
Generación y publicación de modelos de Machine Learning
Hoy os traemos un pequeño workshop en el que vamos a aprender, partiendo de datos sobre diabetes, cómo generar un modelo de Machine Learning que prediga una medida cuantitativa de progresión de la enfermedad, un año después de la línea base.
Para ello, vamos a utilizar los siguientes módulos de Onesait Platform:
- File Repository sobre MinIO: para guardar el conjunto de datos original. Cargaremos el archivo utilizando el módulo Create Entity in Historical Database.
- Notebooks: para tener un proceso paramétrico para obtener los datos de MinIO, entrenar y generar el modelo y registrar todo en MLFlow.
- Gestor de Modelos (MLFlow): para registrar todos los experimentos del cuaderno y guardar el modelo y otros archivos para el entrenamiento.
- Módulo Serverless: para crear una función Python escalable que, usando el modelo, pueda predecir la progresión de la enfermedad.
Dataset
Se obtuvieron diez variables de base, edad, sexo, índice de masa corporal, presión y seis mediciones de suero sanguíneo, para cada uno de los 442 pacientes diabéticos, así como la respuesta de interés, una medida cuantitativa de la progresión de la enfermedad un año después de la línea de base.
Características del dataset
- Número de instancias: 44.
- Número de atributos: Las diez primeras columnas son valores predictivos numéricos.
- Target: La undécima columna es una medida cuantitativa de la progresión de la enfermedad un año después de la línea de base.
Información sobre atributos (en inglés)
- age age in years
- sex sex of the patient
- bmi body mass index
- bp average blood pressure
- s1 tc, total serum cholesterol
- s2 ldl, low-density lipoproteins
- s3 hdl, high-density lipoproteins
- s4 tch, total cholesterol / HDL
- s5 ltg, possibly log of serum triglycerides level
- s6 glu, blood sugar level
Nota: cada una de estas diez variables de características se ha centrado en la media y se ha escalado por la desviación estándar multiplicada por «n_muestras» (es decir, la suma de cuadrados de cada columna suma el valor de «1»).
URL de la fuente: https://www4.stat.ncsu.edu/~boos/var.select/diabetes.html
Dataset: https://www4.stat.ncsu.edu/~boos/var.select/diabetes.tab.txt
Desarrollo
Paso 1: cargar los datos en MinIO
En primer lugar, vamos a crear una Entidad de la Plataforma de tipo Entidad en Base de Datos Histórica, donde almacenaremos la información. Para ello, navegaremos al menú de Development > My Entities.
Desde el listado de entidades, pulsaremos el botón de «+» situado en la parte superior derecha de la pantalla para lanzar el gestor de creación de entidades.

De entre las diferentes opciones, escogeremos la de «Create Entity in Historical Database»:
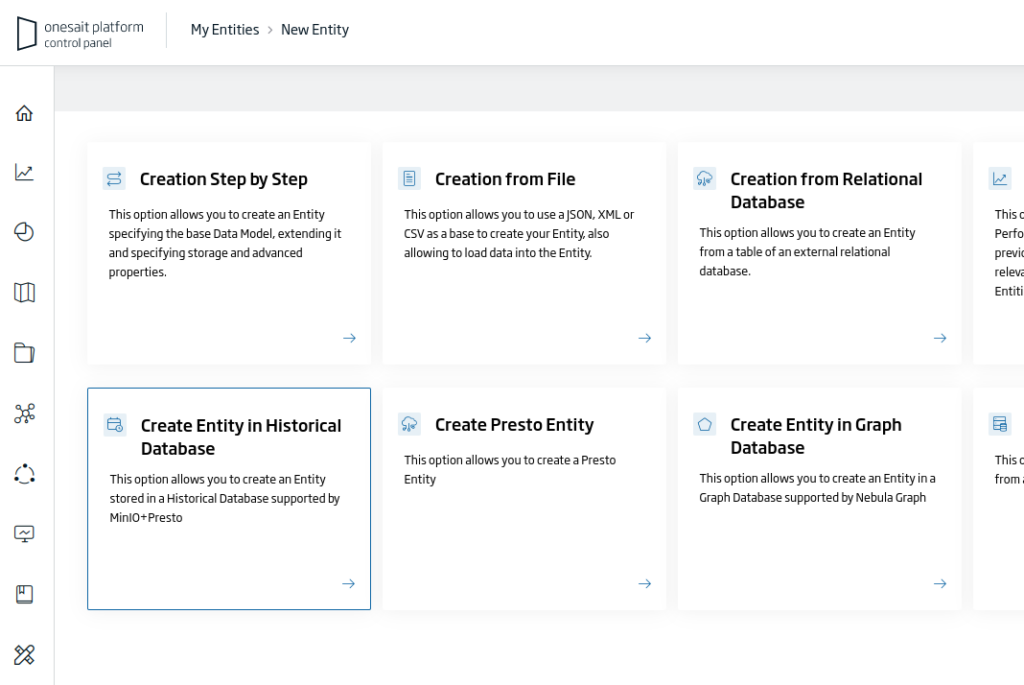
Esto nos abrirá el asistente de creación de la Entidad, en donde tendremos que rellenar los siguientes datos:
- Identification: el identificador único de nuestra Entidad. Para el ejemplo: «diabetes_raw».
- Meta-Information: conjunto de términos que definan la entidad. Para el ejemplo: «Diabetes, Dataset, ML».
- Description: un pequeño texto descriptivo de la entidad.
