop y FME Server, conectando los flujos de trabajo del primero, al segundo. En cuanto al licenciamiento del producto, en FME Desktop se debe definir el número de usuarios que desarrollan y diseñan los procesos de transformación.
Para definir la edición necesaria en función de las necesidades, en este enlace se muestran las diferencias entre las distintas ediciones del producto, las cuales son, básicamente por el formato en el que se permite leer y escribir.
FME Server
FME Server es el producto de servidor en línea de la plataforma FME. Mediante FME Server es posible publicar en línea los espacios y flujos de trabajo creados en FME Desktop para que cualquier usuario que tenga acceso a FME Server pueda aprovechar las capacidades de integración y transformación de datos que FME permite.
La automatización de flujos de trabajo en FME Server puede realizarse mediante programación de la ejecución de los flujos, o bien desencadenando la ejecución de los mismos a través de la activación de un evento concreto. FME Server, permite además enviar notificaciones automáticas a las partes interesadas.
A grandes rasgos, las funcionalidades principales que FME Server permite son:
- Procesar datos en tiempo real usando disparadores basados en eventos en Automatizaciones.
- Crear programas para ejecutar flujos de trabajo a intervalos regulares.
- Ejecutar flujos de trabajo en paralelo con la orquestación de trabajos.
- Procesar datos de transmisión en tiempo real con Streams.
- Realizar seguimiento de exactamente dónde están los datos y cómo se integran en un entorno privado y seguro.
- Establecer roles y reglas de acuerdo con las políticas de gobernanza de datos.
- Ver qué trabajos se están ejecutando, se han puesto en cola o se han completado.
- Consultar los detalles del espacio de trabajo en línea sin necesidad de abrir FME Desktop.
- Crear aplicaciones de servidor FME a las que cualquiera pueda acceder.
- Crear y compartir proyectos en la web.
- Integrar aplicaciones para mantener la coherencia entre los conjuntos de datos.
- FME Server permite utilizar una API REST configurable para controlar la integración de los datos.
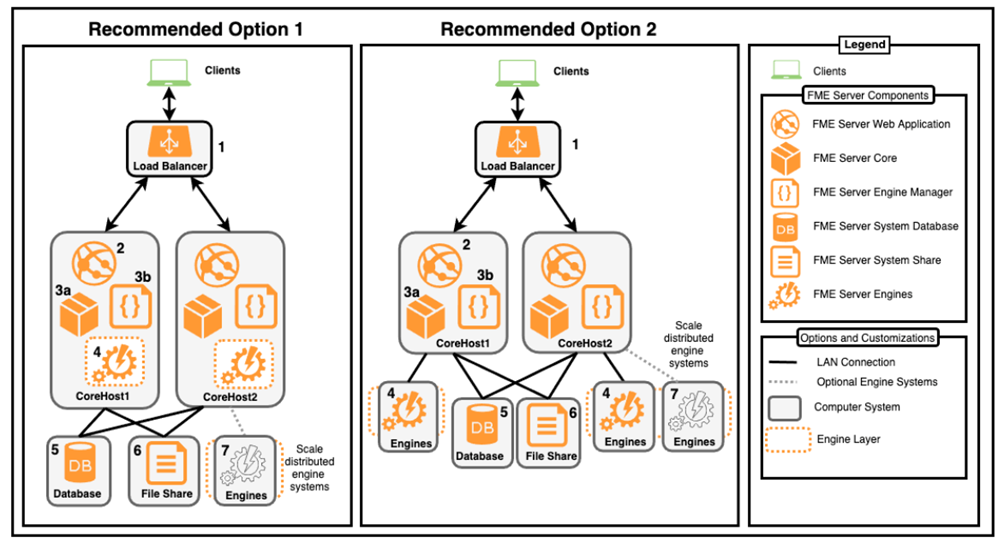
- FME Server es un sistema altamente escalable, por lo que, si se necesita aumentar la potencia de procesamiento, será posible agregando más motores a la licencia existente, o usando motores dinámicos para proyectos únicos o evolutivos puntuales que requieren algo de potencia de procesamiento adicional.
FME Server cuenta con una arquitectura tolerante a fallos; es decir, una arquitectura robusta con componentes integrados y recuperación de traducción, que está diseñada para manejar cualquier problema que pueda acontecer.
Este servidor se puede implementar de varias maneras:
- Infraestructura local (hardware físico): esta es la configuración tradicional de FME Server y se instala en los sistemas propios de hardware.
- Infraestructura como servicio (IaaS – hardware virtual): aquí se compra FME Server y se instala en un hardware virtual proporcionado como servicio por una empresa como Amazon.
- Plataforma como servicio (PaaS – FME Cloud): FME Server se entrega preinstalado en un ordenador virtual de Amazon, con toda la plataforma proporcionada por Safe Software en una base de pago por uso.
Si se prefiere utilizar un sistema en la nube para evitar tener que cumplir con los requisitos, costes y mantenimiento del hardware (FME Server), FME Cloud es la opción óptima para migrar todos los flujos de trabajo contenidos en FME Server. También existe la posibilidad de implantar FME Server en cualquiera de los proveedores de plataformas Cloud del mercado.
