
Onesait Platform as a Low Code Platform
One of the challenges in organisations of any size has always been to be able to adapt to business needs quickly, something that is becoming increasingly important due to digital transformation.
From Gartner, we know that organisations spend the majority of their IT budget on application development, so it is increasingly important to find solutions to simplify and streamline the solutions development and deployment, focusing on the business value delivered to the customer.
These solutions must meet the needs of different profiles, as they are:

And this is where the so-called Low Code Platforms come into play.
What is a Low Code Platform?
An LCAP (Low Code Application Platform) is a platform that supports quick development, automated deployment, and execution and management of applications using high-level programming abstractions (either visual or declarative).
These platforms support the development of user interfaces, business logic and data services, and they improve productivity when compared to conventional application platforms. An enterprise LCAP must support the development of enterprise applications, which require high performance, scalability, high availability, disaster recovery, security, SLAs, resource usage tracking and vendor support, and access to local and cloud services.
A very clear example of this type of platform is our Onesait Platform.
Onesait Platform
There are many ways of defining what the Onesait Platform is, depending on the scenario to which it applies. In this scenario in particular, we can define it as «an open, robust, agile-development platform that guides the development of solutions and projects by offering a set of components that abstracts the complexity of the base technical layers and speeds up the deployment, making the user independent of the underlying infrastructure and services.»
Perhaps what we mean can be better understood with the following graphic:
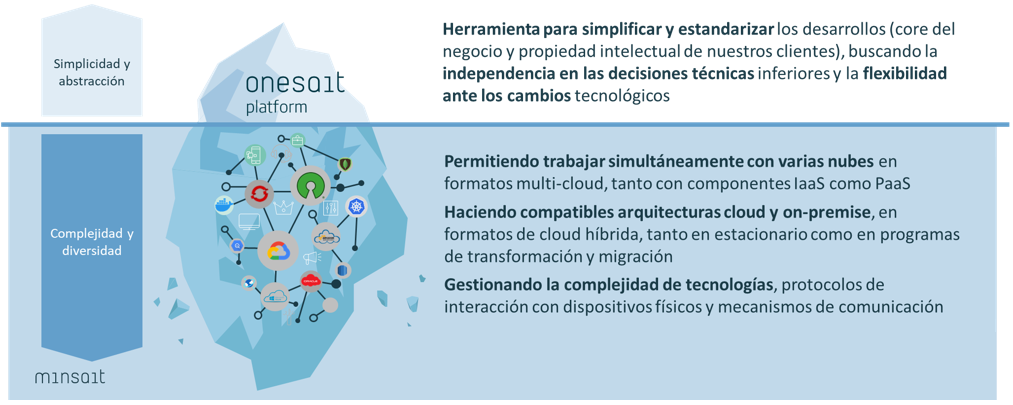
Value proposition of the Onesait Platform as a Low Code platform
Onesait Platform stands on top of four pillars, one of which specifically refers to the agile development of solutions:
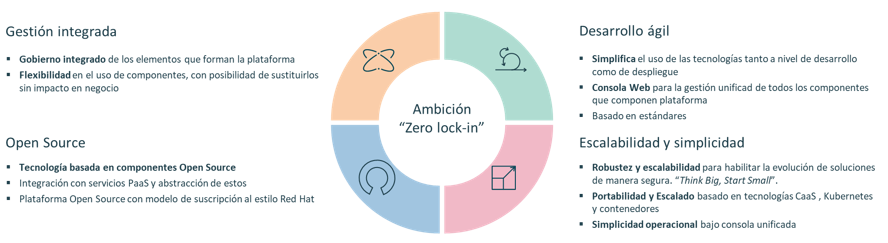
Thus, the Platform provides capabilities in the four phases of a project:
- Start-up (Architecture, Provisioning, etc.)
- Development.
- DevOps.
- Change management.
And what are the differences when approaching these phases with traditional development or with development based on Onesait Platform? Well, all of these:
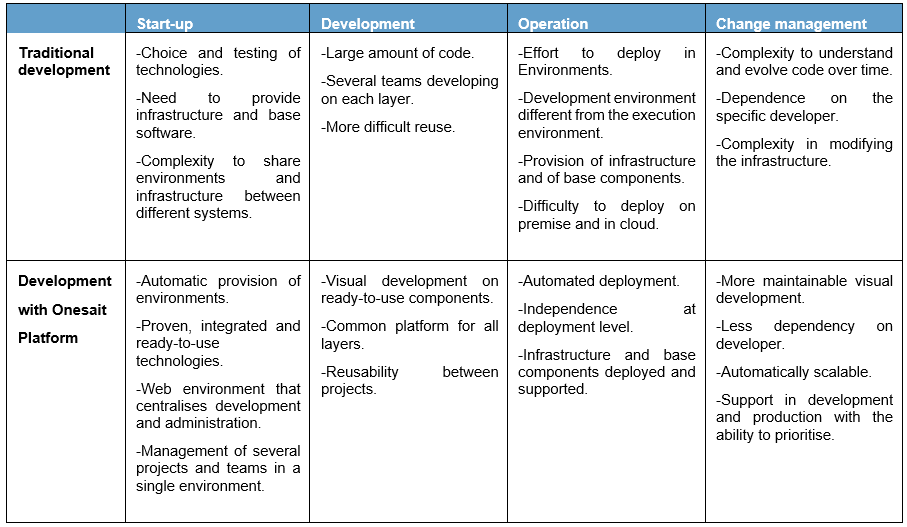
Onesait Platform’s Low Code Capabilities
At this point, we are going to detail some of the capabilities offered by Onesait Platform as a Low Code Platform. We are not going to see all of them because that would be an endless task, but we will see those that give an idea of the added value it offers.
Also, remember that the Onesait Platform is a Data-Centric platform, which makes it possible to manage the information life cycle, by enabling the construction of applications with «data at the core». We will analyse these capabilities on the basis of data processing:
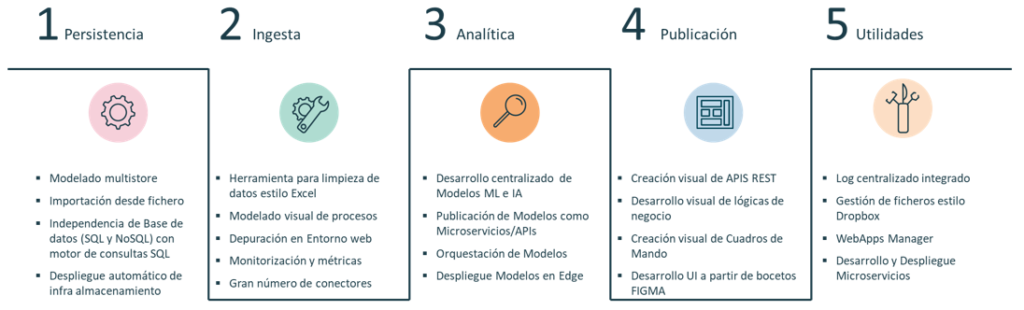
1.- Persistence layer
In this layer, the Platform provides capabilities such as multistore modelling, where the platform provides both independence of the database used, and the import from a file.
