
Integración de Ollama como servicio de IA para análisis de imágenes
Continuando con la incorporación de herramientas que permitan trabajar con IA y LLMs en la Plataforma, en esta release 6.2.0-Xenon hemos incorporado Ollama como LLM que puede ejecutar directamente en la Plataforma sin conectar con servicios externos.
Conociendo Ollama
Ollama es una plataforma de inteligencia artificial que permite usar modelos LLM (Llama 3, Phi 3, Mistral, Gemma 2) de manera local para generar respuestas y proporcionar información sobre el contenido enviado.
Entre los diferentes modelos de LLM tenemos LLaVA (Large Language and Vision Assistant), un modelo de inteligencia artificial multimodal. Cuenta con un gran potencial en el procesamiento del lenguaje humano y visión por ordenador, ofreciendo respuestas con un alto nivel de comprensión.
Uso de Ollama desde la Plataforma
Hemos integrado Ollama como otro contenedor que ejecuta en el cluster K8s donde se despliega una instancia de la Plataforma y con el que comunicamos vía Endpoint REST.
Además hemos creado un servicio Spring Boot que usando Spring AI interactúa con Ollama y permite por ejemplo subir imágenes y preguntar por la imagen:
Ollama
Por lo tanto, Ollama se ha desplegado en el mismo paquete de Rancher donde se encuentra la imagen del servicio. Esto significa que ambos, la aplicación y Ollama, corren en el mismo entorno, permitiendo que la aplicación acceda a Ollama de manera directa y eficiente, sin necesidad de realizar llamadas a servicios externos.
Rancher permite la gestión y orquestación de múltiples servicios en un solo stack, lo que facilita el despliegue de servicios relacionados. De este modo, Ollama se ejecuta en el mismo contenedor o espacio de ejecución que la aplicación, permitiendo una comunicación directa y rápida entre ambos.
Como ambos servicios están corriendo en el mismo entorno, la comunicación con Ollama se realiza a través de la red interna del contenedor. Esto simplifica la configuración, ya que no se necesitan redes externas. Solo es necesario añadir una dependencia al archivo pom.xml para integrar Ollama con Spring AI, y así poder definir el Endpoint de Ollama como un servicio local en el archivo de configuración de la aplicación.
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>spring.ai.ollama.base-url=http://localhost:11434/Por otro lado, para que Ollama pueda procesar peticiones de IA, como análisis de imágenes o generación de texto, es necesario que los modelos de lenguaje correspondientes estén disponibles en el entorno de ejecución.
Ollama permite gestionar los modelos que se van a usar a través del comando ollama pull. Este comando se utiliza para descargar los modelos que la aplicación necesita, como LLaVA, Llama3, Mistral, entre otros. Esto permite optimizar el uso de recursos, ya que solo se descargan los modelos que son necesarios para el entorno. Ejemplo de descarga de un modelo:
ollama pull llavaServicio Spring Boot
Template de microservicio Ollama+Spring Boot+Spring AI
Se ha incluido un tipo de plantilla para microservicios en la Plataforma a partir de la versión 6.1.0-warcraft que contiene un esqueleto de microservicio diseñado para operar con Ollama, creado con Spring Boot y Spring AI.

Partiendo de la plantilla creada hemos creado un microservicio que ofrece un API REST y un frontal HTML.