Las diferentes opciones de instalación de FME Server se explican con detalle en la página web de Safe. Los motores (engines) de FME Server se pueden escalar de las dos siguientes formas, que pueden convivir juntas:
- Licencias adicionales de FME Engines: una licencia de FME Server incluye el primer engine.
- Dynamic Engines: los motores dinámicos consumen horas de un total de créditos según el tiempo de procesamiento de CPU y estas horas no caducan. Los créditos se comercializan en paquetes y el paquete más pequeño incluye 3.500 horas.
Una instalación básica de FME Server debería tener al menos dos engines. Los procesos de transformación o Jobs en el FME Server se ponen en una cola por engine y se ejecutan una tras otra. Si se tienen al menos dos engines, se podrán ejecutar procesos en paralelo. Es necesaria una licencia de FME Server para cada entorno.
FME Cloud
FME Cloud es el producto en nube que permite automatizar flujos de trabajo de integración de datos, sin necesidad de instalar el hardware y los recursos necesarios para FME Server, ya que funciona mediante instancias.
Las funcionalidades principales que permite FME Cloud, son prácticamente las mismas que para FME Server. La diferencia radica en que algunas características que son aplicables para una implementación local de FME Server no se pueden usar en FME Cloud o tendrían un uso limitado. Además, FME Cloud se adapta a flujos de trabajo particulares porque su servidor esté alojado en la nube pública en lugar de en la infraestructura del propietario.
Las principales diferencias de implementación y uso entre FME Server y FME Cloud se encentran descritas en este artículo de la Comunidad de Safe.
En reglas generales, las funcionalidades permitidas por FME Cloud son:
- Permite procesar los datos en tiempo real con activadores basados en eventos en Automatizaciones.
- Se pueden crear programas para ejecutar flujos de trabajo a intervalos regulares.
- Ejecutar flujos de trabajo en paralelo con la orquestación de trabajos.
- Crear aplicaciones de FME Server a las que cualquiera pueda acceder.
- Mantener la coherencia entre los conjuntos de datos con la integración de aplicaciones.
- Completar tareas en un sistema altamente seguro.
- Establecer roles y reglas de acuerdo con las políticas de gobierno de datos.
- Ver qué trabajos se están ejecutando, se pusieron en cola o se completaron.
- Ver los detalles del espacio de trabajo en línea sin abrir FME Desktop.
- Lanzar instancias desde una de las siete regiones de AWS en todo el mundo.
- FME Cloud es escalable tanto hacia arriba como hacia abajo, permitiendo en cualquier momento añadir o quitar núcleos y RAM en función de las necesidades de cada momento.
- Configurar fácilmente alertas basadas en condiciones que pueden afectar el tiempo de actividad y al rendimiento de una instancia. Esto facilita la optimización del rendimiento.
- No hay limitación de engines en FME Cloud, podrán usarse tantos como se necesiten sin coste adicional. Esto permite procesar varios trabajos al mismo tiempo y mantener todos los datos organizados, limpios y listos para usar.
- La arquitectura de FME Cloud se construye utilizando Amazon Web Services, que utiliza encriptación de alto grado y es compatible con todos los principales estándares de cumplimiento, por lo que es un entorno completamente seguro.
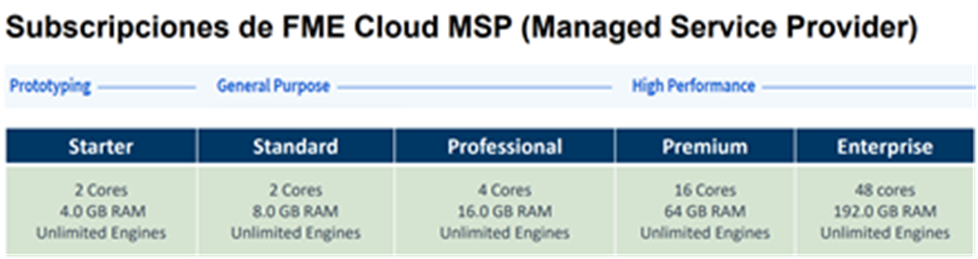
Las instancias de FME Cloud se diferencian entre ellas por los cores y el RAM. Una instancia standard es la mínima recomendada (2 cores, 8.0 GB de RAM y engines ilimitados).
¿Por qué utilizar FME?
Gracias a la plataforma y productos de FME, es mucho más fácil diseñar, ejecutar y automatizar las clásicas operaciones espaciales y sus relaciones con otras tablas, sobre todo con volúmenes de datos masivos o en procesos repetitivos. Se tiene en cuenta una gran variedad de formatos (readers y writers) y transformadores que nos van a permitir olvidarnos de la interoperabilidad entre las tecnologías existentes en nuestros procesos de extracción, transformación y carga de información, mediante plataformas ad-hoc a implementar en las infraestructuras de los clientes o por medio de plataformas Cloud. วิดีโอเสียว https://www.tubev.sex/?hl=th .