Let’s see some of these capabilities in detail.
Multistore modelling
The platform allows to handle, in a practically transparent way, databases of different types, from any relational database with JDBC driver, to NoSQL databases such as Mongo, Elasticsearch, Big Data repositories such as HIVE and Kudu, etc. It is also able to treat a REST API or a Digital Twin as another data source.
This abstraction is done through the concept of ontology, which makes it independent from the underlying database, always offering an SQL engine to access it (even when using NoSQL databases such as Mongo or Elasticsearch).
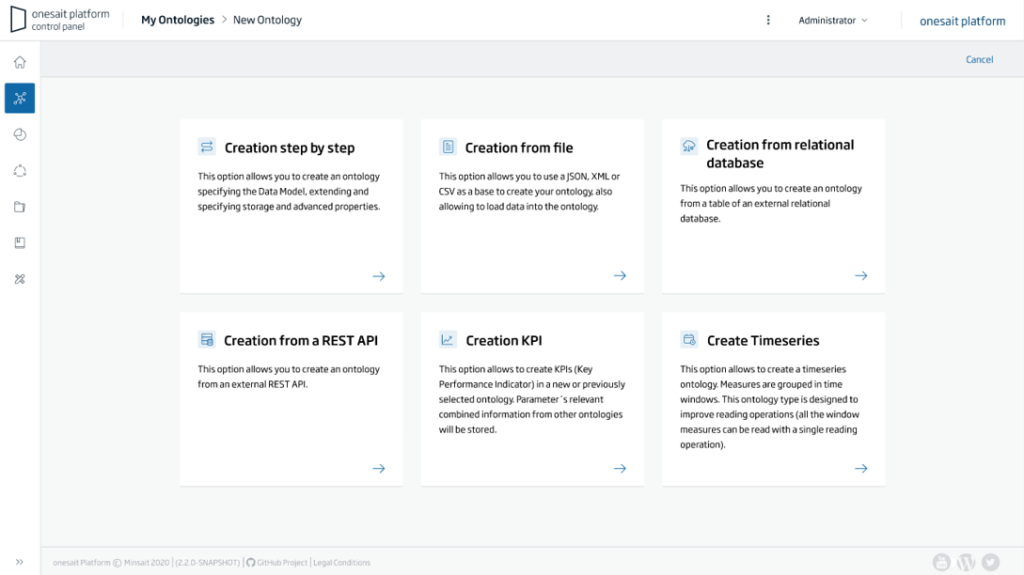
All this implies that:
- The modelling of the entities is done from the Platform’s Control Panel itself, and when you create the entity in the platform (the famous ontologies), those is responsible for creating the necessary tables or elements in the selected database.
- The Platform is in charge of provisioning or connecting to the selected databases, thus isolating the development team from this complexity.
- It also allows to connect to pre-existing databases and to create ontologies from existing tables.
- The ontology is represented as a JSON-Schema and the instances of the ontologies are JSON files. This is independent of the selected storage engine, as the platform takes care of converting to and from this model.
If you are interested in why it makes sense to use the Platform’s ontologies, we recommend you take a look at this guide we wrote some time ago.
Import from file
The Platform also offers a UI to easily upload a file, in JSON, CSV or XML format. The Platform will detect the file format and will automatically generate the ontology in the selected repository and load the data into it.
2.- Ingestion layer
In this layer, the Platform offers several capabilities, among which DataRefiner and DataFlow stand out.
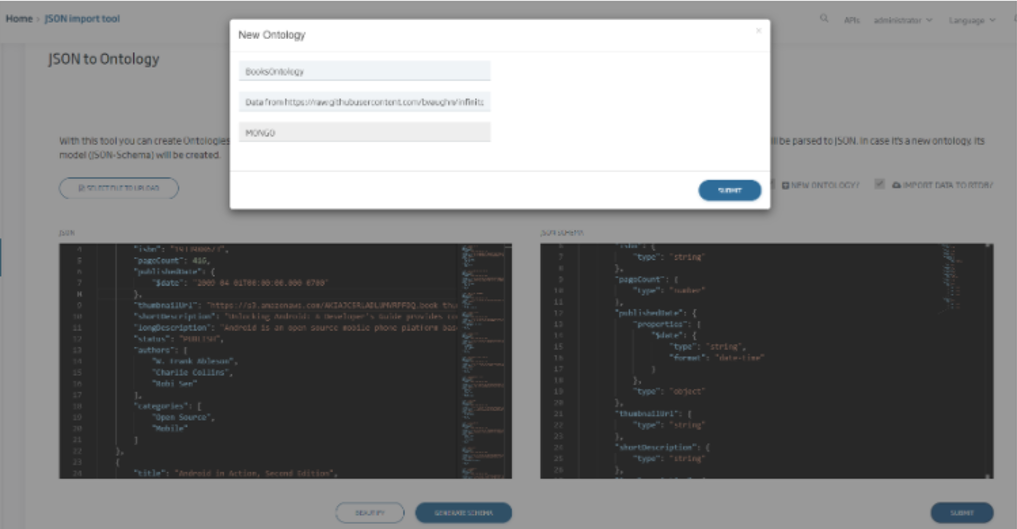
DataRefiner
The objective of this component is to «refine» the information that is loaded or extracted from the Platform. To this end, the tool offers an Excel-like interface that allows:
- An end-user to load, from a UI, data from various places, such as from their own PC, from a URL or from information stored in the Platform itself.