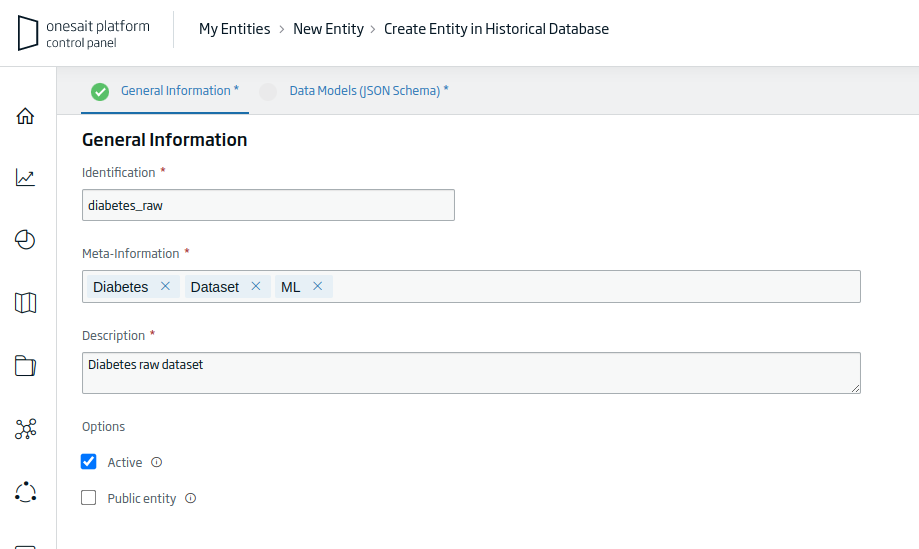
Una vez que tengamos rellena la información que nos piden, pulsaremos en el botón de «Continuar» para seguir con el proceso de creación.
Seguidamente tendremos que rellenar todas las columnas del archivo con el formato de cadena; esto tiene que hacerse así porque el archivo CSV necesita ser cargado con este tipo de columna.
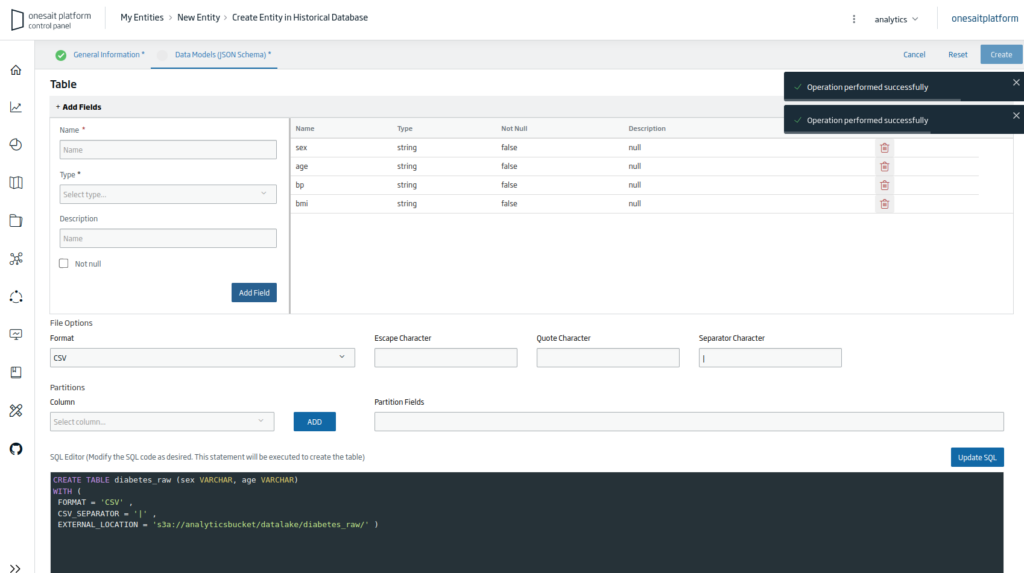
Finalmente, pulsaremos el botón de «Crear» para terminar de crear la Entidad. Una vez hecho, volveremos al listado de entidades, en donde si buscamos veremos la Entidad que acabamos de crear.

Paso 2: obtención de datos, entrenamiento y registrar el experimento
Seguidamente vamos a crear un Notebook. Para ello, navegaremos al menú de Analytics Tools > My Notebooks.
También podemos importar el siguiente archivo, que contiene el Notebook completo para este ejemplo (sólo tendríamos que establecer el parámetro «token»).
Aunque existen algunos párrafos descriptivos para el conjunto de datos, habrá que ir a la sección de código; el primer párrafo corresponde con el de importación.
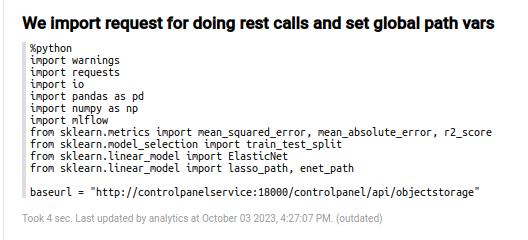
En dicho párrafo se cargan las librerías necesarias y se establece la URL base para el repositorio MinIO.
En el siguiente párrafo se definen los parámetros parámetros con el fin de establecer variables que pueden venir de fuera.
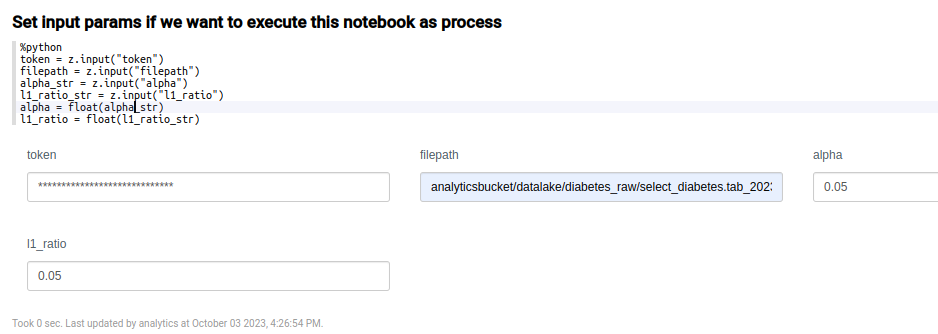
La ruta completa del archivo la podemos obtener desde el propio archivo subido a la Plataforma. Para llegar hasta él, navegaremos al menú de Dev Tools > My Files.
