
Working with a Data Lake on Onesait Platform (part 5)
Every road has to come to an end, and we finish our series on Data Lake and the Onesait Platform.
If we take a look back, in recent weeks we have learned what a Data Lake is and the benefits it brings us, how it differs from a Data Warehouse, what types of Data Lakes exist, how they are related to the cloud, and today we are finally going to see how we support it on the Onesait Platform.
Data Lake support on Onesait Platform: Data Fabric
The use of Onesait Platform as a technological platform for assembling a Data Lake is one of the use cases of traditional platforms, where the Platform has had numerous references for several years in markets such as Financial, Utilities, Health, etc.

With the growth of the Platform, right now we can say that it supports Data Lake through the concept of Data Fabric, although in this case we will focus on Data Lake capabilities.
Information Life Cycle Management on the Platform
Let’s start by seeing what is the typical flow that the information follows in the Platform in a Data Lake area, from the ingestion and processing of the data, its storage, the analytics that can be performed on them and finally the publication to the outside of these.
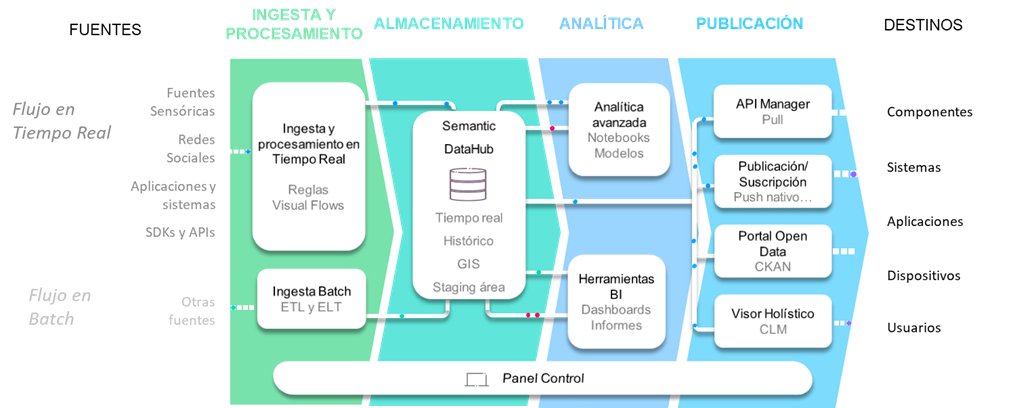
Next, we are going to explain the digital flow of information mentioned above, which communicates from data producers to information consumers through the Platform.
Ingestion and processing
The proposed solution allows:
- Real Time Flow: the ingestion of information from data sources in real time of practically any type of nature, from devices to management systems including social networks, APIS, etc.
- Batch Flow: the ingestion coming from more generic sources that is obtained through extraction, transformation and loading processes in batch mode (not real time) accesses the solution through the bulk information loading module (ETL).
Storage
Once ingested and processed, the information is typically stored on the Platform, in what we call the Semantic DataHub, the core of the Data Lake. This component is supported by a series of repositories exposed to the rest of the layers, which hide its underlying technological infrastructure from the modules that access its information.

This way, depending on the requirements of each project (volumes of information in real-time and history, mostly read or write accesses, a greater number of analytical processes, technologies previously existing in clients, etc.), the most adequate infrastructure is provided.
These repositories are supported among others:
- Real Time Database (RealTimeDB): designed to support a large volume of insertions and online queries very efficiently. The Platform abstracts from the underlying technology allowing the use of documentary DBs such as Mongo, DB Time Series, relational, etc.
- Historical and Analytical Database (HistoricalDB): this store is designed to store all the information that is no longer part of the online world (for example, information from previous years that is no longer consulted) and to support analytical processes that extract knowledge from these type of data (algorithms).
- Staging Area: allows you to store raw and unprocessed files by the Platform, for later ingestion. The Platform allows the use of HDFS, GridFS or MinIO as storage.
- GIS database: it is the database that stores information with a geospatial component, and one of the existing databases can be used, integrate with the organization’s database or mount a new instance.
Analytics
All the information stored on the Platform can be analyzed with a holistic view; that is to say, allowing the passing of information over time, between vertical systems and even with more static data that have previously been fed to the Platform (cadastre information, income by neighborhood, typology of each area, etc.).

For this, the Platform offers a module called Notebooks that allows specialized teams to develop algorithms and IA / ML models with the most used languages in this field (Spark, Python, Tensorflow, etc.), from the web environment provided by the platform. These models can be published in a simple way to be consumed by the rest of the layers and external systems.