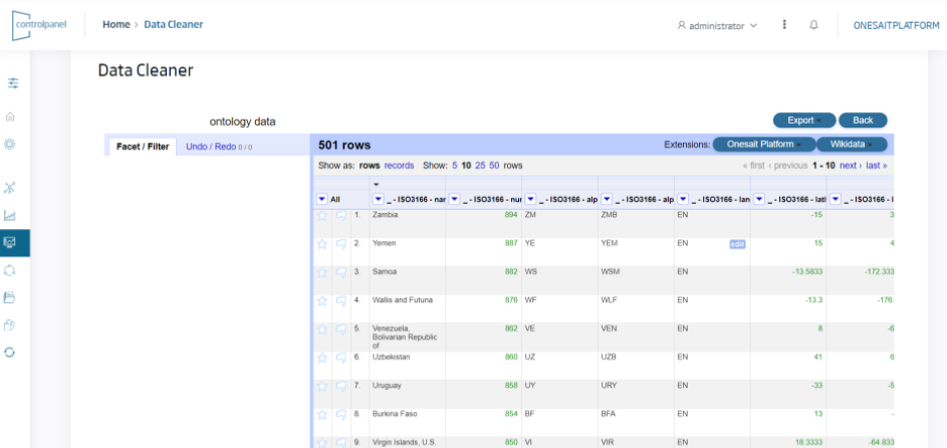
- Data to be uploaded in the main formats, including XLS, XLSX, XML, JSON, CSV, etc.
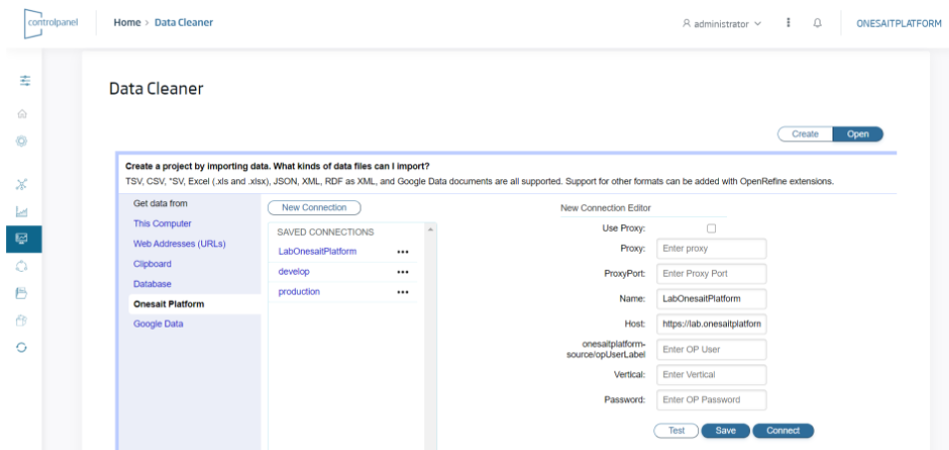
- The user to work with these data with an «Excel-like» interface to perform data profiling, including data cleansing, enhancement, restructuring or reconciliation.
- The «refined» data to be downloaded as files, or uploaded to the Platform as an ontology.
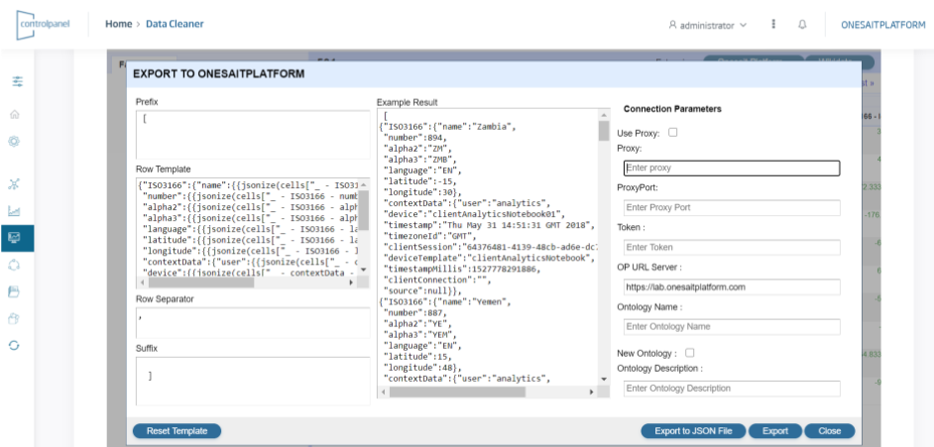
A comprehensive explanatory article on this component is available in our Development Portal.
DataFlow
This module allows you to create and configure data flows between sources and destinations in a visual way, both for ETL/ELT type processes and for Streaming flows, including transformations and data quality processes among these.
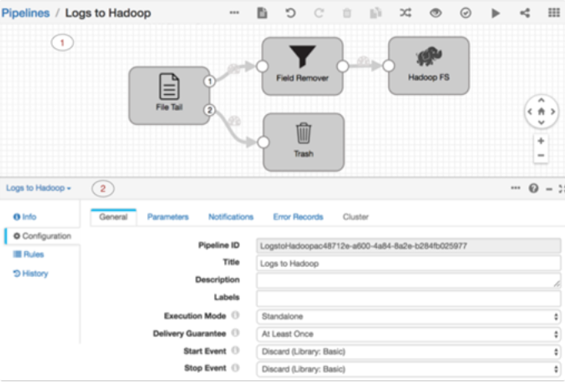
Let’s see a couple of examples:
- Ingest to Hadoop of the tail of a file with field elimination process.
- Ingest from a REST endpoint and upload to the Semantic DataHub of the Platform with data quality process.
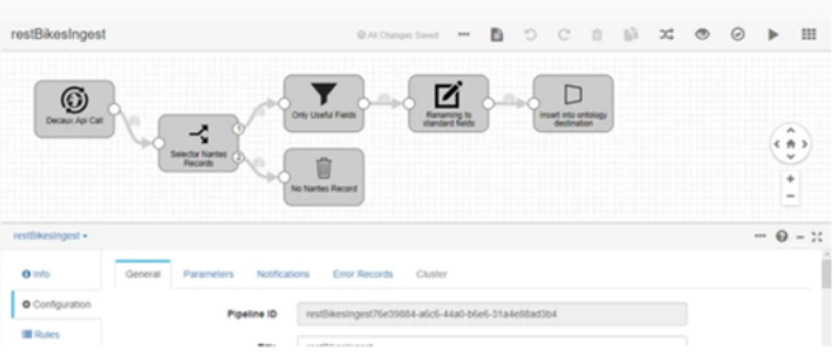
Beyond this, we should not forget that:
- It offers a large number of connectors for specific communications, both inbound and outbound, as well as processors. Among the main DataFlow connectors, we can find Big Data connectors with Hadoop, Spark, FTP, Files, Endpoint REST, JDBC, NoSQL DB, Kafka, Azure Cloud Services, AWS, Google, etc.
- All the creation, development, deployment and monitoring of the flows is done from the Platform’s web console (the so-called Control Panel).
