
Serverless in 2021 and Onesait Platform
We can define «Serverless» as a trend in Software Architecture that reduces the notion of infrastructure, allowing developers to not have to worry about load balancing, multithreading and other infrastructure issues so they can focus solely on their code while the Serverless platform itself manages the resources.
Comparing Serverless with MSA
In Serverless, each piece of code is called a Function, and a Serverless platform provides Functions as a Service (FaaS) including everything needed to provision, scale, update and maintain these functions.
In an MSA (Microservices Architecture), instead of creating a large monolithic service, we decompose the service into smaller services that provide the same set of functions, thus achieving greater maintainability and scalability of the system. Unlike Serverless, each microservice still runs on its own server, which must be scaled and managed. In terms of granularity, we could say that a microservice is equivalent to a set of functions, as shown in the image:
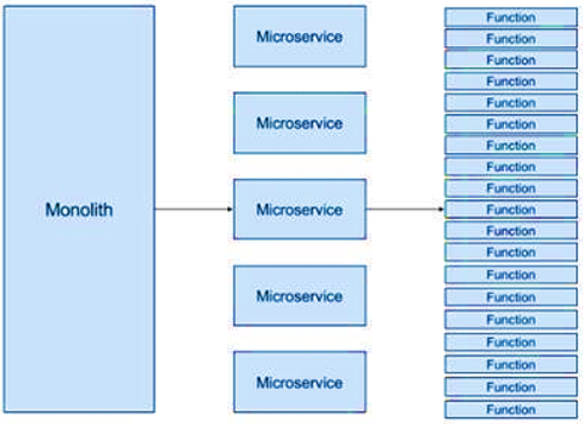
Serverless vs. traditional Cloud models
Some of us still remember when, to run a project, it was necessary for you to buy or rent the machines to run the applications, and then you had to take care of the operation of these machines, of the network, etc.
Cloud computing and virtualization simplified this whole process (and how!), but it was still necessary to have the necessary infrastructure to cover the traffic and work peaks, and all that processing capacity was wasted.
Cloud providers introduced auto-scaling models to mitigate the problem, although this process was still expensive, time-consuming and complex. Serverless technology addresses most of these limitations, because, when using serverless services in the Cloud, the service provider will bill you based on compute consumption, so there is no need to reserve and pay for a fixed amount of bandwidth or a number of servers, because the service auto-scales with incoming demand.
Serverless Offering
The major cloud providers already have offerings on this Serverless paradigm. In addition to offerings from Amazon Web Service and Microsoft Azure, serverless computing is a promising market for all cloud computing providers and is supported by major application development technologies (such as Spring).
| Serverless Offering | Diferentiation |
| AWS Lambda | This is AWS’ Serverless proposition. It allows code to be uploaded as a ZIP file or container image, and then AWS Lambda automatically and accurately allocates compute execution power and executes the code based on the incoming request or event for any scale of traffic. It can be configured to automatically trigger from over 200 AWS services or from any web or mobile application. Functions can be written in almost any language (Node.js, Python, Go, Java, etcetera). |
| Microsoft Azure Functions | Azure’s Serverless approach allows programming in a variety of languages (.Net, Java, Python, Powershell, etc.). It highlights the support of workflows that allow orchestrating events and it also offers connectors with more than 250 Azure Logic Apps connectors. Azure offers different hosting plans for its functions (per-use, Kubernetes, etc.). |
| Google Cloud Functions | The Google Cloud Functions approach offers integration with GCP resources (such as Google Assistant or PubSub), so that they are triggered by an action on one of these. They can be written in Node.js, Java, Go and Python. |
| IBM Cloud Functions | IBM’s commercial proposition is based on the open-source Apache OpenWhisk software, which is a multi-language serverless platform and combines components such as NGINX, Kafka, Docker and CouchDB. |
| Red Hat OpenShift Serverless | Red Hat’s serverless approach is based on Knative, which is a multi-vendor open-source technology native to Kubernetes (unsurprisingly), which packages functions as OCI containers. |
| Oracle Cloud Functions | Oracle’s serverless proposal is based on the open-source software Fn Project, which is a multi-language platform (Java, Go, Python, Node.js), integrates with GraalVM to generate native images, and is integrated with Spring Cloud Functions. |
| Spring Cloud Functions | It is the project within the Spring Cloud ecosystem that supports the Serverless/FaaS paradigm. It allows the creation of business logic through functions, offering a uniform programming model that is independent at the level of development and deployment of serverless providers (AWS Lambda, Google Functions, etc.), enabling Spring Boot features (autoconfiguration, dependency injection, metrics) in these providers. |
Currently, Amazon is the leader in this computing, capturing more than 80% of the market share by 2020, with Microsoft in second place.