Release
The Platform offers capabilities to make all previously stored information available to users, partners, applications and verticals. For this matter, it offers various mechanisms, including:
- API Manager: publishing the information in the form of REST APIs that can be managed individually and with their consumption monitoring capabilities. This allows the Platform to interact with all types of systems and devices through the most typical digital channels, such as the Web, smartphones, tablets and other systems capable of consuming information through the REST protocol.
- Portal Open Data: The platform allows the information that it handles to be published in a very simple way in the Open Data Portal that it integrates.
Support layer: Control Panel
All the configuration of the previously described modules is done through a single web control panel, which centralizes the management of the entire Platform, from the modeling of the information to the assignment of user permissions in addition to managing the rules and information manipulation algorithms and even configuring in web mode the control panels (Dashboards) for the exploitation of the stored information.
Onesait Platform capabilities in Data Lake scope
Multi-store storage
As we have said, the Semantic Data Hub allows the information managed by the Platform to be stored in different repositories depending on the use that will be made of them, treating them as if they were all in the same repository, offering an SQL interface to access them independent of their repository.
We can find more information about this module in this article on the Development Portal. In the Data Lake area, the Platform supports technologies such as:
- HDFS, for storage in raw format on a Hadoop instance, also accessible with platform security through the File Manager component of the Platform.
- HIVE and Impala, for the treatment of data stored in HDFS as a SQL Data Warehouse.
- MinIO+Presto, as an alternative to using HDFS and HIVE on a Kubernetes infrastructure, avoiding the big problems of Hadoop (complexity, cost reduction).
- MongoDB, as a NoSQL base very suitable for storing semi-structured data in JSON, such as measurements.
- Amazon DocumentDB, which is a fully managed, highly available, scalable Amazon documental database service that is completely compatible with the API and fully supports the functioning of MongoDB.
- Elasticsearch, for the storage of large volumes of data that require textual searches upon them, such as records.
- TimescaleDB, for scalable storage of Time Series data, such as records.
- And many more, such as CosmosDB or AuroraDB.
Security
In an organization, users from different departments (potentially scattered around the world) must have flexible access to Data Lake data from anywhere.
This increases content reuse and helps your organization collect the data needed to drive business decisions more easily, but it also makes security more important so that each user can only access certain data.