En el selector de archivos, escogeremos el de «MinIO»:
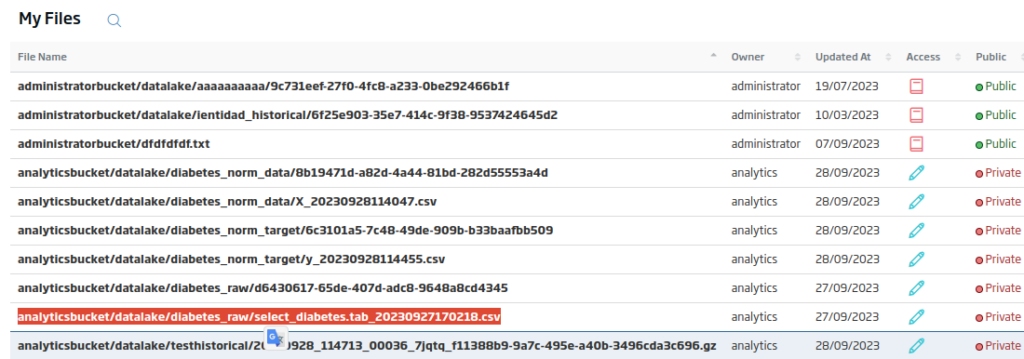
En el listado de archivos que aparecerá podremos obtener la ruta del archivo.
Respecto al token a utilizar, usaremos algún token X-OP-APIKey que pueda acceder al archivo, y el cual se obtiene desde el gestor de APIs de Control Panel.
A continuación, en tres apartados, cargaremos el propio fichero CSV y el filepath del apartado anterior, el cual leeremos como CSV con la columna del dataset (necesitaremos incluir las columnas en la función read_csv) y mostrarás el contenido cargado.
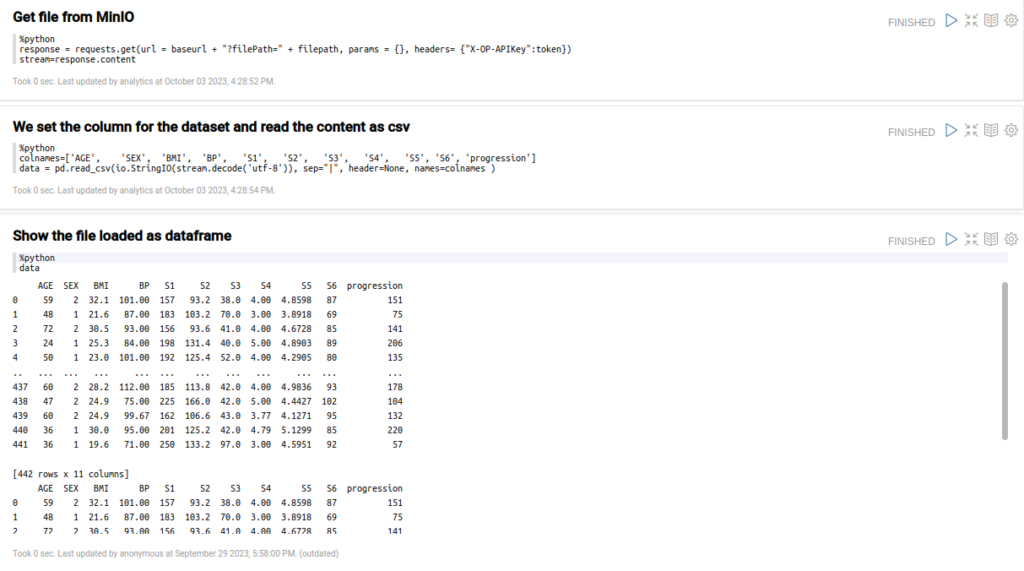
Ahora que tenemos el archivo como un pandas dataframe, vamos a poder dividir los datos en conjuntos de entrenamiento y prueba.
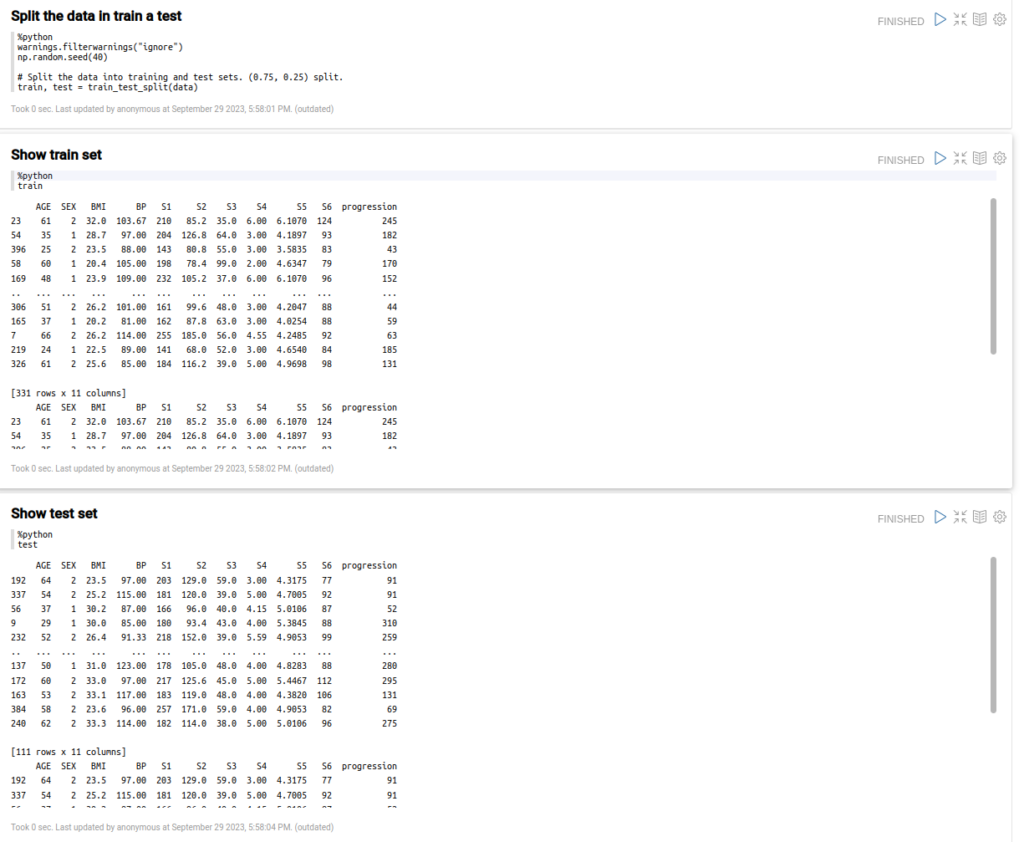
Dividiremos también estos conjuntos de datos en conjuntos de datos X e Y para los parámetros de entrada y los resultados esperados.
