
Integration of Ollama as an AI service for image analysis
Continuing with the incorporation of tools that allow working with AI and LLMs in the Platform, in this release 6.2.0-Xenon we have incorporated Ollama as an LLM that can run directly in the Platform without connecting to external services.
About Ollama
Ollama is an artificial intelligence platform that allows using LLM models (Llama 3, Phi 3, Mistral, Gemma 2) locally to generate responses and provide information about the content sent.
Among the different LLM models we have LLaVA (Large Language and Vision Assistant), a multimodal artificial intelligence model. It has great potential in human language processing and computer vision, providing answers with a high level of understanding.
Using Ollama from the Platform
We have integrated Ollama as another container running on the K8s cluster where an instance of the Platform is deployed and with which we communicate via REST Endpoint.
In addition we have created a Spring Boot service that using Spring AI interacts with Ollama and allows for example to upload images and ask for the image:
Ollama
Therefore, Ollama has been deployed in the same Rancher package as the service image. This means that both the application and Ollama run in the same environment, allowing the application to access Ollama directly and efficiently, without the need for external service calls.
Rancher allows the management and orchestration of multiple services on a single stack, which facilitates the deployment of related services. In this way, Ollama runs in the same container or execution space as the application, allowing direct and fast communication between the two.
As both services are running in the same environment, communication with Ollama is done through the container’s internal network. This simplifies the configuration, as no external networks are needed. It is only necessary to add a dependency to the pom.xml file to integrate Ollama with Spring AI, so that the Ollama Endpoint can be defined as a local service in the application configuration file.
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>spring.ai.ollama.base-url=http://localhost:11434/On the other hand, for Ollama to be able to process AI requests, such as image analysis or text generation, the corresponding language models need to be available in the execution environment.
Ollama allows to manage the models to be used through the ollama pull command. This command is used to download the models that the application needs, such as LLaVA, Llama3, Mistral, among others. This allows to optimise the use of resources, since only the models that are necessary for the environment are downloaded. Example of downloading a model:
ollama pull llavaSpring Boot Service
Ollama+Spring Boot+Spring AI microservice template
A microservice template type has been included in the platform from version 6.1.0-warcraft that contains a microservice skeleton designed to operate with Ollama, created with Spring Boot and Spring AI.

Partiendo de la plantilla creada hemos creado un microservicio que ofrece un API REST y un frontal HTML.

Microservice REST API
The microservice provides a REST Open API interface with a set of operations that we can invoke to work with Ollama. It has four Endpoints:
- /chat: a GET method to send a text message as a parameter. This point uses the Llama3 language model, which only supports text.
- /image: a POST method to send a text message and attach an image for the AI to analyse. It uses the LLaVA language model.
- /default: a POST method to attach a picture and have the AI do a general analysis of it. At this point the default message ‘What do you see in this picture?’ is sent to it. It also uses the LLaVA language modeliliza el modelo de lenguaje LLaVA.
- /generic: a POST method that allows the user to configure his communication with Ollama. This point allows the user to choose which LLM model to use among those available (LLaVA, Llama3, Tinyllama and Mistral). Depending on the model chosen, some parameters will be used or others.
- If you want to use LLaVA, this point should receive as parameters a text message, an image, the name of the model to be used (llava) and the temperature. This last data refers to the degree of imagination of the AI and is measured in decimals (0.4, for example).If you want to use Mistral, this point receives as parameters a text message, the web URL of an image, the name of the model to be used (mistral) and the temperature.
- If you want to use Tinyllama or Llama3, this point should only receive as parameters a text message, the name of the model to be used (tinyllama/llama3) and the temperature, as they are LLM models that only have the capacity to process text.
Through Swagger, all REST API Endpoints can be queried and tested:
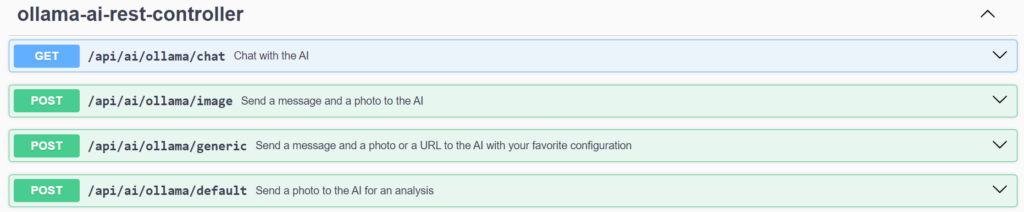
/api/ai/ollama/chat
First, the GET method in ‘/api/ai/ollama/chat’ receives a text message as parameter and returns a String with the AI response.


/api/ai/ollama/image
The POST method in ‘/api/ai/ollama/image’ receives a text message and an attached image as parameters. Likewise, it returns a String with the response.


/api/ai/ollama/default
The POST method in ‘/api/ai/ollama/default’ just receives an attached image as a parameter, and returns a String with what the AI perceives in the image sent.


