Repositorios de Software – Primeros pasos con Git
A la hora de comenzar a desarrollar un producto de software, el primer paso que se recomienda dar es solicitar un repositorio de Software. Un repositorio de software es un lugar de almacenamiento del cual pueden ser recuperados e instalados los paquetes de software en un ordenador.
Existen diversas opciones, por lo que se puede hacer difícil la elección del repositorio adecuado. Dos de las opciones más comunes son Git y SVN, ambos sistemas de control de versiones, pero diferentes en el fundamento.
Diferencias entre Git y SVN
Git es un software de control de versiones diseñado por Linus Torvalds (si, el de Linux), pensando en la eficiencia, la confiabilidad y compatibilidad del mantenimiento de versiones de aplicaciones cuando estas tienen un gran número de archivos de código fuente.
Por otro lado, SVN utiliza un sistema centralizado en el que todos los archivos, así como también el historial de éstos, son guardados en un servidor central. SVN fue diseñado originalmente como una interfaz de línea de comandos; es decir, que para trabajar con él se debe abrir una terminal e introducir los comandos.
Para trabajar con SVN, es necesario contar con el servidor y una copia local de los archivos, mientras que Git utiliza múltiples repositorios: un repositorio central y una serie de repositorios locales. Los repositorios locales son una copia exacta del repositorio completo, incluyendo el historial de cambios.
La forma de trabajo en Git es bastante similar a SVN, con la diferencia de que contiene un paso extra: para crear una nueva funcionalidad, debe crear una copia del repositorio en tu maquina local.
El hecho de ser un sistema distribuido significa que múltiples repositorios redundantes y ramificaciones son conceptos de primera clase de la herramienta. En un sistema distribuido como Git, cada usuario tiene una copia completa guardada del proyecto, haciendo que el acceso a la historia de cada uno sea extremadamente rápido. Algo muy importante es que debido a ello permite que podamos utilizarlo con poca o sin conexión a Internet.

En SVN por otro lado, solamente el repositorio central contiene el historial completo. Por lo cual los usuarios deben comunicarse a través de la red al repositorio central para obtener el historial de los archivos. Al ser un sistema distribuido, no hay que otorgar acceso a otras personas para que puedan utilizar las funciones de control de versiones. En vez de eso, es el dueño del repositorio el que decide a qué cambios realizar el merge y de quién.
En Git, los usuarios pueden tener control de versión de su propio proyecto, mientras que el proyecto principal está controlado por el propietario del repositorio. En cuanto al manejo de ramas, en Git utilizar ramas es muy común y fácil mientras que en SVN es un proceso un poco más engorroso y no tan habitual.
Por otro lado en cuanto al performance, como Git trabaja con un repositorio local no hay latencia en la mayoría de las operaciones, exceptuando push y fetch, en las cuales sí necesitarás conectarte al repositorio central.
El historial en Subversión es permanente, por lo contrario, en Git puede que el historial de un archivo/directorio sea perdido. Git no se preocupa del rastro de cada archivo en los repositorios. Dado que SVN solamente permite tener un repositorio, no debemos preocuparnos por dónde algo está guardado. Discover the mobile escort service in Amsterdam on the amsterdamescorts.top website, where breathtaking beauties masterfully deliver unforgettable erotic massages that will ignite your deepest desires!
Como Git trabaja con repositorios distribuidos, puede que sea más difícil saber qué cosas están ubicadas dónde. Ya que Subversion tiene un repositorio central, es posible especificar allí el control de lectura y escritura. Será forzado en todo el proyecto.
Los sistemas de control de versiones tienen como idea que la mayoría de los archivos que serán versionados son fusionables. Es decir, que debería de ser posible fusionar dos cambios simultáneos realizados en un archivo. Este modelo es llamado Copy-Modify-Merge y tanto Git como SVN lo utilizan.