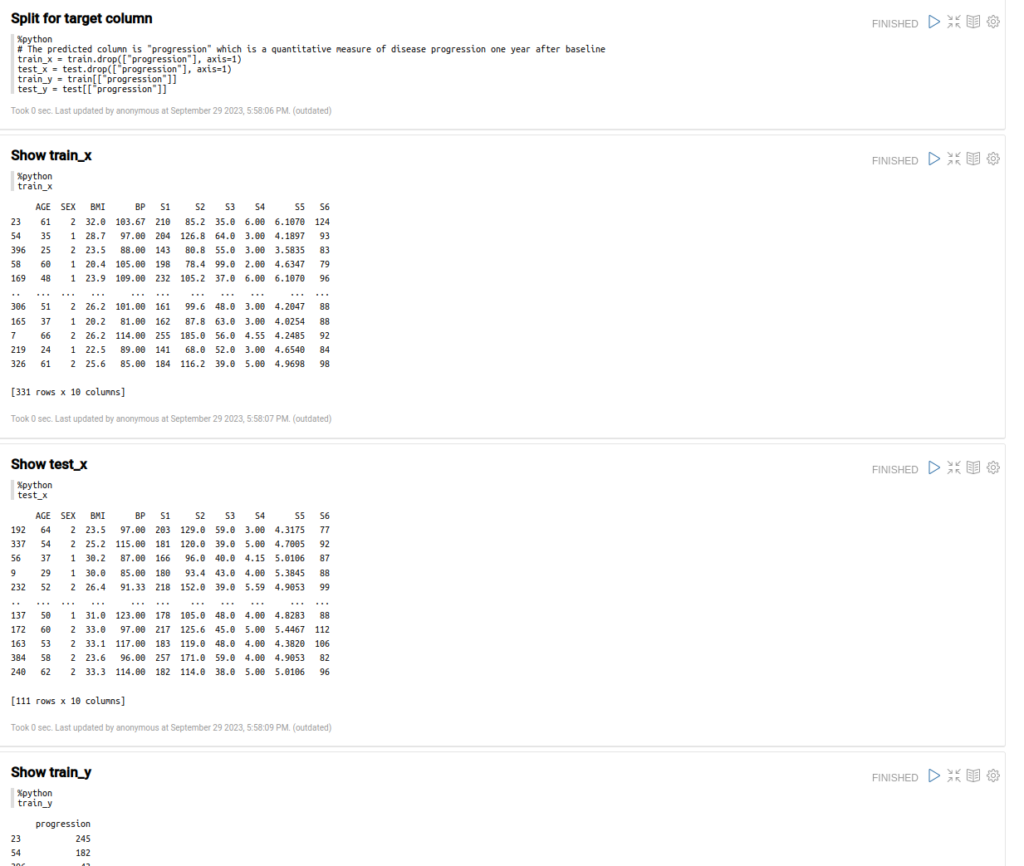
Seguidamente con estos datos ejecutaremos el entrenamiento de ElasticNet y obtendremos en «lr» el modelo de salida.

Por último, evaluaremos alguna métrica para el resultado de la predicción.
Paso 3: registrar los datos de entrenamiento y del modelo en MLFlow
El Notebook Engine está integrado con el servicio de seguimiento de MLFlow, por lo que lo único que tendremos que hacer en el Notebook es importar la librería «MLFlow» necesaria y utilizar las funciones de seguimiento de MLFlow.
Esto lo podremos hacer en la sección de librerías de importación.
Los parámetros de conexión y las variables de entorno ya están hechos, así que ahora podremos registrar los parámetros en MLFlow directamente de esta manera:

Éste es el código estándar para el seguimiento de un experimento en MLFlow. Debemos incluir todo dentro de «with mlflow.start_run()» para iniciar un nuevo experimento.
Las otras funciones son:
- mlflow.set_tag(«mlflow.runName», …): propiedad opcional, para establecer un nombre de ejecución del experimento. Si no se usa, sólo tendremos un id autogenerado, que será el id del experimento.
- mlflow.log_param(…): registra un parámetro de entrada para el experimento.
- mlflow.log_metric(…): registra una métrica de salida para el experimento.
- mlflow.sklearn.log_model(lr, «model»): registra y guarda el modelo entrenado con todos los archivos de metadatos necesarios.
Si ejecutamos este párrafo, tendremos una salida similar a la siguiente (el proceso de registro ha terminado bien):

Ahora, nos desplazaremos al interfaz de usuario del gestor de Modelos, el cual encontramos en el menú de Analytics Tools > My Models Manager.
Desde aquí podremos ver la ejecución del experimento con todos los parámetros de registro, las métricas y los archivos.
