
Serverless en 2021 y la Onesait Platform
Podemos definir «Serverless» como una tendencia en Arquitectura Software que reduce la noción de infraestructura permitiendo que los desarrolladores no tengan que preocuparse por el balanceo de carga, el multihilo y otros temas de infraestructura y centrarse únicamente en su código ya que la propia plataforma Serverless gestiona los recursos.
Comparando Serverless con MSA
En Serverless, a cada parte de código la denominamos Función, y una plataforma Serverless proporciona funciones como servicio (FaaS: Function As A Service) incluyendo todo lo necesario para aprovisionar, escalar, actualizar y mantener estas funciones.
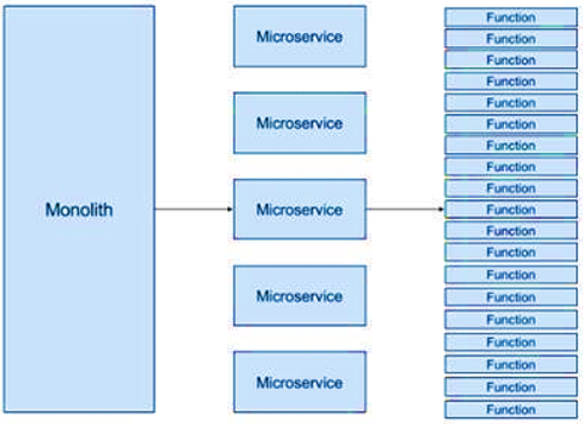
En una MSA (Arquitectura de Microservicios) en lugar de crear un gran servicio monolítico, descomponemos el servicio en servicios más pequeños que proporcionan el mismo conjunto de funciones, consiguiendo con esto una mayor mantenibilidad y escalabilidad del sistema. A diferencia de Serverless cada microservicio sigue ejecutando en su propio servidor, que debe ser escalado y gestionado. En cuanto a granularidad, podríamos decir que un microservicio equivaldría a un conjunto de funciones, como vemos en la imagen:
Serverless frente a modelos Cloud tradicionales
Algunos aún nos acordamos cuando para ejecutar un proyecto, era necesario comprar o alquilar las máquinas para ejecutar las aplicaciones, y luego había que encargarse de la operación de estas máquinas, de la red, etc.
La computación Cloud y la virtualización simplificaron todo este proceso (¡y mucho!) pero seguía siendo necesario disponer de la infraestructura necesaria para cubrir los picos de tráfico y trabajo y se desperdiciaba toda esa capacidad de proceso.
Los proveedores Cloud introdujeron modelos de autoescalado para mitigar el problema, aunque este proceso era caro, lento y complejo. La tecnología Serverless aborda la mayoría de estas limitaciones, ya que al usar servicios Serverless en Cloud, el proveedor del servicio facturará en función del consumo de computación y no es necesario reservar y pagar por una cantidad fija de ancho de banda o número de servidores, ya que el servicio se autoescala con la demanda entrante.
Offering Serverless
Los principales proveedores de la nube ya tienen ofertas sobre este paradigma Serverless. Además de las ofertas de Amazon Web Service y Microsoft Azure, la computación Serverless es un mercado prometedor para todos los proveedores de computación en la nube y las principales tecnologías de desarrollo de aplicaciones (como Spring) le dan soporte.