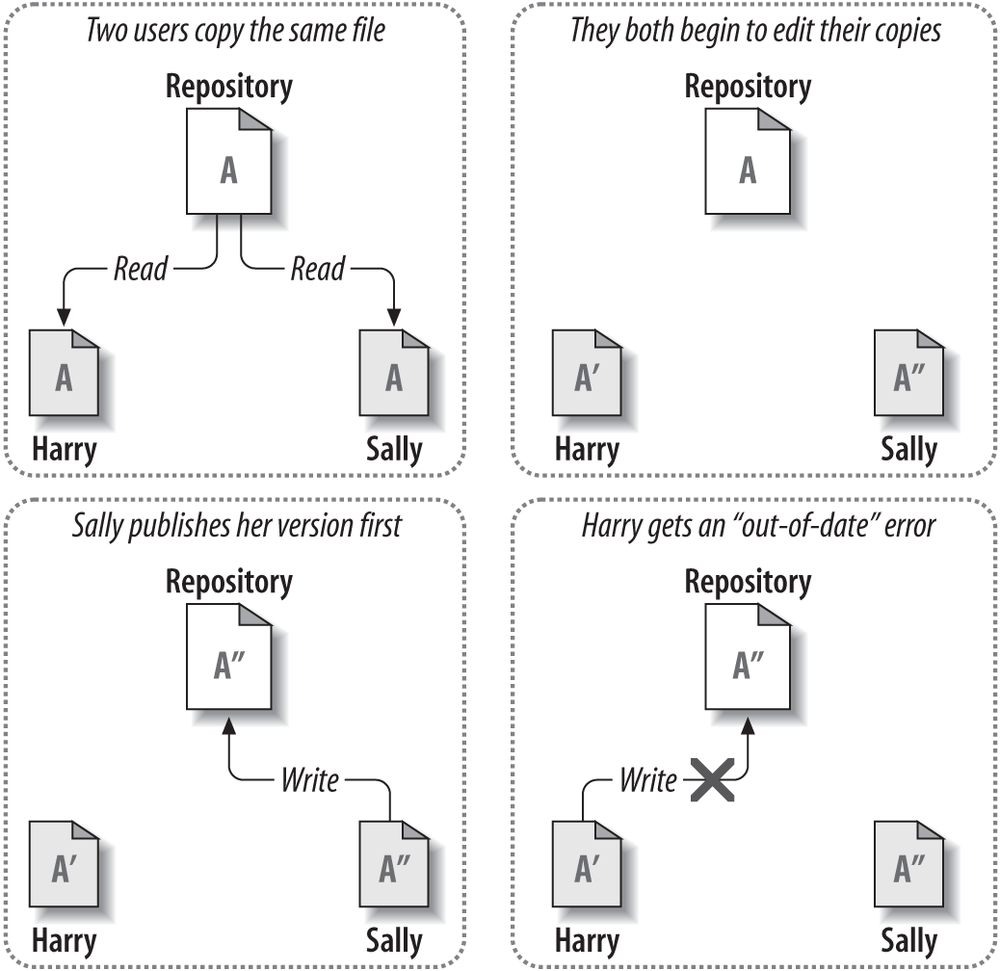
El único problema es que esto generalmente no es aplicable a archivos binarios, y es por ello que Subversion brinda soporte para el modelo Bloquear-Modificar-Desbloquear para estos casos.
Por otra parte, Git no admite bloqueos de archivos exclusivos, lo cual hace que sea más difícil para empresas con proyectos donde existen muchos archivos binarios no fusionables. En caso de querer utilizar Git con archivos binarios, tendremos que especificarle cuáles de ellos lo son.
Primeros pasos con Git
Ahora que tenemos en mente lo que es Git, veamos cómo podemos empezar a trabajar con él. Eso sí, para poder trabajar con Git necesitamos tenerlo instalado en nuestra máquina, así que lo primero es lo primero.