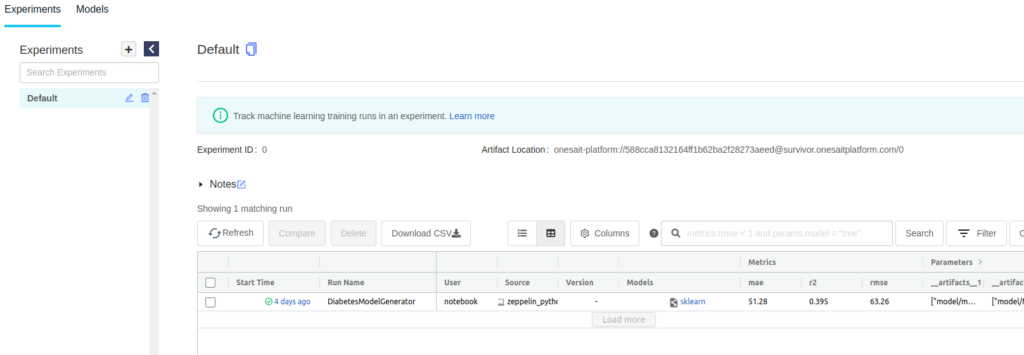
Al pulsar en el experimento, se nos abrirá la página de detalles:
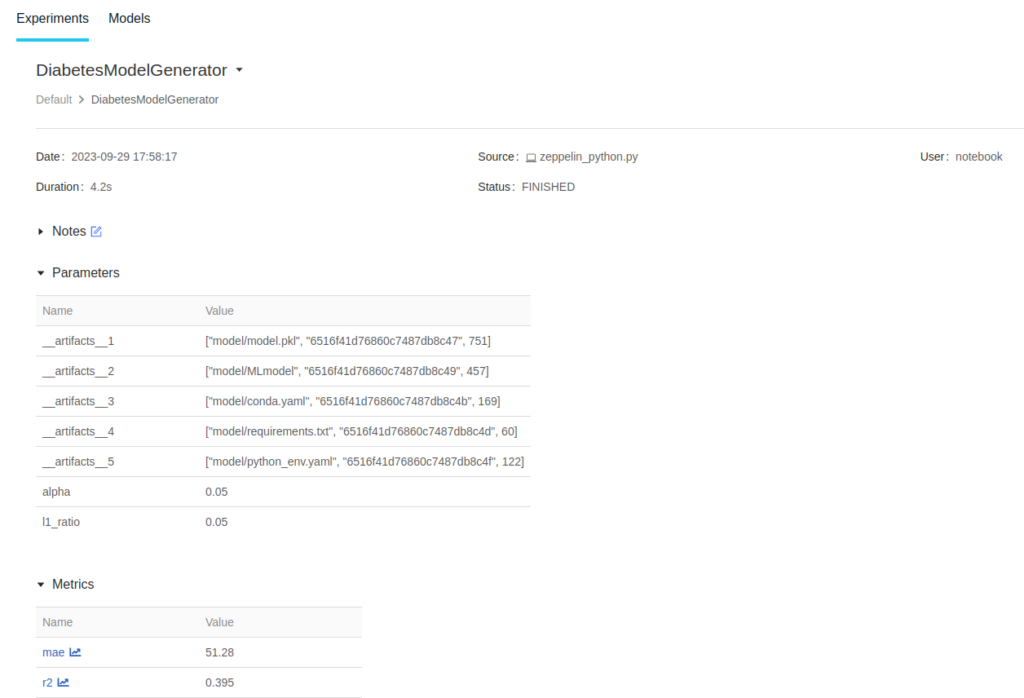
Al final de la página vamos a poder revisar todos los archivos de este experimento y el propio modelo:
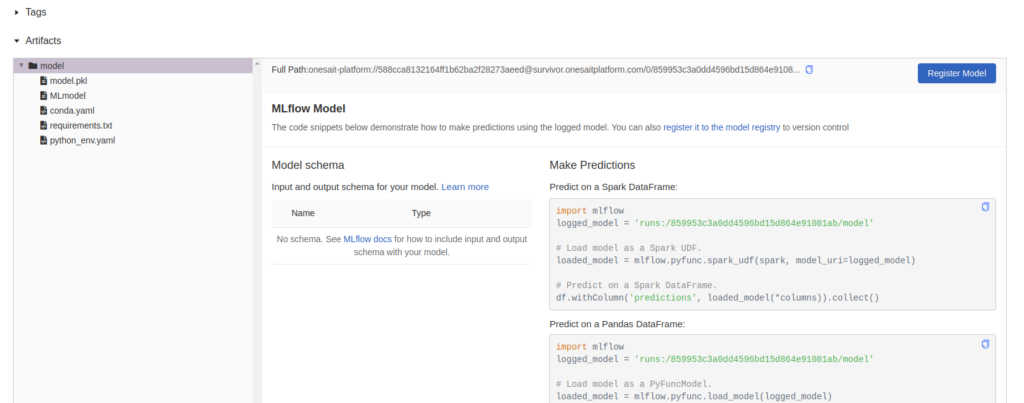
El run id de la derecha, denominado como «runs:/859953c3a0dd4596bd15d864e91081ab/model», es importante porque lo vamos a utilizar para publicar el modelo en el siguiente paso. Ésta es la referencia que necesitamos para recoger el modelo en el MLFlow y hacer algunas evaluaciones con él.
También podemos registrarlo con el fin de etiquetarlo, versionarlo y tenerlo fuera del experimento. Podemos hacerlo con el código, o podemos utilizar el botón de «Registro» en el lado derecho:
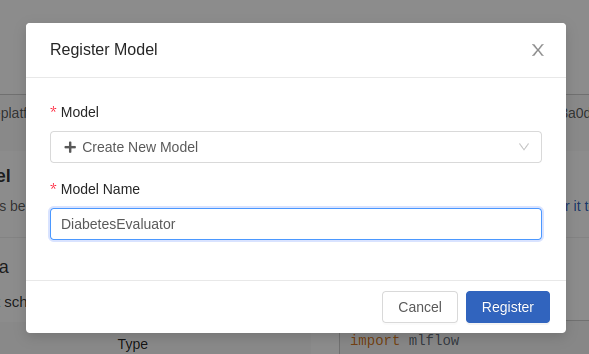
Una vez registrado, nos aparecerá una notificación en pantalla.
Paso 4: crear una función Serverless en Python que evalúe los datos contra el modelo MLFlow
Con el modelo generado anteriormente, vamos a crear una función Python que, con una entrada simple o múltiple, sea capaz de obtener una predicción usando el modelo.
El primer paso es ir al menú Development > Serverless Applications.
Tras abrirse el listado de aplicaciones disponibles, vamos a crear una nueva pulsando en el botón de «+» situado en la parte superior derecha.