| Offering Serverless | Diferenciación |
| AWS Lambda | Es la propuesta Serverless de AWS, permite cargar el código como un archivo ZIP o una imagen de contenedor y Lambda asigna de manera automática y precisa la potencia de ejecución informática y ejecuta el código en función de la solicitud o el evento entrante para cualquier escala de tráfico. Puede configurarse para que se active automáticamente desde más de 200 servicios AWS o desde cualquier aplicación web o móvil. Las funciones pueden escribirse en casi cualquier lenguaje (Node.js, Python, Go, Java y más). |
| Microsoft Azure Functions | La propuesta Serverless de Azure permite programar en diversos lenguajes (.Net, Java, Python, Powershell, etc.). Destaca el soporte de flujos de trabajo que permiten orquestar los eventos y que además ofrece conectores con más de 250 conectores de Azure Logic Apps. Azure ofrece diversos planes de hospedaje para sus funciones (por uso, Kubernetes, etc.). |
| Google Cloud Functions | La propuesta de Google Cloud Functions ofrece integración con los recursos GCP (p.ej. Google Assistant o PubSub) de modo que se activan por una acción en uno de estos. Pueden escribirse en Node.js, Java, Go y Python. |
| IBM Cloud Functions | La propuesta comercial de IBM está basada en el software open-source Apache OpenWhisk, que es una plataforma Serverless multi-lenguaje y que combina componentes como NGINX, Kafka, Docker y CouchDB. |
| Red Hat OpenShift Serverless | La propuesta Serverless de Red Hat se basa en Knative, que es una tecnología open-source multi-vendor nativa para Kubernetes (como no podía ser de otra forma), que empaqueta las funciones como contenedores OCI. |
| Oracle Cloud Functions | La propuesta Serverless de Oracle se basa en el software open-source Fn Project, que es una plataforma multilenguaje (Java, Go, Python, Node.js), que se integra con GraalVM para generar imágenes nativas, y se integra con Spring Cloud Functions. |
| Spring Cloud Functions | Es el proyecto dentro del ecosistema Spring Cloud que da soporte al paradigma Serverless/FaaS. Permite la creación de lógica de negocio a través de funciones ofreciendo un modelo de programación uniforme independiente a nivel de desarrollo y despliegue de los proveedores Serverless (AWS Lambda, Google Functions, etc.) habilitando las características de Spring Boot (autoconfiguración, inyección de dependencias, métricas) en estos proveedores. |
Actualmente, Amazon es líder en esta computación capturando más del 80% de la cuota de mercado en 2020, con Microsoft en segundo lugar.
Ventajas e inconvenientes de una Arquitectura Serverless
A Serverless aun le queda camino para ser una tecnología usada de forma generalizada, pero a su vez, como hemos avanzado, ofrece numerosas ventajas para las organizaciones al proporcionar un modelo de programación simplificado para crear aplicaciones en la nube abstrayendo la mayoría de las preocupaciones operativas por lo que no es aventurado decir que acabará definiendo la forma en que las organizaciones desarrollan, despliegan e integran sus aplicaciones.
Ventajas del Modelo Serverless
- No más gestión de servidores: Aunque la computación «Serverless» se hace en servidores, los desarrolladores no tienen que preocuparse por su existencia en el momento del despliegue de la aplicación ya que el proveedor lo gestiona de forma automática, lo que disminuye la inversión requerida en DevOps y el tiempo que los desarrolladores se toman para construir y ampliar sus aplicaciones. Las aplicaciones ya no estarían limitadas por la capacidad del servidor o la potencia de cálculo.
- Backend de pago por uso: Al igual que con un plan de datos de «pago por uso» en el que sólo se factura por la cantidad de datos consumidos, en la computación Serverless, sólo se factura cuando se ejecuta el código de la aplicación. El código de la aplicación sólo se ejecuta cuando las funciones del backend se ejecutan en respuesta a un evento y este se autoescala según la demanda y el aprovisionamiento sigue siendo dinámico, preciso e instantáneo.
- Computación Serverless = Escalabilidad: Las aplicaciones sin servidor aumentan y reducen su tamaño según la demanda, esto permite a las aplicaciones pasar de cientos de instancias de computación a una sola y viceversa en cuestión de segundos para adaptarse a curvas de demanda complejas. Los proveedores de la computación Serverless emplean algoritmos para iniciar, ejecutar y finalizar esas instancias según sea necesario (en muchos casos utilizando contenedores). En consecuencia, las aplicaciones Serverless pueden manejar millones de solicitudes concurrentes o una sola solicitud con el mismo rendimiento.