And what does DataFlow look like when running? Well, in execution time, you will see something like this:
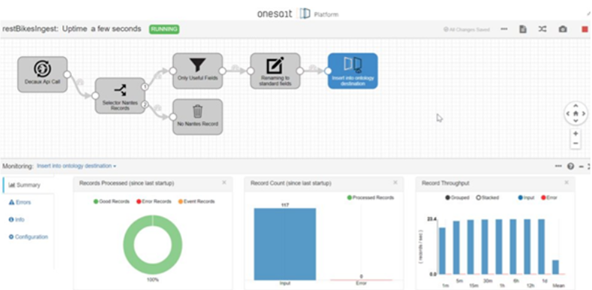
And in debug mode:
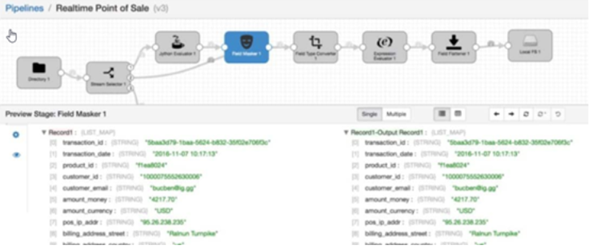
As in the previous cases, if you are interested in knowing this component in more detail, we have a complete guide in our Development Portal.
3.- Analytics layer
In this third layer, we have a centralised development of models based on Artificial Intelligence and Machine Learning, as well as the publication of Notebooks as microservices or through APIs.
Centralised development of ML and AI models
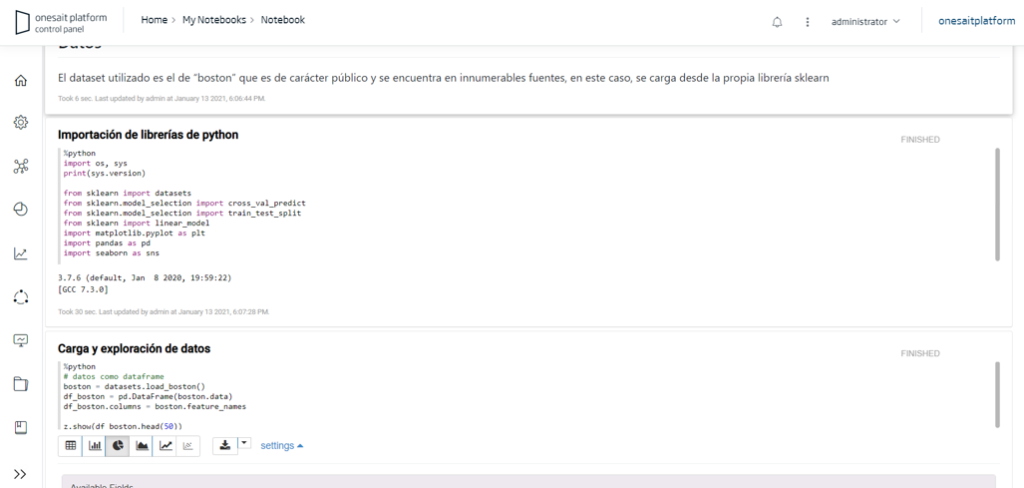
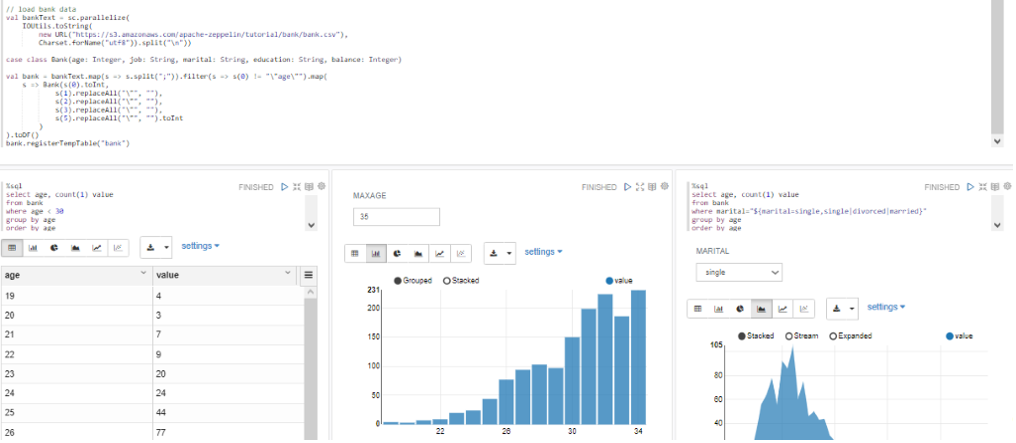
The module called Notebooks provides data scientists with a multi-user web environment in which they can develop analysis models on the information stored in the Platform with their favourite languages (Python, Spark, R, Tensorflow, Keras, SQL, etc.), and in an interactive way.
The notebooks are defined and managed from the Platform’s own Control Panel, from where you can create, edit and execute your models (notebooks) from the Control Panel itself. The image shows an example in Python:
This module allows the data scientists to create algorithms in various languages depending on the data scientist’s needs and preferences, supporting Python, Spark, R, SparkSQL, SQL, SQL HIVE, Shell, among others. Next you can see an example of data exchange between different languages:
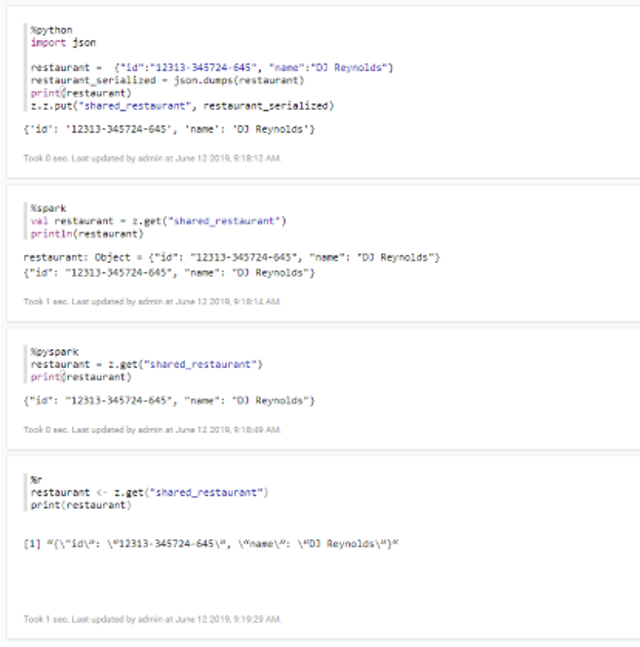
Thanks to the service capabilities of the REST API notebooks offered by the Platform, notebooks can be orchestrated and called to be executed from the FlowEngine, allowing execution control within the solution logic:
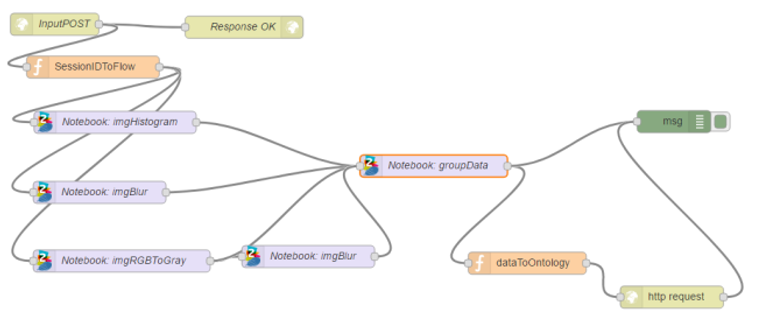
This allows you to create visualisations of different types, even adding HTML code via Angular, which allows you to create very sophisticated visualisations. These visualisations can be added as a gadget to the Dashboards engine, so that both data analytics and presentation of results is facilitated, either in a report or exposed as a gadget of the Platform. An example of data visualisation using graphs could be:
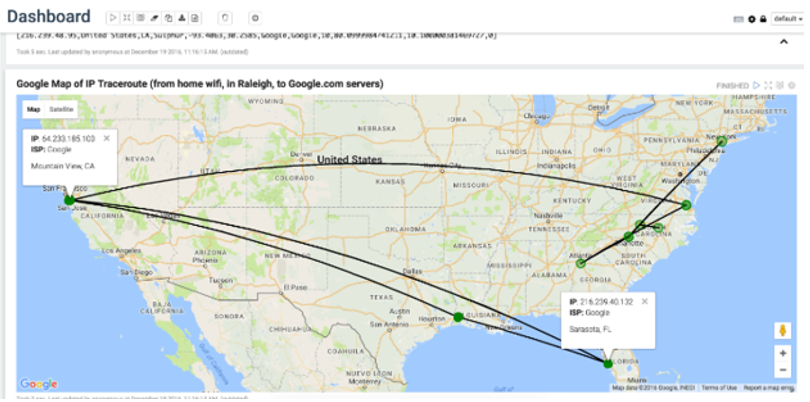
Another example of visualisation, this time of data with a spatial component on cartography:
You can find more information on this module in this section of the Developer Portal.
Publication of Notebooks as Microservices/APIs
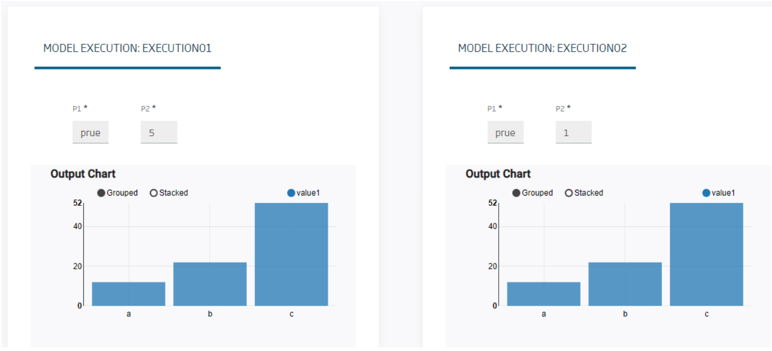
The Platform allows to create a Model from a notebook, indicating the input parameters and managing the execution result of each model:
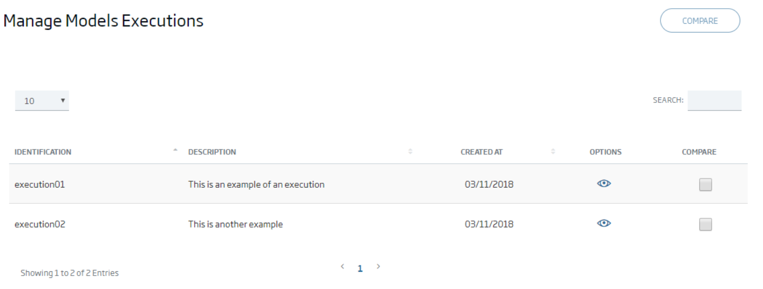
Also allowing to compare the result of a model:
The Platform also allows to publish a model as a microservice, so that the Platform allows to compile it, generate the Docker image and deploy it on the infrastructure. In other words, the Platform takes care of these steps:
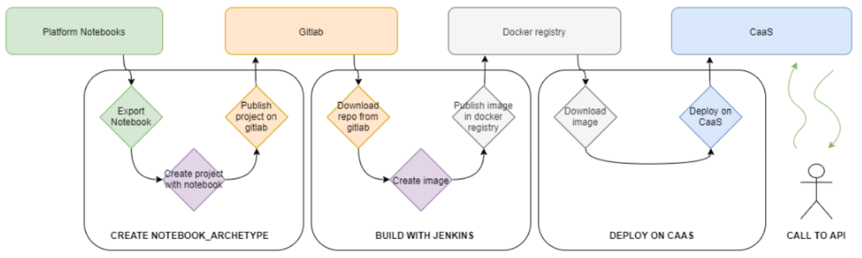
4.- Publication layer
This layer offers a rich set of tools.
Visual development of business logics
The Platform integrates a component called Flow Engine, which allows the creation of process flows, visually orchestrating pre-created components and customised logic in a simple way.