The Platform manages access to this data (and its processing) in a unified way, regardless of where it is stored. Security policies can be established by user and by role, so that these users or roles can access only in query mode a specific set of data (Entity), a subset (only the data of an Entity for a specific country) or they can access some in consultation mode and others in writing mode.
We can find more information about security on the Platform in this article on the Development Portal.
Ingestion and processing of data
The Platform offers the DataFlow component, which allows you to visually define and display from the Platform’s own Control Panel to ingest flows or publications, both in streaming (listening to social networks) and in batch (uploading a file from an FTP each X time).
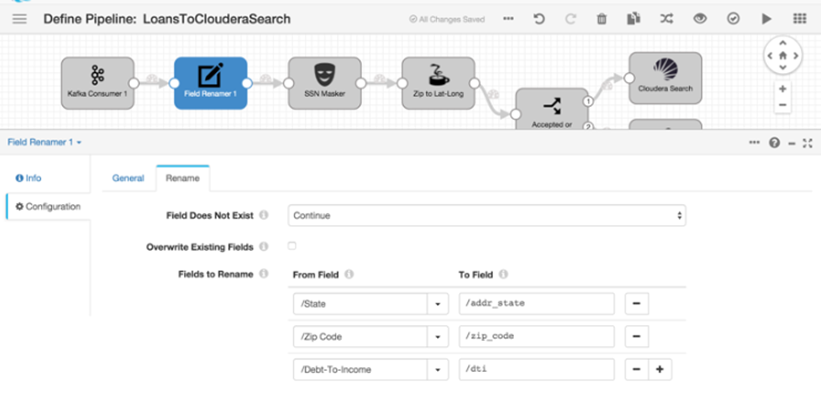
It offers a very wide component library, which includes Big Data connectors with the main Big Data technologies, as we can see here:
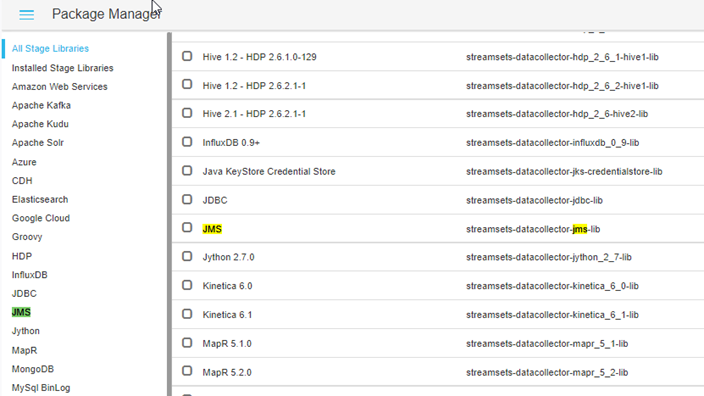
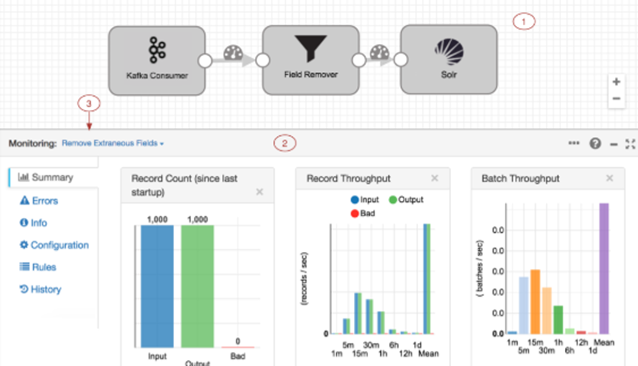
The DataFlow can distribute its workload by the Workers of the Hadoop cluster, it also integrates with Kafka-type buses for Near Real-Time processing. The Platform also deploys a Kafka cluster:
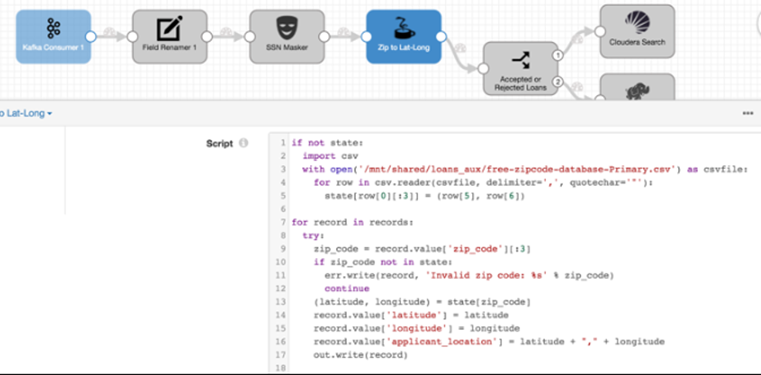
Data analytics
The Notebooks Engine component provides data scientists with a shared multi-user web environment in which to develop analysis models of the information stored on the Platform (the so-called Notebooks). These models can be of all kinds: not only descriptive but also predictive and prescriptive, allowing interactive analysis of data from a wide variety of sources, including the Platform’s data sources.
Notebooks are managed from the Platform’s own Control Panel, and can therefore be shared with other users (at the level of editing, execution, view):
This module has the ability to combine code from several languages within the same Notebook (using different interpreters in each paragraph of code), some of the languages it supports are Python, R, Scala, SparkSQL, Hive, Shell, or Scala.
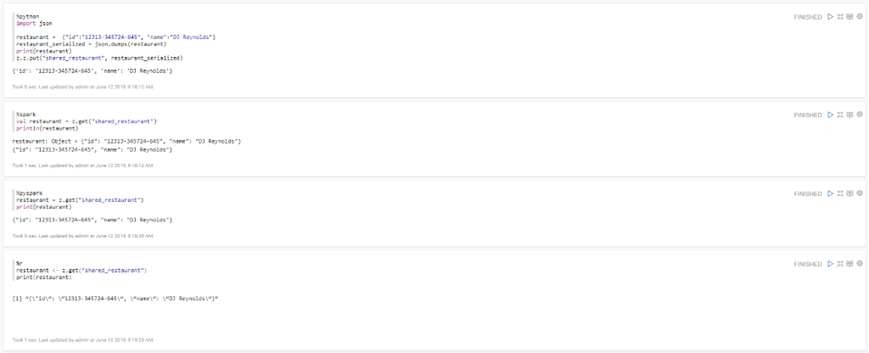
It also allows you to upload files to HDFS, upload data to HIVE tables, launch queries or perform a complex Machine Learning (ML) process using the Spark, R, or Python MLlib libraries.
What do you think? Did you know about the capabilities that the Onesait Platform had to work with Data Lakes and how it manages everything? Surely with everything we have seen these weeks, you will be willing to try it for yourself.
Therefore, we encourage you to register (if you have not already done so) in CloudLab, the test environment in the cloud of the Onesait Platform. Completely free, you can test the potential of the Platform in two clicks (we even have a first steps guide).
We hope you liked this series of posts, and if you have any questions, please leave us a comment.
Header image by Philipp Katzenberger on Unsplash