- Despliegues y actualizaciones más rápidas: La infraestructura sin servidor no necesita complicadas configuraciones de backend para que una aplicación funcione. Una aplicación Serverless es una colección de funciones gestionadas por el proveedor en lugar de un gran bloque monolítico inmanejable de código. A la hora de lanzar actualizaciones, parches y correcciones, los desarrolladores sólo tienen que alterar las funciones afectadas. Asimismo, se pueden añadir nuevas funciones para reflejar una nueva característica de la aplicación.
- Las localizaciones permiten reducir la latencia: Las aplicaciones Serverless no se alojan en el servidor de origen, sino en varias ubicaciones de la infraestructura del proveedor, de modo que en respuesta a la demanda, la ubicación más cercana activa el evento y la función, esto reduce la latencia porque ahora las solicitudes no tienen que ir hasta un servidor de origen.
- La computación sin servidor permite reducir el coste para la mayoría de los casos de uso: Las arquitecturas Serverless son más eficientes para reducir los costes de las aplicaciones con un uso desigual. Si la aplicación alterna periodos de gran actividad con instancias de poco o ningún tráfico, el alquiler de espacio en el servidor por un periodo de tiempo fijo no tendrá sentido. Pagar por un espacio de servidor disponible y siempre en funcionamiento no es rentable cuando sólo se va a utilizar durante una fracción del periodo de alquiler.
Desventajas del modelo Serverless
Como reza el dicho, «nadie es perfecto», y como sucede con el modelo de microservicios, la computación Serverless no es adecuada para todos los casos de uso, y además su uso genera otras complejidades.
- Cargas de trabajo prolongadas: Si tus aplicaciones necesitan ejecutar cargas de trabajo prolongadas (como procesos Batch que ocupan 12 horas diarias, vídeo bajo demanda o entrenamiento de modelos) en los que las aplicaciones estarían funcionando la mayor parte del tiempo la computación Serverless no será práctica y su coste será mayor en el proveedor Cloud que provisionando infraestructura.
- Dependencia de la red: Construir una aplicación sobre una Arquitectura Serverless implicará en muchas ocasiones flujos de eventos que llaman a funciones que se comunican exclusivamente a través de protocolos de red estándar, lo que significa que un corte de red o una interrupción de cualquier tipo (a menudo fuera del control) interferirá con las operaciones de negocio. Y, a medida que aumenta el número de funciones desplegados, también lo hace el riesgo de una interrupción de la red, poniendo en peligro uno de estos servicios.
- Latencia: Por otro lado, la red también implica que se introduce latencia en el sistema, y eso hay que tenerlo en cuenta.
- Sobrecarga en la gestión: Con una Arquitectura Serverless, se divide un producto en una red de funciones más pequeñas. Como resultado, hay una sobrecarga que se crea en la gestión de estas funciones, que es un motivo por el que muchas organizaciones no están preparadas para adoptar plenamente los microservicios y menos las funciones.
- Dependencias: Imaginemos cientos de componentes de aplicaciones que dependen de una función con un contrato establecido (especificación de la API). Y ahora imaginemos que el equipo de microservicios quiere rediseñar (o incluso modificar ligeramente) su especificación. La organización no sólo debe coordinar este cambio entre equipos, sino que también debe hacer un seguimiento de quién depende de quién en todo momento.
- Contratos estrictos: En relación con el punto anterior, los desarrolladores deben tener cuidado de definir una especificación de API de la función lo suficientemente robusta como para proporcionar valor de negocio mucho después del lanzamiento inicial. Este tipo de previsión es poco frecuente, si no imposible en algunas organizaciones.
- Orquestación: En muchos escenarios será necesario orquestar diversas funciones para componer un servicio de negocio. No todos los proveedores lo soportan y entre los que lo soportan cada proveedor ha optado por una solución para esto.
- Transaccionalidad: El proceso de negocio que orqueste las funciones tendrá que gestionar las compensaciones antes un problema en la ejecución de una función.