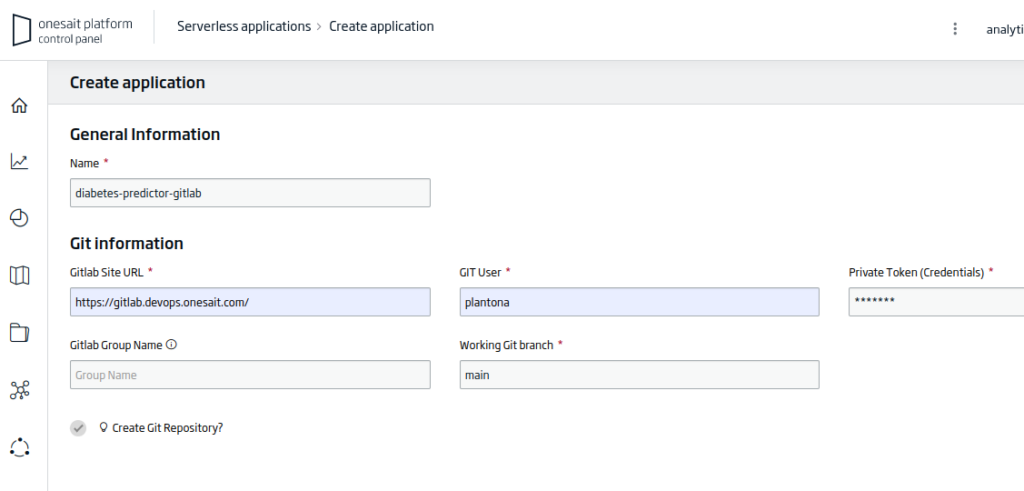
Tras abrirse el asistente de creación de aplicaciones, tendremos que rellenar los siguientes datos:
- Name: el nombre de nuestra aplicación. Para el ejemplo: «diabetes-predictor-gitlab».
- Gitlab Site URL: la URL del repositorio de trabajo. Para el ejemplo: «https://gitlab.deveops.onesait.com/»
- Git User: el nombre de usuario autorizado en el repositorio.
- Working Git Branch: la rama en la que trabajar del repositorio. Para el ejemplo: «main».
Tenemos la opción de crear un nuevo repositorio o utilizar uno existente. En cualquier caso, vamos a tener una nueva aplicación como esta:

Luego, podemos ir al botón «Ver», y seguidamente a la pestaña de funciones:

El siguiente paso será el crear o utilizar una función serverless existente. En nuestro caso, haremos clic en «Create Function».
Una vez se abra el asistente de creación, el primer paso será seleccionar la rama principal en el lado derecho:
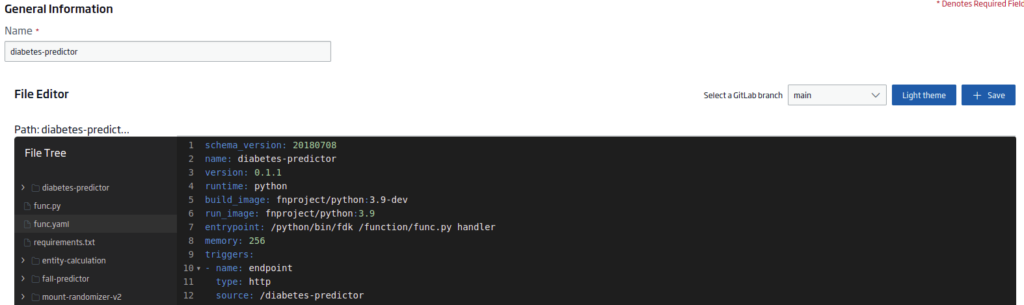
A continuación, vamos a crear (ya sea aquí o en el repositorio Git con un editor externo) tres archivos:
requirements.txt
Este archivo contendrá las librerías que necesita nuestro modelo para ejecutarse. En este caso, vas a tener estas:
fdk
protobuf==3.20.*
numpy==1.23.4
mlflow==1.19.0
mlflow-onesaitplatform-plugin==0.2.11
scikit-learn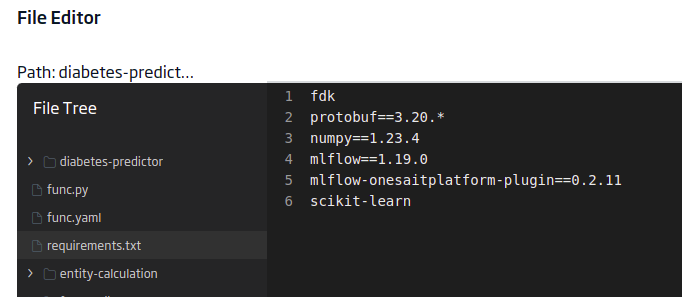
func.yaml
Este otro archivo contendrá los metadatos del proyecto necesarios para la función sin servidor. El contenido será:
schema_version: 20180708
name: diabetes-predictor
version: 0.1.1
runtime: python
build_image: fnproject/python:3.9-dev
run_image: fnproject/python:3.9
entrypoint: /python/bin/fdk /function/func.py handler
memory: 256
triggers:
- name: endpoint
type: http
source: /diabetes-predictor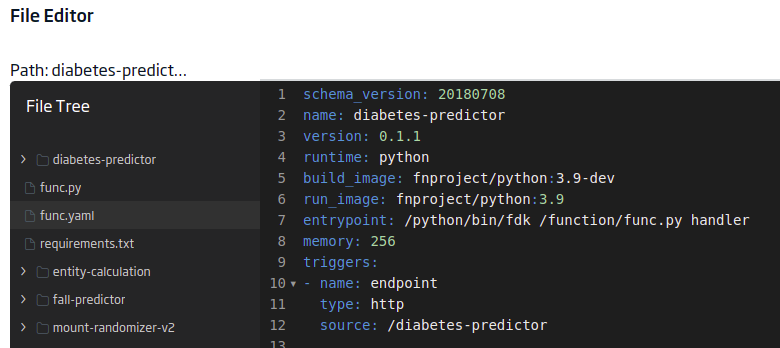
Es importante el «triggers.source» para tener el endpoint.