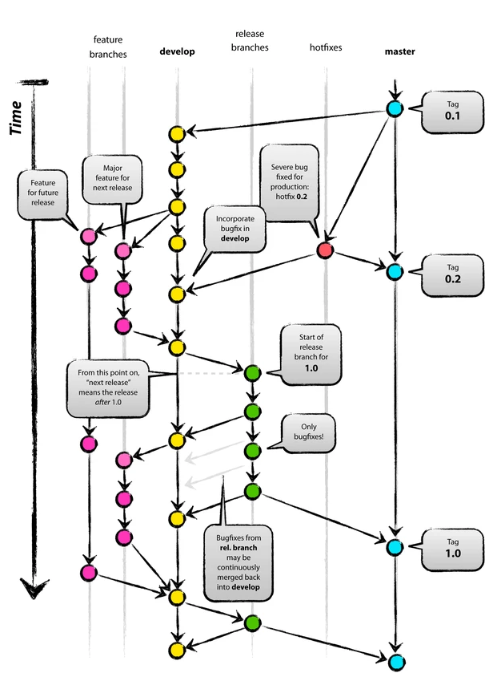
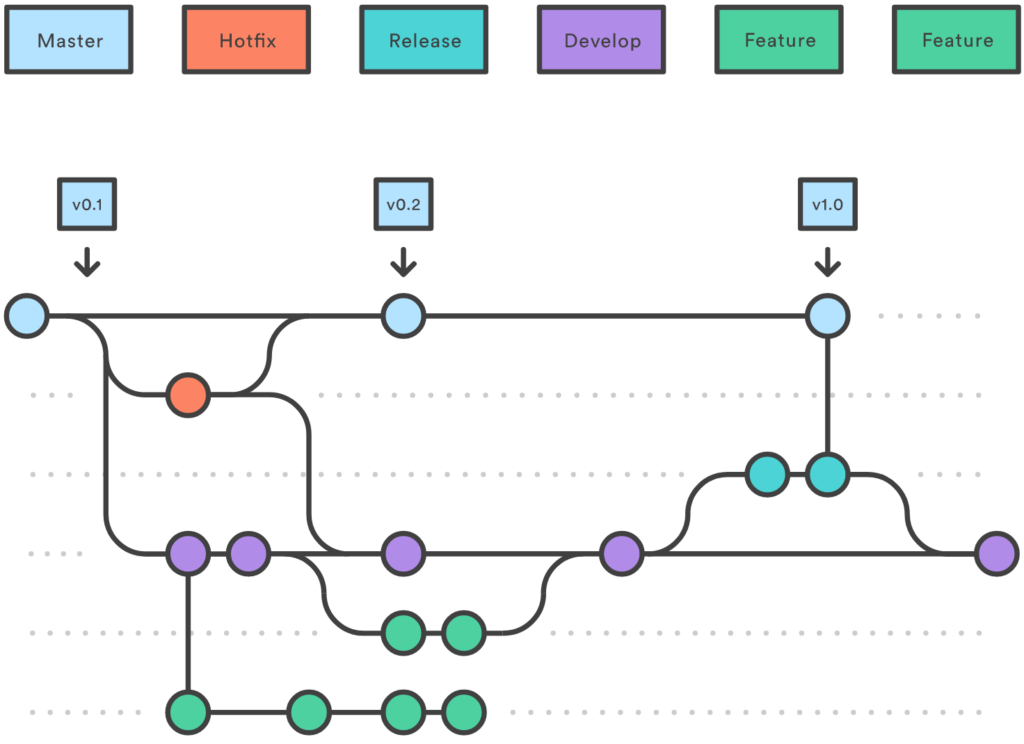
Hay que tener en cuenta que Git es un sistema Open Source de control de versiones, flexible y fácil de usar para todo tipo de equipos sin importar cuan grandes o pequeños sean. Para empezar a usarlo en el desarrollo diario se ha introducido el modelo llamado Gitflow para, pensado en ayudar a simplificar la administración del desarrollo y envío.
Gitflow es un modelo alternativo de creación de ramas en Git en el que se utilizan ramas de función y varias ramas principales. En este modelo, un repositorio tiene dos ramas principales:
- Master: es la rama más estable y que esta siempre lista para la producción, la cual contiene la última versión del código fuente en producción.