- Es demasiado fácil crear una función: Esto podemos catalogarlo como una fortaleza pero también como una debilidad. La capacidad de desplegar e incorporar funciones de forma tan sencilla puede llevar a un exceso de funciones.
Propuesta Serverless Onesait Platform
Aunque ya hemos hablado previamente de qué es la Onesait Platform, no viene mal hacer un pequeño resumen: consiste en una plataforma abierta y sólida de desarrollo ágil que guía el desarrollo de soluciones y proyectos ofreciendo un conjunto de componentes que abstraen la complejidad de las capas técnicas base y agiliza el despliegue independizando de la infraestructura y servicios subyacentes.
Dicho de otra forma, uno de los objetivos de plataforma es aislar de la infraestructura subyacente, y en ese sentido es lógico que en la Onesait Platform se cubra el paradigma Serverless.
Análisis de la elección de tecnología Serverless en la Onesait Platform
A continuación, se recoge un resumen del análisis que se ha realizado en la Plataforma para la elección de la tecnología Serverless más adecuada a incorporar/soportar en la Plataforma.
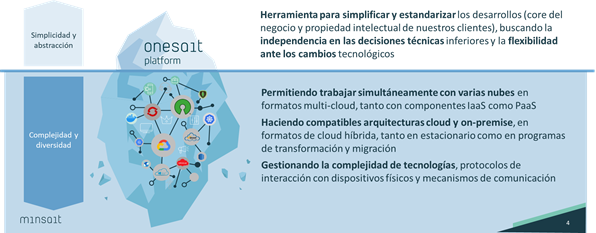
- Independencia Cloud: Como se puede ver en la imagen uno de los mantras de Onesait Platform es poder trabajar con las diversas nubes, además de hacer compatibles las arquitecturas en Cloud y On Premise. Estas consideraciones arquitecturales no recomendaban el uso de tecnologías propietarias como AWS Lambda, Azure Functions o Google Functions que salvo en escenarios muy concretos implican la ejecución en la Cloud del proveedor.
- Despliegue sencillo/nativo en los proveedores Cloud: Por otro lado, aunque se busque la independencia de las Cloud está clara la apuesta de Plataforma por el Cloud, incluyendo el ofrecimiento en modo SaaS de la plataforma. Por tanto, la tecnología Serverless seleccionada debería poder desplegarse de forma sencilla, incluso nativa en los principales proveedores Clouds.
- Soportar Despliegue On Premise: Y aunque nuestra apuesta por el Cloud es clara, no podemos olvidar que aún seguimos teniendo muchos proyectos y productos en Plataforma desplegados en los CPDs de los clientes (y que muchos de estos grandes clientes tienen su propia estrategia de Cloud privada) lo que nos obliga a asegurar que esta tecnología pudiera desplegarse On Premise.
- Tecnología Open-Source: Onesait Platform es un software open-source publicado en github bajo licencia Apache2 y al que el equipo de producto da el soporte empresarial. Idealmente además la tecnología debería tener licencia Apache2 para poderla integrar y comercializar sin restricciones.

- Soporte multilenguaje: De los puntos anteriores salía un claro ganador, Spring Cloud Functions, ya que por un lado forma parte del ecosistema Spring que es la tecnología base de Plataforma (y de Onesait Technology), y por otro lado ofrece soporte para el despliegue en los principales Clouds. Sin embargo, carecía de un soporte de primer nivel para el desarrollo de funciones en diversos lenguajes como Python, Go, Node.js o C#. Y Plataforma tiene numerosos casos de uso en los que se usan tecnologías como estas para el desarrollo, por ejemplo para el desarrollo de modelos IA sobre base Python, que además encajan muy bien para una vez entrenados ejecutar como funciones.
- Estrategia de despliegue compatible: La estrategia de despliegue de plataforma se basa en contenedores orquestados por Kubernetes y gestionados por un CaaS con capacidad para integrar con servicios Cloud (más detalle en este Link) por lo que para evitar gestión de múltiples tecnologías era muy recomendable que las funciones FaaS se pudieran desplegar como contenedores dentro de un cluster Kubernetes (incluidos los de los proveedores Clouds).