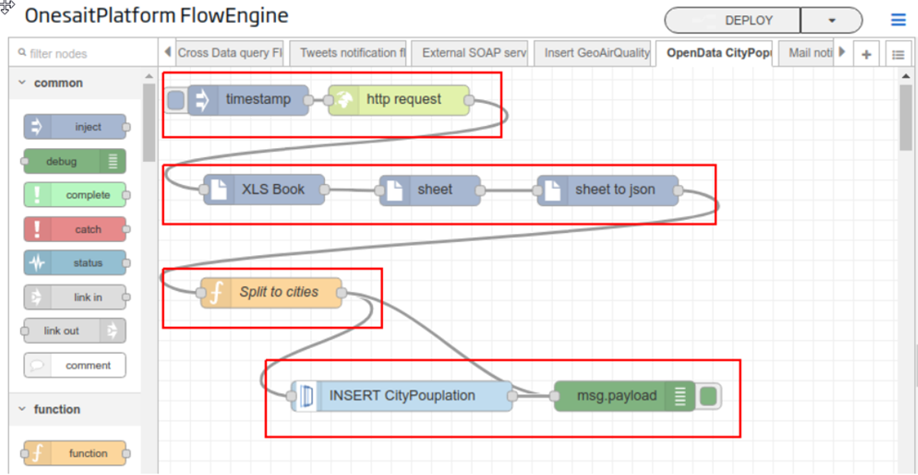
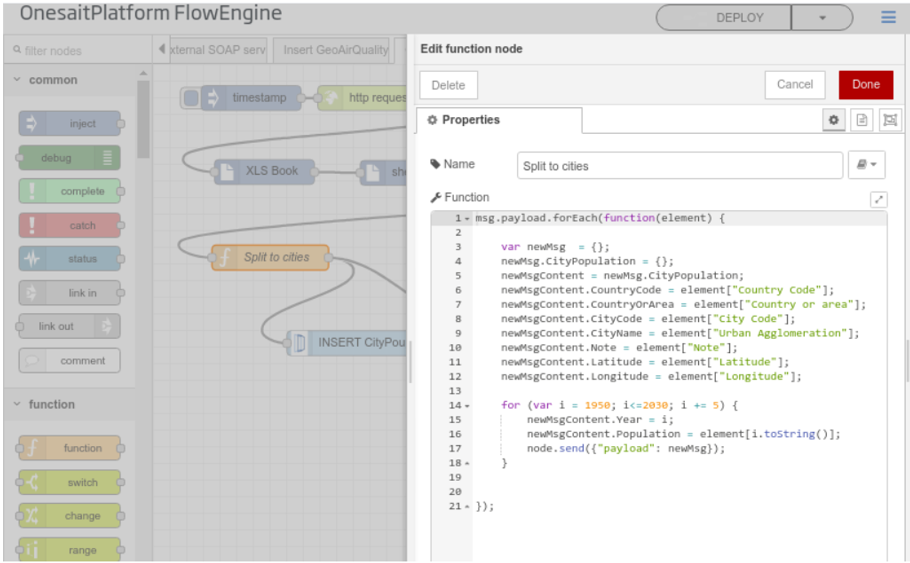
We offer a large number of connectors, ranging from protocols used at enterprise level such as HTTP, Web Services, Kafka, etc., to protocols used in devices such as MODBUS, Profibus, communication with social networks, etc., as well as components to integrate with the Platform’s capabilities.
This component also integrates with the rest of the components of the Platform, allowing, for example, to plan the sending of emails, trigger a Flow on the arrival of an ontology, orchestrate Dataflow pipelines, orchestrate notebooks, etc.
Visual creation of REST APIs
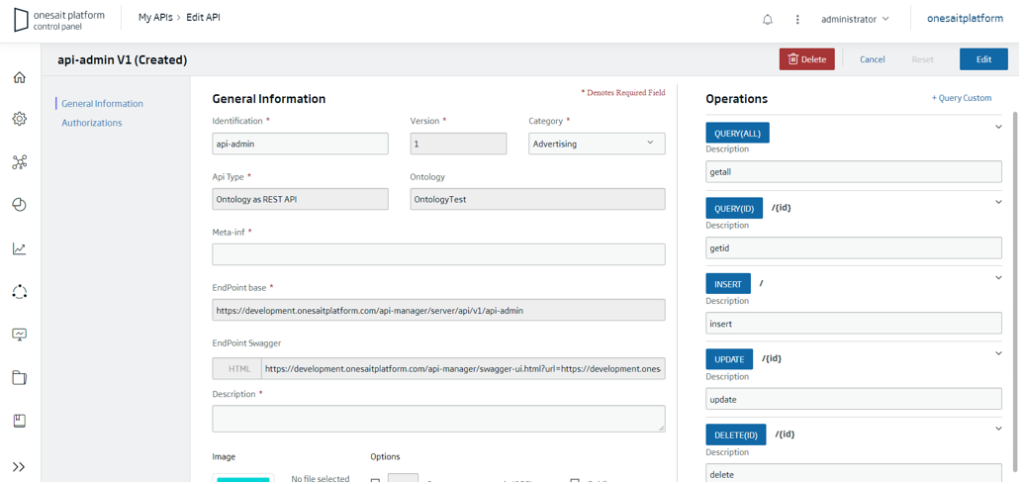
The Platform integrates an API Manager that makes REST APIs available, visually and without any programming, on the elements managed by the Platform. These APIs are defined and managed from the Control Panel itself:
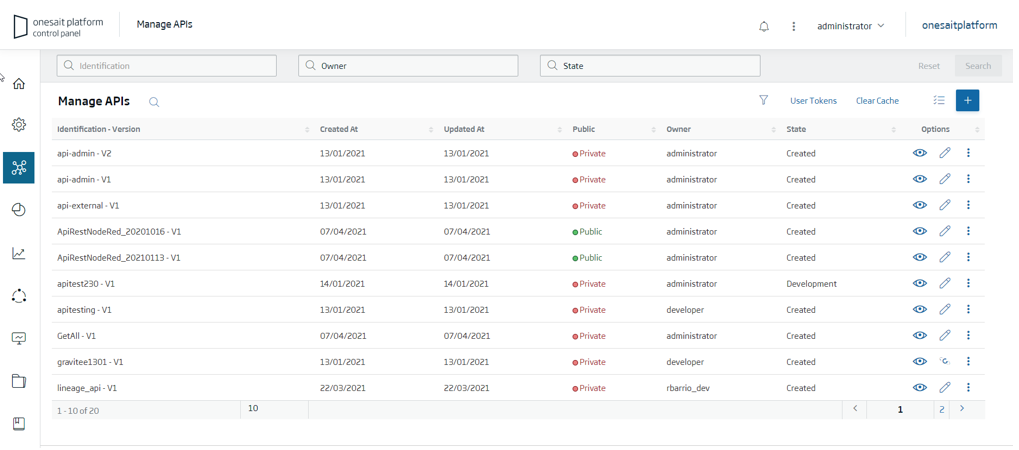
For example, this is how an API created on an ontology would be displayed:
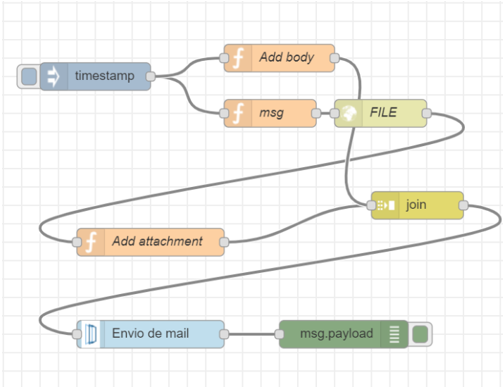
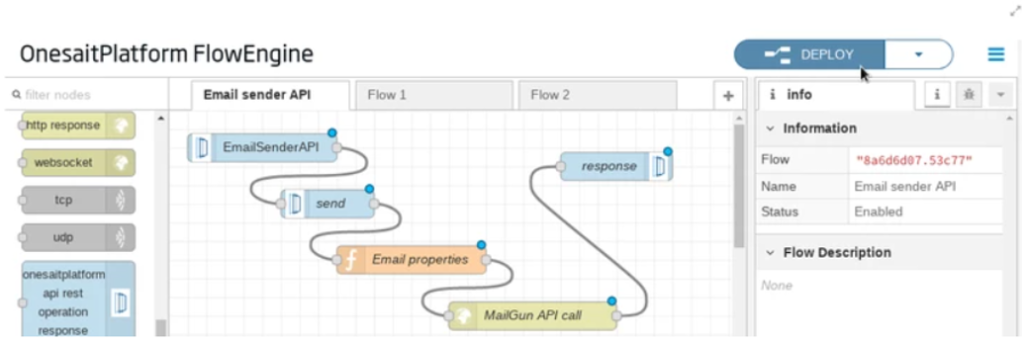
Associated with each API, the Open API descriptor is created, which allows APIs to be tested and invoked to check their operation. In addition, the Platform allows APIs to be created from flows built with the FlowEngine module. The following image shows how to create a REST API to send mails, encapsulating the actual provider:
Visual Creation of Dashboard
The Platform includes a Dashboard module that allows, in a simple way, the generation and visualisation of powerful dashboards on the information managed by the Platform, consumable from different types of devices and with analytical and Data Discovery capabilities.
