
Análisis de Redpanda como sustituto de Kafka
Redpanda es un reemplazo directo de Kafka como broker de eventos para el uso de clientes Kafka (consumidores/productores)
Está desarrollado en C++, afirmando que de esta manera es más eficiente que Kafka (implementado en Java) y por tanto no usa una JVM, permitiendo una mejor gestión del uso de memoria.
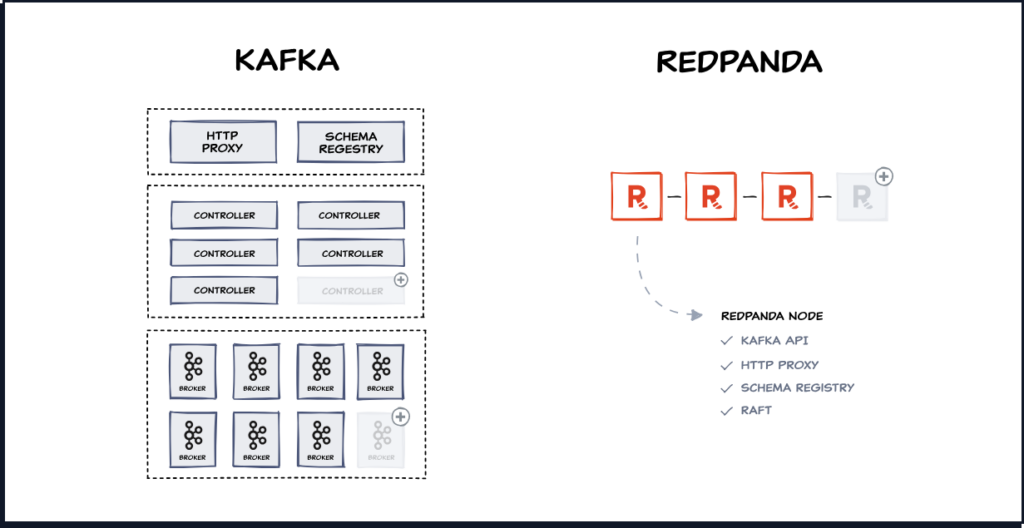
También elimina la necesidad de utilizar Zookeeper/KRaft, ya que basan Redpanda en un único binario con todas las funcionalidades requeridas. De esta manera, Redpanda implementa el protocolo de consenso Raft.
Redpanda frente a Kafka
Ya hemos podido ver las mayores diferencias entre Kafka y Redpanda, al menos a nivel de implementación y/o arquitectura:
| Concepto | Kafka | Redpanda |
|---|---|---|
| Licencia | Apache 2.0 | Community Edition en BSL y otra licencia comercial para Enterprise Edition. |
| Implementación | JAVA | C++ |
| Módulos | Brokers, Zookeeper/KRaft controller, Schema Registry, etc. | Arquitectura de un sólo binario. Toda la funcionalidad se implementa en el nodo de Redpanda. |
El principal atractivo de Redpanda es la simplicidad de configuración y velocidad (baja latencia), así como el mejor uso de los recursos para el clúster de brokers desplegados.
Así lo afirma Redpanda con el siguiente benchmark, en el que se afirma una reducción en coste de 6x y un aumento de velocidad 10x.
Como contrapunto, tenemos este otro benchmark, creado a partir del anterior, por un empleado de Confluent, donde comenta algunos puntos interesantes sobre la configuración de Kafka y los resultados de los mismos. Este análisis es bastante más detallado, teniendo en cada uno de los puntos que veremos a continuación, una subsección explicando el resultado obtenido y cómo lanzar dicho benchmark.
Los resultados más significativos son:
- La latencia aumenta en Redpanda a medida que aumentan los productores: según los datos, cuando subimos de cuatro (benchmark de Redpanda) a cincuenta (benchmark de Kafka) productores, el tiempo de latencia se dispara en Redpanda.
- Deterioro del rendimiento en ejecuciones continuadas en el tiempo: tras doce horas de ejecución, Redpanda muestra un aumento en la latencia que viene de los discos NVMe. En concreto, se achaca a cómo Redpanda acaba distribuyendo los datos de las particiones, siguiendo un patrón más similar a acceso aleatorio, lo cual lleva a un mayor IO de disco. En Kafka no sucede por la naturaleza más secuencial de organizar los datos.
- Deterioro de la latencia en Redpanda cuando se alcanza el punto de retención de datos: esto es muy importante, ya que en un entorno de producción lo habitual es estar siempre en este punto, en el que los tópicos se vayan «purgando» según las políticas de retención definidas.
- El impacto de escribir mensajes/eventos con clave: si bien es cierto que para la mayor parte de nuestros casos de uso no hacemos uso de esta funcionalidad (que ayuda a repartir los mensajes entre particiones de manera única y garantizar el orden), en los casos en los que es necesario, se detecta una reducción significativa del throughput para Redpanda cuando también se aumentan los productores.
- Redpanda no llega al límite de transferencia de los discos NVMe con acks=1: esta configuración nos acepta la escritura del dato siempre que haya sido persistido en el líder, no esperando a la replicación completa. En estos casos se observa que Redpanda no alcanza el throughput límite de los discos NVMe mientras que Kafka sí.
- Problemas con Redpanda a la hora de agotar el backlog: supongamos que en un escenario dado, mantenemos los clústers de Kafka/Redpanda corriendo, así como los productores de datos, pero paramos los consumidores. Al volver a conectar dichos consumidores, se detecta que Redpanda tiene problemas para ir bajando el lag en el consumo de datos.
Integración en Onesait Platform
Además de la comparativa de rendimiento, latencias y throughput, si analizamos Redpanda como reemplazo directo de Kafka vemos que permite autenticación y autorización.
Como parte de la integración de Kafka dentro de la Plataforma, hacemos uso de nuestro propio plugin de autenticación y por debajo usamos la Admin API de Kafka para generar las ACLs de esos usuarios/ clientes digitales creados.
Desde Redpanda en su documentación vemos que soporta los siguiente métodos de autenticación:
| API | Supported Authentication Methods |
|---|---|
| Kafka API | – SASL – SASL/SCRAM – SASL/OAUTHBEARER (OIDC) – SASL/GSSAPI (Kerberos) – mTLS |
| Admin API | – Basic authentication – OIDC |
| HTTP Proxy (PandaProxy) | – Basic authentication – OIDC |
| Schema Registry | – Basic authentication – OIDC |
Esto nos deja fuera la posibilidad de usar nuestro plugin de seguridad tanto para la API de Kafka como para la de Admin.
Conclusiones
Tras ver todo esto, no creemos que Redpanda pueda ser un reemplazo directo del uso de Kafka para nuestros casos de uso habituales, a menos a día de hoy.
En la mayoría de proyectos que usan Kafka con la Plataforma, estamos en posiciones donde entran en juego algunos de los puntos mencionados anteriormente, principalmente los puntos 2, 3 y 6 de la comparativa de bechmarks:
- Ejecuciones continuadas en el tiempo: para la mayoría de nuestros casos de uso, Kafka es un bus de entrada de datos/ comunicación de procesos, que permanece en continua conexión.
- Retención de datos: dado que son procesos continuados en el tiempo, lo habitual es que siempre entre en juego la retención de datos (por defecto a siete días, pero configurable).
- Agotar el backlog: hay casos de uso en los que el backlog aumenta (productores que envían de manera irregular, paradas de mantenimiento, etc.) y tenemos que garantizar que acaba bajando a cero lo más rápidamente posible.
Imagen de cabecera: Ravi Pinisetti en Unsplash