Advantages and Disadvantages of a Serverless Architecture
Serverless still has some way to go to become a widely used technology, but, as we have already mentioned, it offers many advantages to organizations by providing a simplified programming model for creating applications in the cloud, abstracting most of the operational concerns, so that it is safe to say that it will end up defining the way organizations develop, deploy and integrate their applications.
Advantages of the Serverless Model
- No more server management: Although serverless computing is done on servers, developers do not have to worry any more about their existence at the time of application deployment, since the vendor automatically manages that. This decreases the investment required in DevOps and the time developers take to build and extend their applications. Applications would no longer be limited by server capacity or computing power.
- Pay-as-you-go backend: As with a «pay-as-you-go» data plan where you are only billed for the amount of data consumed, in serverless computing, you are only billed when the application code is executed. Application code is only executed when back-end functions are executed in response to an event, and it auto-scales on demand. Provisioning remains dynamic, accurate and instantaneous.
- Serverless computing = Scalability: Serverless applications scale up and down on demand, allowing applications to go from hundreds of compute instances to one single instance and back in a matter of seconds to accommodate complex demand curves. Serverless computing providers employ algorithms to start, run and terminate these instances as needed (in many cases using containers). As a result, serverless applications can handle millions of concurrent requests or one single request with the same performance.
- Faster deployments and upgrades: Serverless infrastructure does not require complicated backend configurations to get an application up and running. A serverless application is a collection of functions managed by the vendor, rather than a large, unwieldy monolithic block of code. When it’s time to release updates, patches and fixes, developers need only alter the affected functions. Likewise, new functions can be added to reflect a new application feature.
- Localizations allow reducing latency: Serverless applications are not hosted on the origin server, but at multiple locations in the provider’s infrastructure, so that, in response to demand, the closest location triggers the event and feature. This reduces latency because requests do not have to go to an origin server.
- Serverless computing allows cost reduction for most use cases: Serverless architectures are more efficient at reducing costs for applications with uneven usage. If the application alternates periods of high activity with instances of little or no traffic, renting server space for a fixed period of time will make little sense. Paying for available, always-on server space is not cost-effective when it will only be used for a fraction of the rental period.
Disadvantages of the Serverless model
As the saying goes, «nobody’s perfect», and as with the microservices model, serverless computing is not suitable for all use cases. Its use also generates other complexities.
- Extended workloads: if your applications need to run long workloads (such as batch processes that take up 12 hours a day, video on demand or model training), in which the applications will be running most of the time, serverless computing will not be practical and its Cloud provider cost will be higher than provisioning infrastructure.
- Network dependency: building an application on a Serverless Architecture will often involve event streams that call functions that communicate exclusively through standard network protocols, which means that a network outage or interruption of any kind (often out of our control) will interfere with business operations. Besides, as the number of functions deployed increases, so does the risk of a network outage, putting one of these services at risk.
- Latency: On the other hand, the network also means that latency is introduced into the system, and this must also be considered.
- Management overload: With a Serverless Architecture, a product is divided into a network of smaller functions. As a result, there is an overload that is created in managing these functions, which is one reason why many organizations are not ready to fully adopt microservices, let alone functions.
- Dependencies: Imagine hundreds of application components that depend on a function with an established contract (API specification). And now, imagine that the microservice team wants to redesign (or even slightly modify) their specification. The organization must not only coordinate this change between teams, but also keep track of who depends on whom at all times.
- Strict contracts: related to the previous point, developers must be careful to define a feature API specification robust enough to provide business value long after the initial release. This type of foresight is rare, if not impossible in some organizations.