These Dashboards are built from the Platform Control Panel itself and, based on queries made on the Platform entities (DataSources) and Gadgets, complete dashboards can be built.
A practical example of this can be seen in the following Dashboard on the incidence of COVID-19 in Portugal, created by our colleague Pedro Moura:
The Platform offers a set of pre-created gadgets for business users, facilitating and speeding up the creation of these dashboards.
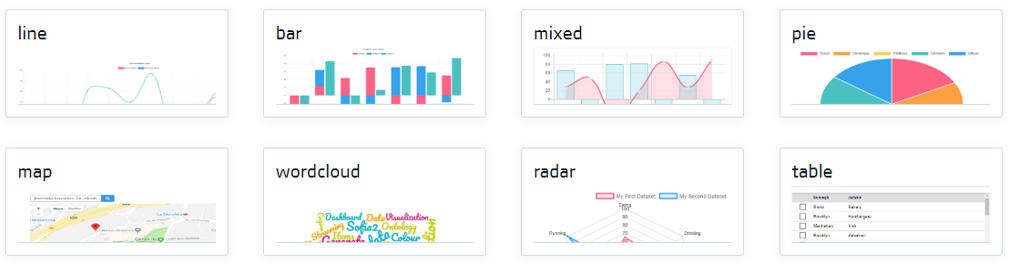
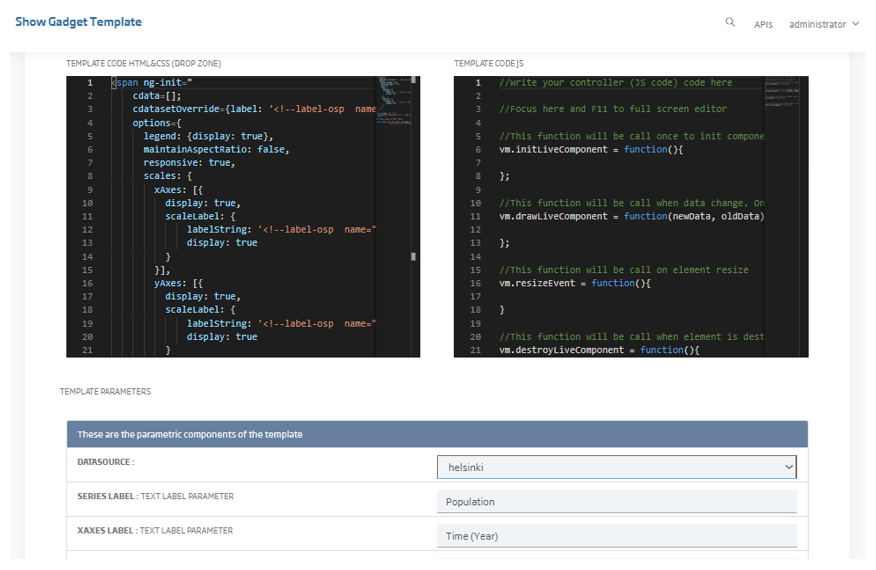
We also have the ability to create new gadgets through the Templates concept, where we can incorporate JavaScript libraries and create our own gadgets.
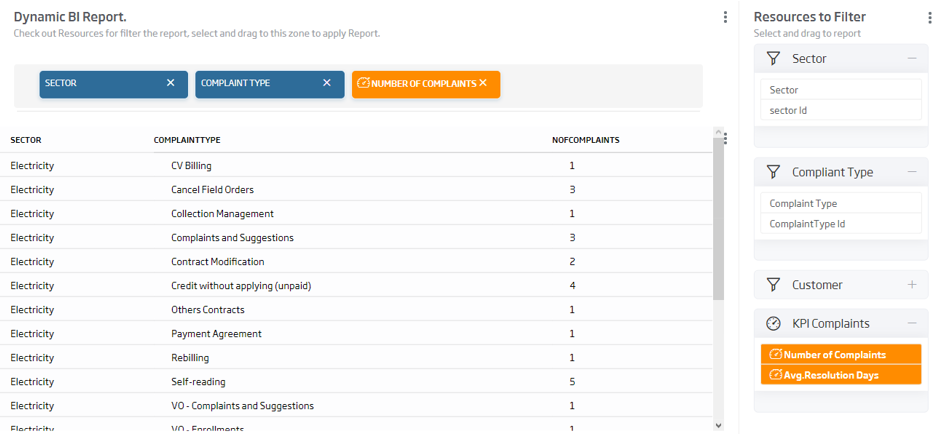
This module allows for the creation of Dashboards on any data managed as an ontology, independently of its repository, and it allows the interaction between gadgets of different types, so that an analysis and drill-down can be performed on the information of the different gadgets and their exploration dimensions.
This section of the Developer Portal provides detailed information and examples of this component.
UI development from FIGMA sketches
To finish with the publishing layer section, we will talk about a recently-added capability that allows you to generate UIs in Vue JS from a FIGMA layout.