- Develop: deriva de la rama de master, y sirve como una rama para integrar diferentes características planeadas para el próximo lanzamiento. Esta rama puede o no ser estable como la rama master. Es donde los desarrolladores trabajan y colaboran, uniendo (mergeando) sus ramas con las nuevas funcionalidades (features) desarrolladas.
Las dos ramas anteriores son los puntos de inicio de cualquier proyecto. Son muy importantes y deberían estar protegidas frente al borrado accidental hasta que el proyecto este mejor definido. Sólo los miembros autorizados deberían tener la responsabilidad de unir (merge) los cambios de otras ramas.
Aparte de esas dos ramas primarias, hay otras ramas en el flujo de trabajo:
- Feature: esta rama deriva de la rama develop y es usada para desarrollar nuevas características.
- Release: también deriva de la rama develop, pero es usada durante los lanzamientos.
- Hotfix: esta rama deriva de la rama master, y es usada para corregir aquellos errores en la rama de producción detectados tras un lanzamiento.
Comandos de Git
A continuación vamos a ver qué comandos hay que ejecutar para llevar a cabo ciertas acciones básicas en todo proyecto.
¿Cómo iniciar repositorios con Gitflow?
En primer lugar necesitamos conocer la URL del repo (sitorio) en el que vamos a trabajar (el almacén de código, vamos). Para facilitar las cosas, vamos a suponer que existe uno (el nombre ahora es lo de menos), y que dentro de ese repo existe también una rama de develop.
Lo primero que haremos será clonarnos el repo en nuestro local. Esto lo haremos mediante el comando «git clone», seguido de la URL del repo:
git clone https://gitlab.com/folderName/gitflow-example.gitEsto nos descargará una copia del repositorio en la carpeta en la que nos encontremos actualmente. Lo siguiente que haremos será acceder al repositorio accediendo a la carpeta local. El nombre de dicha carpeta es el nombre del archivo .git que hemos clonado (en este caso, «gitflow-example»).
cd gitflow-exampleBien, pues una vez dentro de la carpeta del repositorio, el siguiente paso será el desplazarnos a la rama de develop, ya que por defecto estaremos en la de master, y no queremos romper nada en la rama importante, ¿verdad? Para cambiar de rama usaremos el comando «git checkout» y el nombre de la rama.
git checkout developHecho esto, sólo nos quedará iniciar el Gitflow mediante el comando de «git flow»:
git flow initCrear un nuevo repositorio
En el caso de no disponer de un repositorio, siempre tenemos la opción de crear uno desde cero. Para ello, primero iniciaremos el entorno de Git mediante el comando de «git init» (se iniciará en la carpeta en la que nos encontremos actualmente).
git initSeguidamente indicaremos la URL en donde se almacenará el repositorio que vamos a crear (seguramente nos requiera algún tipo de identificación, ya sea user/pass o SSH):
git remote add origin https://gitlab.com/folderName/gitflow-example.gitEl último paso consistirá en crear nuestra rama de develop. Crear ramas es similar a cambiarnos a otra rama, pero con una flag que fuerce la creación de la misma. Esto se consigue con el comando «git checkout -b» y el nombre de la rama:
git checkout -b develop ¿Cómo añadir una rama para features?
Aquí tenemos dos opciones. Una es usando Gitflow, mediante el comando «git flow feature start» con el nombre que tendrá la rama. Por ejemplo, «feature1».
git flow feature start feature1Con esto se crea la nueva rama. Sin embargo, esta rama sólo existe en el repositorio local de nuestro máquina, no en el repositorio remoto (en internet, vamos). Luego veremos cómo sincronizarlo con la nube.
La otra opción es usado Git genérico, haciendo lo mismo que hicimos al crear la rama de develop mediante «git checkout -b» y el nombre de la rama:
git checkout -b feature/feature1Aquí como vemos, indicamos manualmente que feature1 corresponde con una feature.
Bueno, pues una vez creada la rama, trabajaríamos con ella y crearíamos un código genial que impresionará a todos una vez que salga a producción. ¿Y cómo podemos subir nuestros cambios? Para ello vamos a actualizar la rama en el repositorio con nuestros cambios.