- Orchestration: In many scenarios it will be necessary to orchestrate several functions to compose a business service. Not all vendors support this and, among those that do, each vendor has chosen a different solution for this.
- Transactionality: the business process that orchestrates the functions will have to manage trade-offs before a problem in the execution of a function.
- Creating a function is too easy: We can categorize this as a strength but also as a weakness: The ability to deploy and incorporate functions so easily can lead to an excess of functions.
Onesait Platform’s Serverless Proposal
Although we have already talked previously about what the Onesait Platform is, it’s never useless to make a brief summary: it is an open and solid platform for agile development that guides the development of solutions and projects, by offering a set of components that abstract the complexity of the base technical layers and speeds up deployment, making it independent of the underlying infrastructure and services.
In other words, one of the platform’s objectives is to isolate from the underlying infrastructure, and in this sense, logically the Onesait Platform covers the Serverless paradigm.
Analysis of the choice of serverless technology in the Onesait Platform
The following is a summary of the analysis carried out on the Platform to choose the most appropriate Serverless technology to incorporate and support in the Platform.

- Cloud Independence: As you can see in the image, one of Onesait Platform’s mantras is to be able to work with different clouds, in addition to making Cloud and On-Premise architectures compatible. These architectural considerations did not recommend the use of proprietary technologies such as AWS Lambda, Azure Functions or Google Functions which, except in very specific scenarios, involve execution in the provider’s Cloud.
- Simple/native deployment in the Cloud providers: On the other hand, even if independence from the Cloud is sought, the Platform’s commitment to the Cloud is clear, including offering the platform in SaaS mode. Thus, the selected serverless technology should be easily deployed, even natively for the main Cloud providers.
- Support On Premise Deployment: Although our commitment to the Cloud is clear, we cannot forget that we still have many Platform projects and products deployed in the customers’ data centers (and that many of these large customers have their own, private Cloud strategy), which makes us ensure that this technology can be deployed On Premise.
- Open-Source Technology: Onesait Platform is an open-source software published in github under Apache2 license and it is supported by the product team. Ideally, the technology should also have an Apache2 license so that it can be integrated and marketed without restrictions.

- Multilanguage support: from the previous points, a clear winner emerged: Spring Cloud Functions, since it is, on the one hand, part of the Spring ecosystem, which is the base technology of the Plataform (and of the Onesait Technology), and on the other hand, it offers support for deployment in the main Clouds. However, it lacked top-level support for function development in several languages such as Python, Go, Node.js or C#. Besides, Platform has numerous use cases where technologies like these are used for development – for example, for the development of AI models on a Python basis, which also fit very well, once trained, to run as functions.
- Compatible deployment strategy: The Platform’s deployment strategy is based on containers orchestrated by Kubernetes and managed by a CaaS with the capacity to integrate with Cloud services (more details in this link), meaning that, to avoid managing multiple technologies, it was highly recommended that FaaS functions could be deployed as containers within a Kubernetes cluster (including those of Clouds providers).
- Simplicity and extensibility of the technology: We cannot, nor do we not want to forget, that one of the objectives of the Platform is to simplify the use of the technologies. Therefore, the Functions’ developer should be able to work in a simple way, and the Platform team should be able to extend this technology to integrate it in the platform and extend it whenever needed.
- Maturity, Community, popularity, extensibility, documentation and support: in this last point of the analysis, we have added several considerations (in the analysis phase, those had been studied separately) such as the maturity of the technology, the community that existed around the technology, the popularity of this technology, the existing documentation (both quality and quantity) and the support of a large player that guarantees the evolution and maintenance of the technology.
From this analysis, there were three finalist technologies:
- Apache OpenWhisk: on which IBM is the main contributor and offers it as a service in its Cloud.
- Spring Cloud Functions: which, in addition to being part of the Spring ecosystem, can be used as a front end for AWS Lambda or Azure Functions, etc.
- Fn Project: supported by Oracle and offered as a service in its Cloud.
The first one we discarded was Spring Cloud Functions, because it lacked a feature that was fundamental: the multi-technology support supported by the other two. In the final analysis between OpenWhisk and Fn Project, we finally chose Fn Project, because, although OpenWhisk is somewhat more popular and has a good documentation, it is far more complex to use than Fn Project (for example, it drags several technologies). Besides, Fn Project offers integrations with technologies such as Spring Cloud Functions (which allows you to create Spring Cloud Functions that run on the Fn Engine) and GraalVM.