API REST del microservicio
El microservicio ofrece una interfaz REST Open API con una serie de operaciones que podemos invocar para trabajar con Ollama. Cuenta con cuatro Endpoints:
- /chat: un método GET para enviar un mensaje de texto como parámetro. Este punto utiliza el modelo de lenguaje Llama3, que solo soporta texto.
- /image: un método POST para enviar un mensaje de texto y adjuntar una imagen para que la IA lo analice. Utiliza el modelo de lenguaje LLaVA.
- /default: un método POST para adjuntar una imagen y que la IA haga un análisis general de la misma. En este punto se le envía el mensaje por defecto «What do you see in this picture?». También utiliza el modelo de lenguaje LLaVA.
- /generic: un método POST que permite al usuario configurar su comunicación con Ollama. Este punto permite elegir qué modelo de LLM utilizar entre los disponibles (LLaVA, Llama3, Tinyllama y Mistral). En función del modelo que se elija se utilizarán unos parámetros u otros.
- Si se desea utilizar LLaVA, este punto deberá recibir como parámetros un mensaje de texto, una imagen, el nombre del modelo a utilizar (llava) y la temperatura. Este último dato hace referencia al grado de imaginación de la IA y se mide en decimales (0.4, por ejemplo).Si se desea utilizar Mistral, este punto recibe como parámetros un mensaje de texto, la URL web de una imagen, el nombre del modelo a utilizar (mistral) y la temperatura.
- Si se desea utilizar Tinyllama o Llama3, este punto solo deberá recibir como parámetros un mensaje de texto, el nombre del modelo a utilizar (tinyllama/llama3) y la temperatura, pues son modelos de LLM que solo cuentan con la capacidad para procesar texto.
A través de Swagger, se puede consultar y probar todos los Endpoints de la API REST:
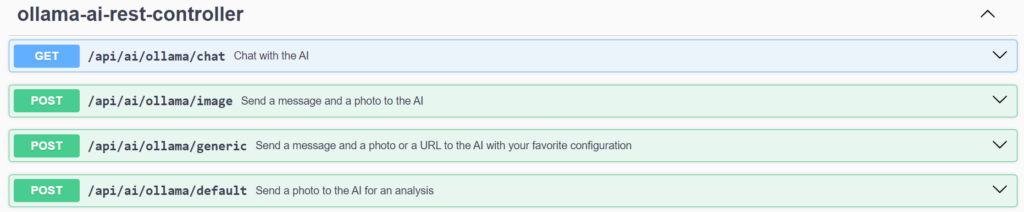
/api/ai/ollama/chat
En primer lugar, el método GET en «/api/ai/ollama/chat» recibe un mensaje de texto como parámetro y devuelva un String con la respuesta de la IA.


/api/ai/ollama/image
El método POST en «/api/ai/ollama/image» recibe un mensaje de texto y una imagen adjunta como parámetros. Del mismo modo, devuelve un String con la respuesta.


/api/ai/ollama/default
El método POST en «/api/ai/ollama/default» tan solo recibe una imagen adjunta como parámetro, y devuelve un String con lo que la IA percibe en la imagen enviada.


/api/ai/ollama/generic
Por último, el método POST en «/api/ai/ollama/generic» tiene tres parámetros obligatorios: el mensaje de texto, la temperatura o grado de imaginación y el modelo a escoger a través de un combo box.
En función del modelo se deberá adjuntar, o no, alguno de los dos parámetros opcionales: la URL web de una imagen o directamente el archivo de esta. La respuesta será un String de acuerdo al contenido enviado.


Capa Web
También se incluye un Frontal Web con una interfaz para interactuar y realizar las mismas acciones.
La interfaz se divide en cuatro pantallas, tres para los diferentes formularios y una para el resultado. Los formularios se presentan a través de un controlador y responden a las necesidades de cada uno de los métodos POST descritos en la API REST.
Por ello, cada uno muestra los campos necesarios en función de los parámetros de cada punto:
- /image: Un formulario con una caja de texto para introducir un mensaje, un botón para adjuntar una imagen y un botón para enviar.

- /default: Un formulario con un botón para adjuntar una imagen y un botón para enviar.

- /generic: Un formulario dinámico que muestra diferentes campos en función del modelo que se escoja en el combo-box. Los únicos campos permanentes con la caja de texto para el mensaje y para escoger el grado de temperatura. Y, dependiendo del modelo, puede aparecer un botón para adjuntar una foto (LLaVA), un caja de texto para introducir la URL de una imagen (Mistral) o puede no aparecer nada, si el modelo de LLM escogido no soporta imágenes (Tinyllama o Llama3).