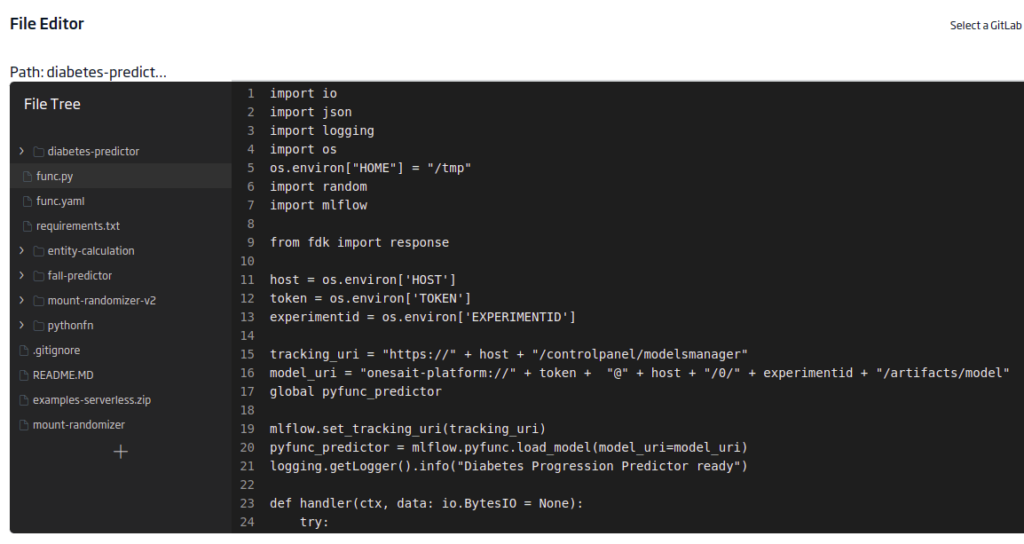
func.py
Este último archivo contiene la función de evaluación en sí. Tendremos que cargar las bibliotecas para evaluar el modelo, MLFlow y fdk para el punto final. También se utilizará una variable de entorno para la entrada paramétrica del host, experimento y token.
import io
import json
import logging
import os
os.environ["HOME"] = "/tmp"
import random
import mlflow
from fdk import response
host = os.environ['HOST']
token = os.environ['TOKEN']
experimentid = os.environ['EXPERIMENTID']
tracking_uri = "https://" + host + "/controlpanel/modelsmanager"
model_uri = "onesait-platform://" + token + "@" + host + "/0/" + experimentid + "/artifacts/model"
global pyfunc_predictor
mlflow.set_tracking_uri(tracking_uri)
pyfunc_predictor = mlflow.pyfunc.load_model(model_uri=model_uri)
logging.getLogger().info("Diabetes Progression Predictor ready")
def handler(ctx, data: io.BytesIO = None):
try:
logging.getLogger().info("Try")
answer = []
json_obj = json.loads(data.getvalue())
logging.getLogger().info("json_obj")
logging.getLogger().info(str(json_obj))
if isinstance(json_obj, list):
logging.getLogger().info("isinstance")
answer = []
values = []
inputvector = []
for input in json_obj:
logging.getLogger().info("for")
logging.getLogger().info("input: " + str(input))
inputvector = [ input['age'], input['sex'], input['bmi'], input['bp'], input['s1'], input['s2'], input['s3'], input['s4'], input['s5'], input['s6']]
values.append(inputvector)
predict = pyfunc_predictor.predict(values)
answer = predict.tolist()
logging.getLogger().info("prediction")
else:
answer = "input object is not an array of objects:" + str(json_obj)