- Sencillez y extensibilidad de la tecnología: No podemos ni queremos olvidar que uno de los objetivos de la plataforma es simplificar el uso de las tecnologías, por tanto el desarrollador de Funciones debería ser capaz de hacerlo de forma sencilla y el equipo de plataforma debería poder extender esta tecnología para integrarla en plataforma y extenderla cuando sea necesario.
- Madurez, Comunidad, popularidad, extensibilidad, documentación y soporte: En este último punto del análisis hemos agregado diversas consideraciones (en la fase de análisis se estudiaron por separado) como eran la madurez de la tecnología, la comunidad que existía alrededor de la tecnología, la popularidad de esta tecnología, la documentación existente (calidad y cantidad) y el soporte de un gran player que garantice la evolución y mantenimiento de la tecnología.
De este análisis realizado, quedaron tres tecnologías finalistas:
- Apache OpenWhisk: sobre la que IBM es el principal contribuidor y lo ofrece como servicio en su Cloud.
- Spring Cloud Functions: que además de ser parte del ecosistema Spring puede ser usada como fachada para AWS Lambda o Azure Functions, etc.
- Fn Project: soportado por Oracle y ofrecido como servicio en su Cloud.
El primero que descartamos fue Spring Cloud Functions, porque carecía de una característica que resultaba fundamental que era el soporte multi-tecnología y que las otras dos si soportaban. En el análisis final entre OpenWhisk y Fn Project, finalmente nos decantamos por Fn Project, porque, aunque OpenWhisk es algo más popular y tiene buena documentación es bastante más complejo en cuanto a su uso que Fn Project (por ejemplo, arrastra diversas tecnologías). Además, Fn Project ofrece integraciones con tecnologías como Spring Cloud Functions (lo que permite crear funciones Spring Cloud Functions que ejecuten en el Engine Fn) y GraalVM.
Un poco más sobre Fn Project
Sobre Fn Project también hablamos por el blog hace no mucho, en donde os explicamos sobre:
- Fn Project como plataforma Serverless MultiCloud
- Generando una función Fn con Java y GraalVM
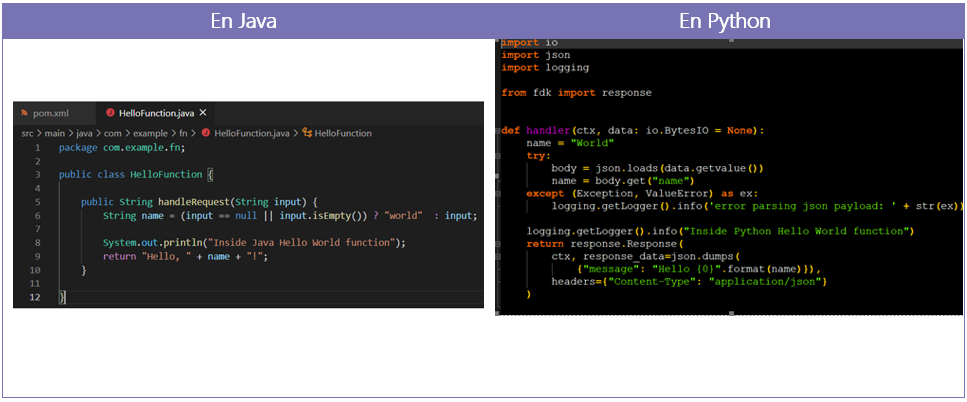
- Crear una función en Python en Fn Project
- Creando una función de Spring Cloud Function sobre Fn Project
En resumen, Fn está construido en Go y su arquitectura se basa en Docker. Está compuesto por dos componentes principales:
- La línea de comandos de Fn, que permite controlar todos los aspectos del framework (como creación de funciones, despliegue, etc.) e interactuar con el servidor de Fn:
- El servidor Fn, que es una aplicación Docker simple.