This is as easy as binding the FIGMA layout to names in the visual and action elements:
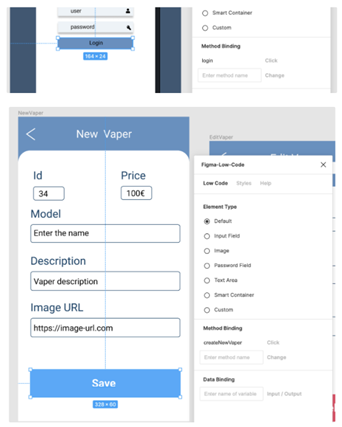
We then import the FIGMA design into the Control Panel, which will recognise the bindings and request additional information for the mapping, such as mappings from methods and variables to the APIs defined in the Platform:
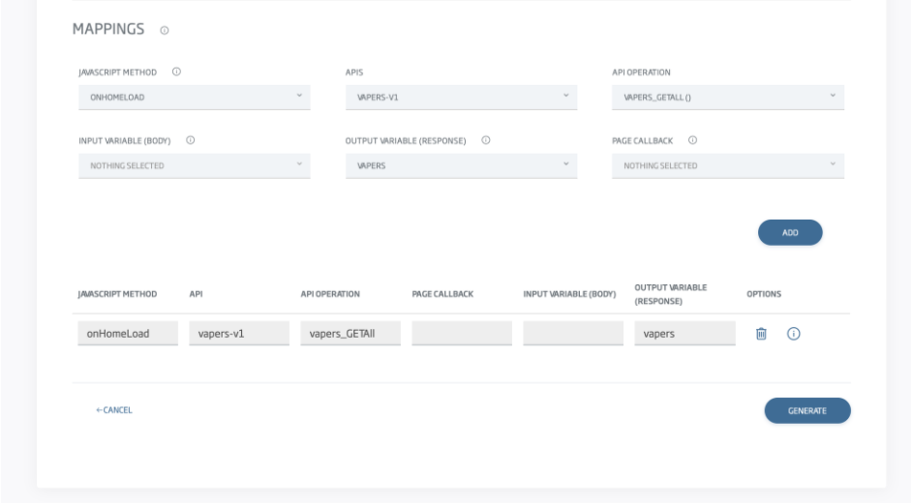
With just this, the Platform will generate a fully operational Vue.js application.
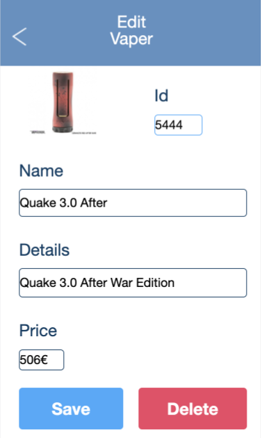
This guide explains in detail the process, or if you prefer we also have the video example (in Spanish).
Other Utilities
Finally, the Platform offers a set of tools that allow you to speed up development and focus on business development and not on the necessary technical services. The bulk of the utilities can be found in this section of the Developer Portal, although we are going to highlight some of them.
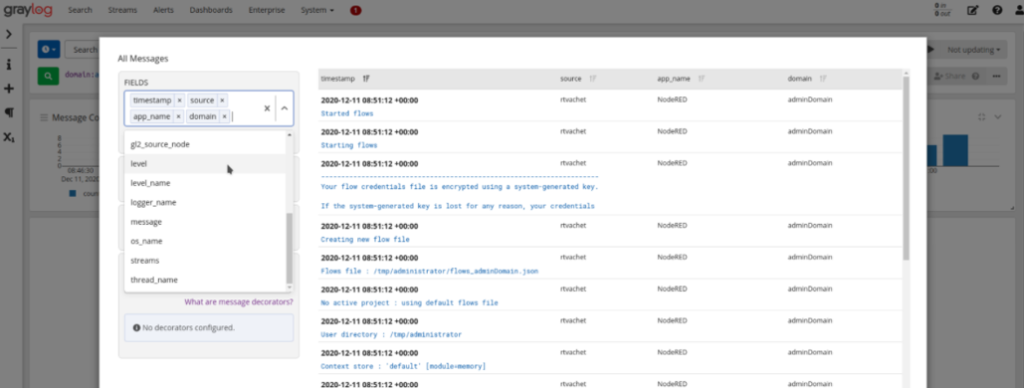
Centralised log
The platform integrates Graylog as a solution to centralise the logs of its modules and other modules, storing the logs in an Elasticsearch embedded with the Platform, and it offers a UI to exploit the information.
Dropbox-style file management
This utility, called File Repository, allows uploading and sharing all kinds of files either through the UI or through a REST API.
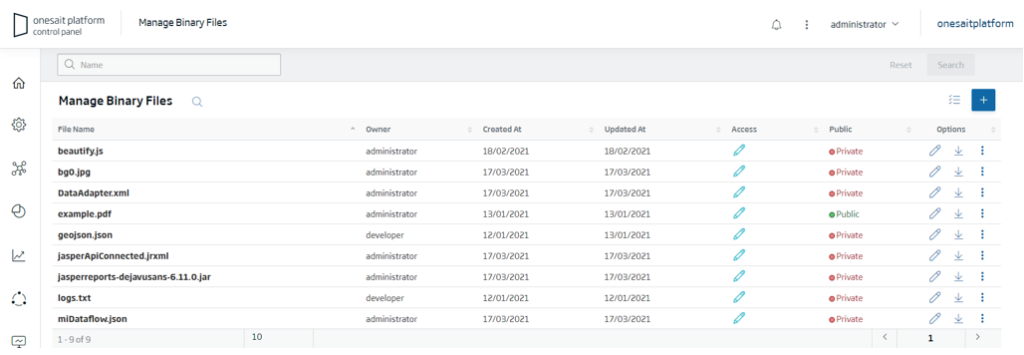
This utility is integrated with other components such as the DataFlow, that allows access to these files.
WebApps Manager
This utility allows you to deploy web applications (a complete HTML5 website: HTML, JS, CSS, images, etc.) from the Control Panel itself, so that the Platform is the one that makes this website available through an integrated web server.
Microservice development and deployment
The Platform provides a tool to create and manage the lifecycle of applications and of microservices (Spring and others) from the Control Panel, following the standards of the CI/CD cycle: creation, compilation, test execution, generation of Docker images and deployment in CaaS.
The functionalities provided by this life cycle from the Platform are:
- Creation of microservices.
- Code download and development.
- Code compilation and generation of Docker images from Jenkins.
- Deployment of Docker images on the CaaS platform.
- Update of a Microservice.
All this can be carried out easily from the management UI:

More information about Onesait Platform
If you found this interesting and you would like more information about Onesait Platform, we leave you with the following resources:



Pingback: Serverless in 2021 and Onesait Platform – Onesait Platform Blog
Pingback: Release 4.1.0-Outlaw for Onesait Platform – Onesait Platform Community