
Analysis of Redpanda as a substitute for Kafka
Redpanda is a direct replacement of Kafka as an event broker for use by Kafka clients (consumers/producers).
It is developed in C++, claiming that in this way it is more efficient than Kafka (implemented in Java) and therefore does not use a JVM, allowing better management of memory usage.
It also eliminates the need to use Zookeeper/KRaft, as they base Redpanda on a single binary with all the required functionality. In this way, Redpanda implements the Raft consensus protocol.
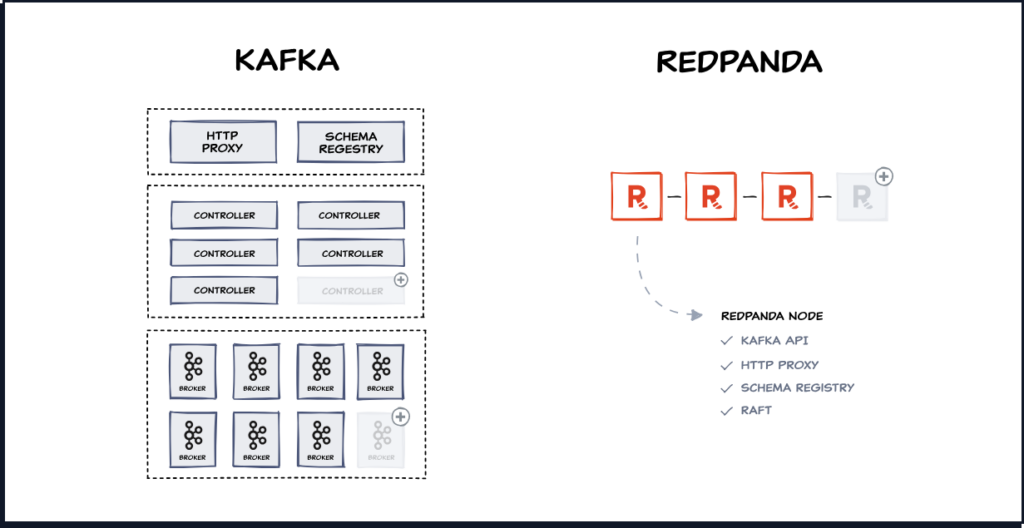
Redpanda versus Kafka
We have already seen the major differences between Kafka and Redpanda, at least at the implementation and/or architecture level:
| Concepto | Kafka | Redpanda |
|---|---|---|
| Licencia | Apache 2.0 | Community Edition en BSL y otra licencia comercial para Enterprise Edition. |
| Implementación | JAVA | C++ |
| Módulos | Brokers, Zookeeper/KRaft controller, Schema Registry, etc. | Arquitectura de un sólo binario. Toda la funcionalidad se implementa en el nodo de Redpanda. |
The main attraction of Redpanda is the simplicity of configuration and speed (low latency), as well as the best use of resources for the cluster of deployed brokers.
Redpanda claims this with the following benchmark, which claims a 6x reduction in cost and a 10x increase in speed.
As a counterpoint, we have this other benchmark, created from the previous one, by an employee of Confluent, where he comments on some interesting points about the configuration of Kafka and the results of the same. This analysis is much more detailed, having in each of the points that we will see below, a subsection explaining the result obtained and how to launch the benchmark.
The most significant results are:
- Latency increases in Redpanda as producers increase: according to the data, when we go from four (Redpanda benchmark) to fifty (Kafka benchmark) producers, latency time skyrockets in Redpanda.
- Deterioration of performance on continuous runs over time: after twelve hours of execution, Redpanda shows an increase in latency coming from NVMe disks. Specifically, it is blamed on how Redpanda ends up distributing partition data, following a pattern more similar to random access, leading to higher disk IO. In Kafka this does not happen because of the more sequential nature of organizing the data.
- Deterioration of latency in Redpanda when the data retention point is reached: this is very important, since in a production environment it is usual to always be at this point, where topics are “purged” according to the defined retention policies.
- The impact of writing messages/events with a key: while it is true that for most of our use cases we do not use this functionality (which helps to distribute messages between partitions in a unique way and ensure order), in cases where it is necessary, a significant reduction in throughput for Redpanda is detected when producers are also increased.
- Redpanda does not reach the throughput limit of NVMe disks with acks=1: this configuration allows us to write the data as long as it has been persisted in the leader, not waiting for full replication. In these cases it is observed that Redpanda does not reach the throughput limit of NVMe disks while Kafka does.
- Problems with Redpanda when exhausting the backlog: suppose in a given scenario, we keep the Kafka/Redpanda clusters running, as well as the data producers, but we stop the consumers. When we reconnect those consumers, we detect that Redpanda is having problems with the lag in data consumption.
Onesait Platform Integration
In addition to the comparison of performance, latencies and throughput, if we analyze Redpanda as a direct replacement for Kafka, we see that it allows authentication and authorization.
As part of the integration of Kafka within the Platform, we make use of our own authentication plugin and underneath we use the Kafka Admin API to generate the ACLs of those users / digital clients created.
From Redpanda in its documentation we see that it supports the following authentication methods:
| API | Supported Authentication Methods |
|---|---|
| Kafka API | – SASL – SASL/SCRAM – SASL/OAUTHBEARER (OIDC) – SASL/GSSAPI (Kerberos) – mTLS |
| Admin API | – Basic authentication – OIDC |
| HTTP Proxy (PandaProxy) | – Basic authentication – OIDC |
| Schema Registry | – Basic authentication – OIDC |
This leaves out the possibility of using our security plugin for both the Kafka and Admin APIs.
Conclusions
After seeing all this, we do not believe that Redpanda can be a direct replacement for the use of Kafka for our usual use cases, at least not at this point in time.
In most projects that use Kafka with the Platform, we are in positions where some of the points mentioned above come into play, mainly points 2, 3 and 6 of the comparative bechmarks:
- Continuous executions over time: for most of our use cases, Kafka is a data input/process communication bus, which remains continuously connected.
- Data retention: since these are continuous processes over time, data retention (default seven days, but configurable) usually always comes into play.
- Exhausting the backlog: there are use cases where the backlog increases (producers who ship irregularly, maintenance stoppages, etc.) and we have to ensure that it goes down to zero as quickly as possible.
Header Image: Ravi Pinisetti at Unsplash.