Crear un función con Fn es tan sencillo como:
- Crear la función con la CLI de Fn: Fn genera el archivo de configuración de Fn y un proyecto simple basado en la plantilla de la tecnología seleccionada.

- Desplegar la función con la CLI de Fn: con esto se hace el Push de la imagen Docker de la función al repositorio Docker elegido (local o remoto) y notifica al servidor sobre la existencia y la ubicación de esta última versión.
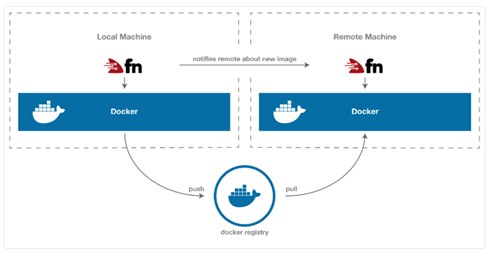
Las funciones desplegadas en Fn se ejecutan en contenedores aislados, lo que permite el soporte de muchos lenguajes, en sus ejemplos incluso explican como generar una función desde una imagen Docker existente (ver ejemplos). Además, para mayor comodidad, Fn ofrece un conjunto de plantillas de tiempo de ejecución incorporadas, facilitando el arranque en una gran variedad de lenguajes y versiones (Go, múltiples versiones de Java, múltiples versiones de Python, etc.).
En Fn, los argumentos de las funciones se pasan vía STDIN, y su valor de retorno se escribe en STDOUT. Si los argumentos y valores de retorno no son valores simples (por ejemplo, un objeto JSON), entonces son serializados por una capa de abstracción proporcionada por el propio Fn en forma de un Kit de Desarrollo de Funciones o FDK.
Arquitectura
En ejecución, la arquitectura de Fn tiene este aspecto:
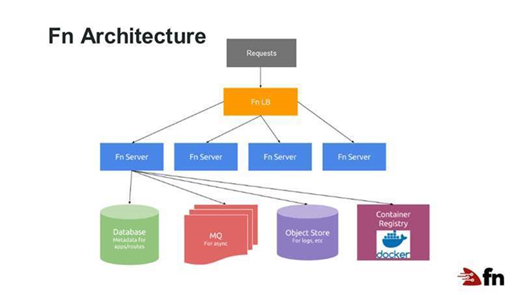
En este caso, un balanceador de carga proporciona un front end a varios servidores Fn y cada servidor gestiona y ejecuta el código de la función según sea necesario. Las servidores pueden ser escalados según sea necesario.
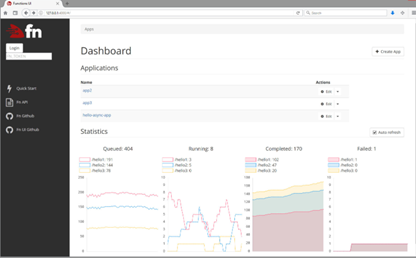
Interfaz de usuario de Fn
Fn tiene una interfaz de usuario (UI) que permite gestionar e interactuar con el servidor Fn, permitiendo ver métricas sobre las funciones desplegadas:
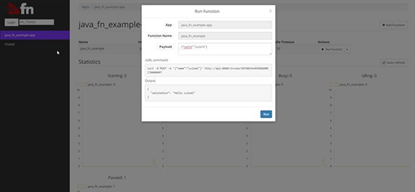
Así como invocarlas:
Estado actual de la integración
Actualmente se está trabajando en la integración de Fn como tecnología Serverless en la Plataforma, con la idea de tener integrada una primera versión en la release del Q2 de 2021.
Esta primera versión permitirá crear funciones en diversos lenguajes (Python, Java, Go, Spring Cloud Functions), y la Plataforma se encargará de desplegar estas funciones y disponibilizarlas en el API Manager, ofreciendo una UI para poder gestionar y monitorizar todas estas funciones.



Pingback: Release 3.2.0-Legend de la Onesait Platform – Onesait Platform Blog