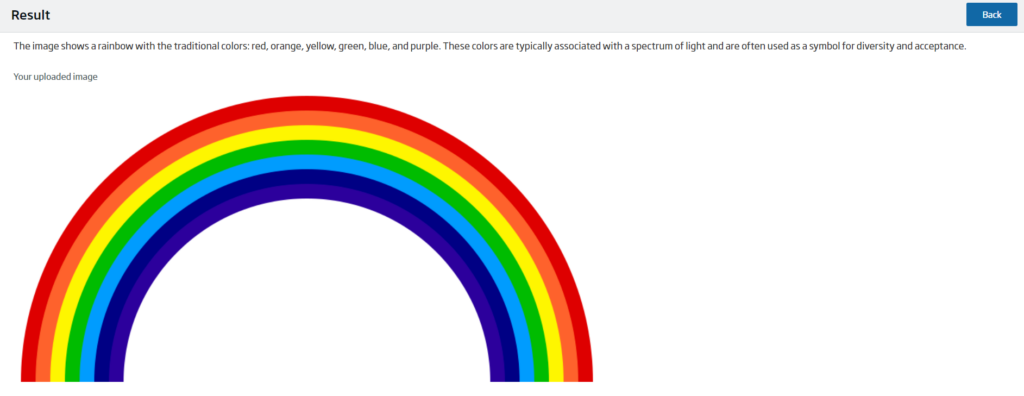
Por otro lado, la pantalla de resultado está formada por la respuesta de Ollama, la imagen a analizar, si es necesaria, y un botón para volver al formulario correspondiente.
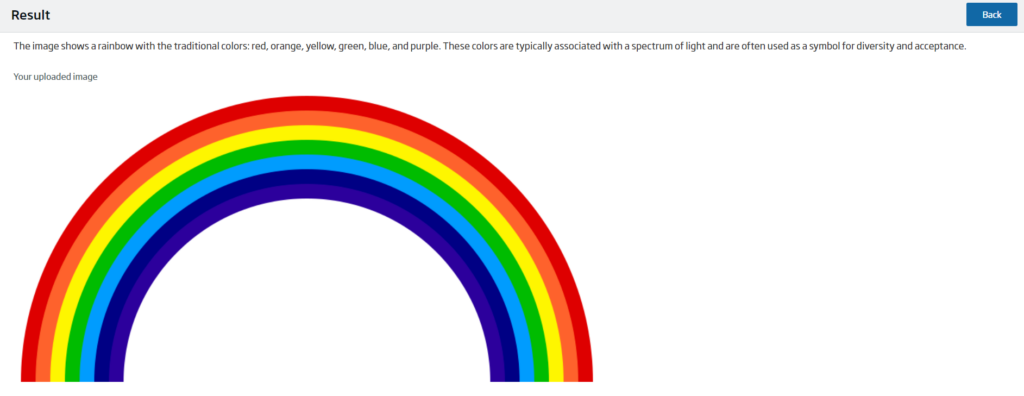

Spring AI back end
Ollama se complementa muy bien con Spring AI, facilitando la comunicación y la implementación, sin la necesidad de tener que hacer llamadas explícitas al API de Ollama.
A través de la dependencia mencionada anteriormente, Spring AI permite la autoconfiguración de un cliente de chat Ollama. Además, cuenta con un gran número de propiedades para personalizar la comunicación a gusto del usuario.
Entonces, la comunicación con Ollama se realiza en el servicio a través de instancias de la clase OllamaChatModel.

Esta cuenta con el método .call(), el cual recibe como parámetros el mensaje, la imagen y las opciones de creación del chat, como el modelo de LLM o el grado de temperatura; y devuelve la respuesta de Ollama como una instancia de la clase ChatResponse. Para conseguir el String puro de la respuesta es necesario sesgar el ChatResponse a través de los métodos .getResult().getOutput().getContent().

API disponibilizada en el API Manager
El microservicio que veíamos antes ha sido publicado como API en el API Manager de la Plataforma para poder usarlo de forma sencilla en cualquiera instalación que tenga disponibilizado el servicio Ollama:

Imagen de cabecera: Ollama