/api/ai/ollama/generic
Finally, the POST method in ‘/api/ai/ollama/generic’ has three mandatory parameters: the text message, the temperature or degree of imagination and the model to be chosen through a combo box.
Depending on the model, one of the two optional parameters must be attached or not: the web URL of an image or directly the image file. The response will be a String according to the content sent.


Web Layer
A Web Front End is also included with an interface to interact and perform the same actions.
The interface is divided into four screens, three for the different forms and one for the result. The forms are presented through a controller and respond to the needs of each of the POST methods described in the REST API.
Therefore, each one shows the necessary fields depending on the parameters of each point:
- /image: A form with a text box to enter a message, a button to attach an image and a button to send.

- /default: Un formulario con un botón para adjuntar una imagen y un botón para enviar.

- /generic: A dynamic form showing different fields depending on the model chosen in the combo-box. The only permanent fields are the text box for the message and for choosing the degree of temperature. And, depending on the model, a button may appear to attach a photo (LLaVA), a text box to enter the URL of an image (Mistral) or nothing at all, if the LLM model chosen does not support images (Tinyllama or Llama3).



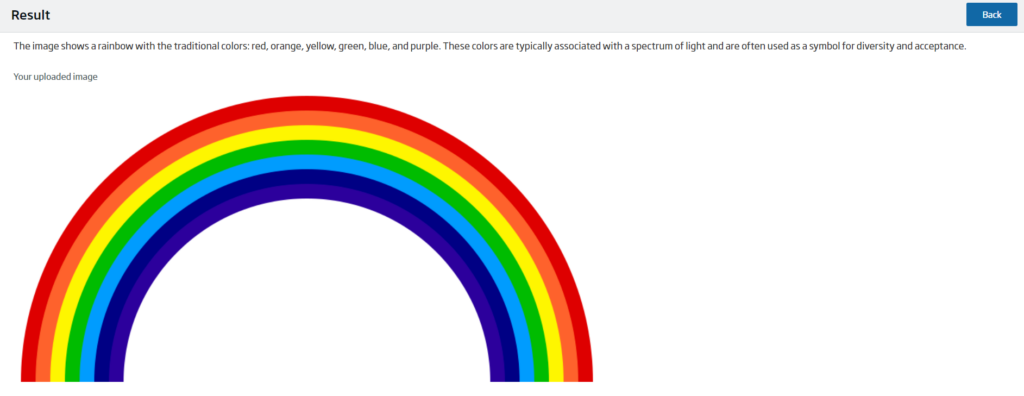
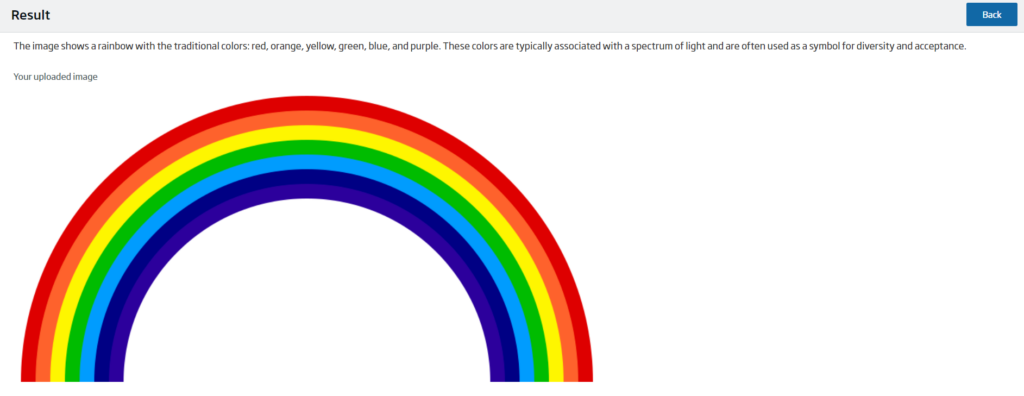
On the other hand, the result screen consists of Ollama’s answer, the image to be analysed, if necessary, and a button to return to the corresponding form.

Spring AI back end
Ollama complements Spring AI very well, facilitating communication and implementation, without the need to make explicit calls to the Ollama API.
Through the aforementioned dependency, Spring AI allows the self-configuration of an Ollama chat client. In addition, it has a large number of properties to customise the communication to the user’s liking.
Then, the communication with Ollama is done in the service through instances of the OllamaChatModel class.

EThis has the .call() method, which receives as parameters the message, the image and the chat creation options, such as the LLM model or the degree of temperature; and returns Ollama’s response as an instance of the ChatResponse class. To get the pure String of the response it is necessary to bias the ChatResponse through the .getResult().getOutput().getContent() methods.

API available in the API Manager
The microservice we saw before has been published as an API in the platform API Manager so that it can be easily used in any installation that has the Ollama service available:

Header Image: Ollama