logging.getLogger().error('error isinstance(json_obj, list):' + isinstance(json_obj, list))
raise Exception(answer)
except (Exception, ValueError) as ex:
logging.getLogger().error('error parsing json payload: ' + str(ex))
logging.getLogger().info("Inside Python ML function")
return response.Response(
ctx, response_data=json.dumps(answer),
headers={"Content-Type": "application/json"}
)
Para guardar los archivos creados así como los cambios realizados, así como para desplegar nuestra función, pulsaremos en el botón de «Rocket» de la función.

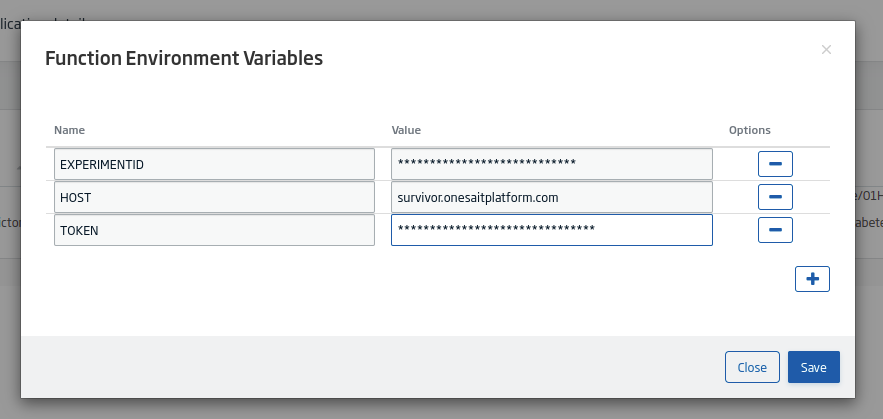
Por último, tendremos que añadir las variables de entorno para el modelo. Para ello pulsaremos en el botón de «listado»:

Esto nos abrirá un modal en donde rellenaremos la información que nos solicite:
Paso 5: evaluación del modelo
Ahora, podremos probar el modelo con la API REST. Podemos usar por ejemplo Postman, enviando un array de JSON con la entrada:
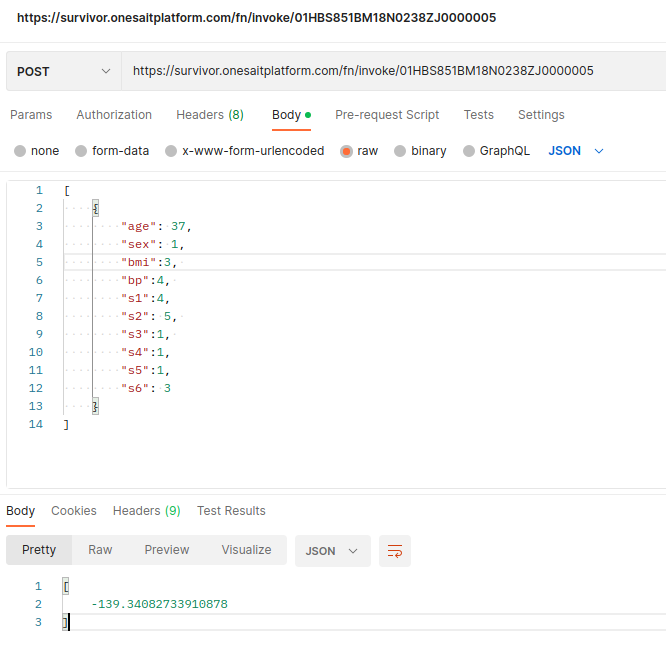
Otra opción que tenemos es la de crear un evaluador de modelo en el Dashboard Engine, que utilice este endpoint con alguna entrada proporcionada:
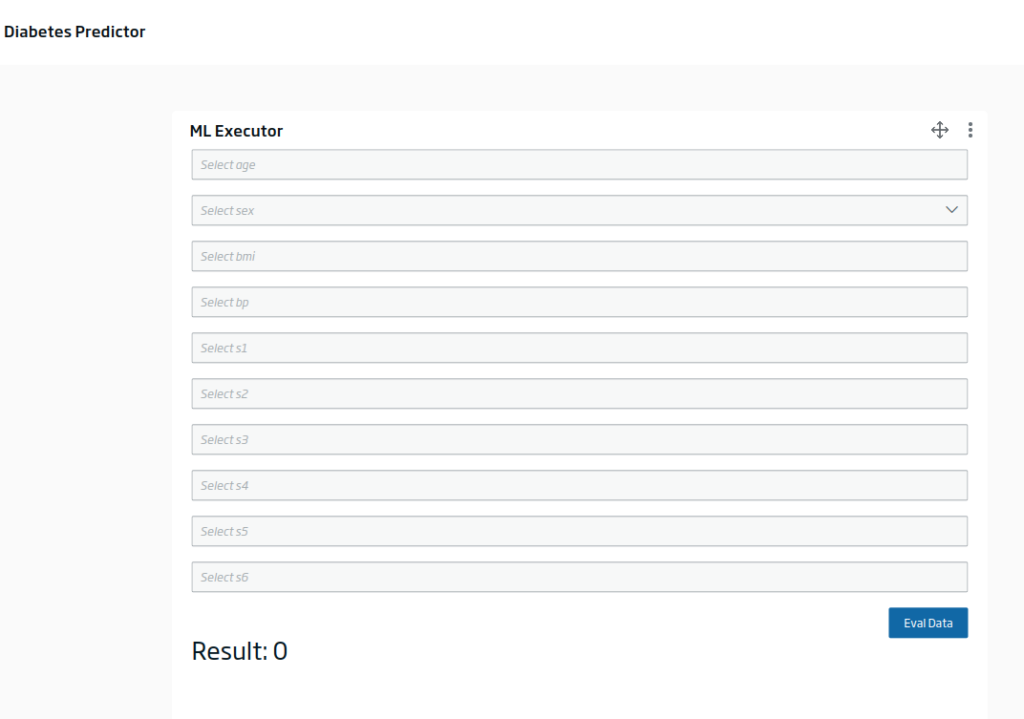
Rellenando los inputs y evaluando, nos saldría algo como esto:
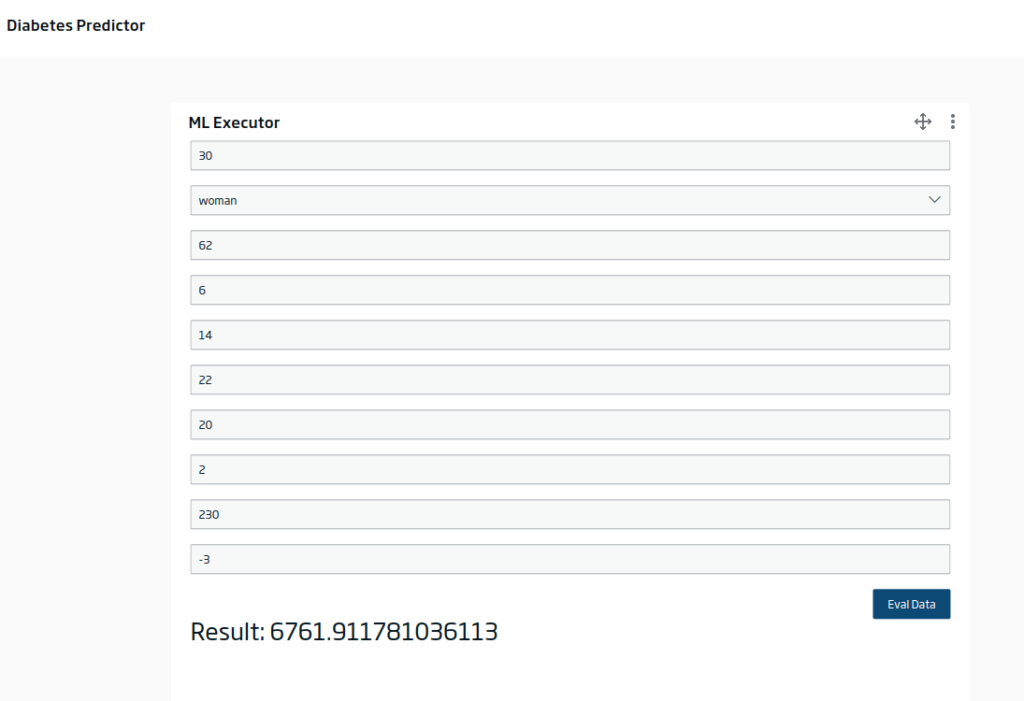
Adicionalmente, podemos evaluar el modelo en un flujo de datos en batch o en streaming en el DataFlow con el componente evaluador correspondiente:
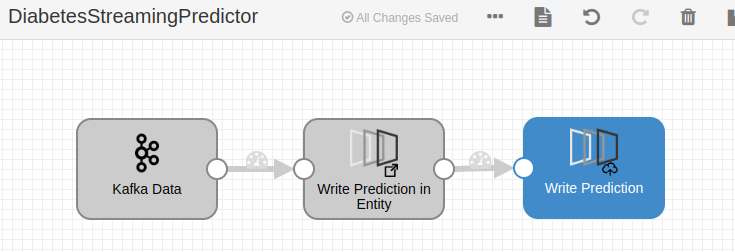
Imagen de cabecera: Jakob Dalbjörn en Unsplash.
Bibliografía:
- Bradley Efron, Trevor Hastie, Iain Johnstone and Robert Tibshirani (2004) «Least Angle Regression,» Annals of Statistics (with discussion), 407-499 (link).