A bit more on Fn Project
We also talked about Fn Project on this same blog not long ago, where we explained about:
- Fn Project as a Serverless MultiCloud Platform
- Generating an Fn function with Java and GraalVM
- Creating a Python function in Fn Project
- Creando una función de Spring Cloud Function sobre Fn Project
In a nutshell, Fn is built in Go and its architecture is based on Docker. It is composed of two main components:
- The Fn command line, which allows you to control all aspects of the framework (such as function creation, deployment, etc.) and to interact with the Fn server:
- The Fn server, which is a simple Docker application.
- El servidor Fn, que es una aplicación Docker simple
Creating a function with Fn is as simple as:
- Create the role with Fn’s CLI: Fn generates the Fn configuration file and a simple project based on the selected technology template.

- Deploy the function with Fn’s CLI: with this, you perform the push of the Docker image of the function to the chosen (either local or remote) Docker repository, while also notifying the server about the existence and location of this latest version.
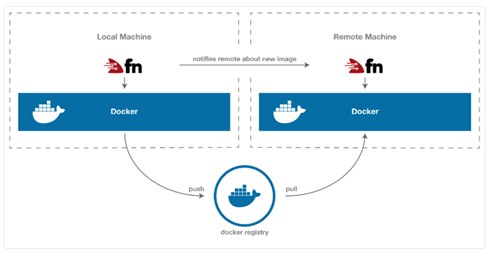
The functions deployed in Fn run in isolated containers, which allows the support of many languages. In their examples, they even explain how to generate a function from an existing Docker image (see examples). Besides, for the sake of greater convenience, Fn offers a set of built-in runtime templates, making it easy to start in a wide variety of languages and versions (Go, multiple versions of Java, multiple versions of Python, etcetera).
In Fn, function arguments are passed via STDIN, and their return value is written to STDOUT. If the arguments and return values are not simple values (e.g., a JSON object), then they are serialized by an abstraction layer provided by Fn itself in the form of a Function Development Kit or FDK.
Architecture
In runtime, Fn’s architecture looks like this:
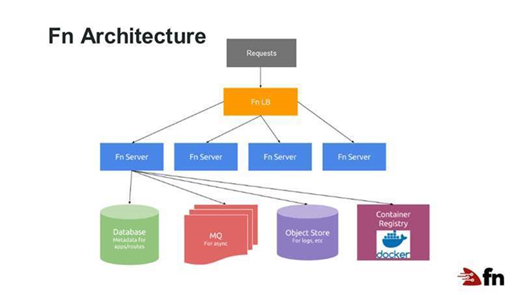
In this case, a load balancer provides a front end to multiple Fn servers, and each server manages and executes the function code as needed. Servers can be scaled, also as needed.
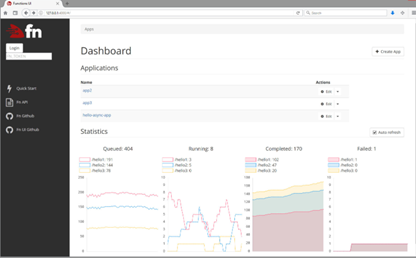
Fn user interface
Fn has a user interface (UI) that allows you to manage and interact with the Fn server, allowing you to view metrics about deployed functions:
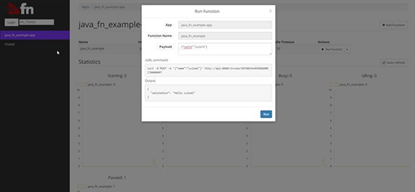
And invoking them:
Current status of the integration
We are currently working on the integration of Fn as a Serverless technology in the Platform, aiming to have a first version integrated in the Q2 release, 2021.
This first version will allow the creation of functions in different languages (Python, Java, Go, Spring Cloud Functions), and the Platform will take care of deploying these functions and making them available in the API Manager, offering a UI to manage and monitor all these functions.



Pingback: Release 3.2.0-Legend of the Onesait Platform – Onesait Platform Blog