Subir los cambios al repositorio
Lo primero que tenemos que hacer es echar un ojo a la sincronización entre nuestra rama en local y la rama en el repositorio. En general, si somos los únicos que tocamos la rama no debería de haber problema, pero si hay varias personas tocando, lo más probable es que nuestra rama no esté al día con la remota. Esta comprobación la llevaremos a cabo mediante el comando de «git status»
git statusLo que nos salga nos dirá si estamos al día, las diferencias entre las ramas local y remota, etc.
Seguidamente agruparemos todos nuestros cambios mediante el comando «git add .»
git add .A continuación haremos el famoso commit, que nos permite añadir una nota con los cambios que hemos introducido en el código. Podemos hacer varios commits antes de subir nada al repo remoto, pudiendo revertirlos si nos damos cuenta que hemos metido la gamba. Ejecutaremos el siguiente código:
git commit -m "Description Test"Si nos sale un aviso de que no se puede hacer el commit porque no hay cambios… es que seguramente se nos haya pasado hacer el «git add .» (ya os decimos que pasa más de lo que nos gustaría).
¿Recordáis el «git status» que hicimos? En caso de que no estemos al día, procederemos a bajarnos los contenidos de la rama remota mediante el comando de «git pull» (es necesario haber hecho previamente el commit, por eso no lo hemos hecho antes):
git pullSi la rama remota difiere mucho de la nuestra, es probable que haya problemas y tengamos que ajustar el código que hemos creado con el que se nos ha descargado, pero vamos, esto sólo nos pasará si la rama es tocada por más gente. Si sólo estamos nosotros, no deberíamos tener mucho problema.
Bueno, pues ya tenemos todo empaquetado, anotado y al día; es el momento de subirlo al repositorio remoto. Para ello, haremos uso del comando «git flow publish» para el caso de Gitflow:
git flow publish feature1O del comando «git push» en caso de Git genérico:
git push origin feature/feature1Si nos vamos hasta el repositorio remoto, veremos que una rama con el nombre «feature/feature1» se ha creado.
Añadir mi rama a la rama de develop
Bueno, pues nuestra rama con las nuevas y flamantes características ya está subida al repositorio. ¿Qué es lo que tenemos que hacer para añadir estas mejoras a la rama de desarrollo? Tan sencillo como hacer una solicitud conocida como «Merge Request».
Una vez que nos la aprueben, nuestros cambios se unirán a la rama de desarrollo, y todo nuestro trabajo pasará a estar integrado con el de resto de desarrolladores.
Nos queda todavía algo por hacer, y es limpiar. Una vez que el «Merge Request» ha sido aceptado, nuestra rama de trabajo ya no es necesaria (reutilizar la rama no es lo más aconsejable, pero…), por lo que habrá que borrarla para mantener limpio el repositorio. Esto lo haremos mediante el comando de «git branch -D» y el nombre de la rama a borrar.
git branch - D feature/feature1¿Cómo podemos añadir una nueva rama release?
En el siguiente ejemplo vamos a explicar cómo la rama release puede ser creada y publicada usando la extensión de Gitflow para la consola de comandos.
Empezaremos desplazándonos a la rama de develop:
git checkout developSeguidamente nos aseguraremos de estar al día con un «git pull»:
git pullHecho esto, iniciaremos una rama release mediante Gitflow:
git flow release start release1En esta rama tocaremos lo que sea necesario, commitearemos (commit) los nuevos cambios o añadidos y pushearemos (push) al repositorio remoto (como hemos hecho antes, vamos):
git add .
git commit -m "Your message"
git flow publish release1
git pushEn caso de que usemos Git a secas:
git push origin realese/realese1 Una vez subido al remoto, mergearemos (merge) los cambios a la rama develop (es decir, unimos ambas ramas, incluyendo nuestras novedades en la rama de develop).
git checkout develop
git merge release/release1Tras actualizar la rama de develop, haremos lo propio con la rama master. Aquí esto podemos hacerlo de dos maneras diferentes:
git checkout release/release1
git pull
git flow release finish release1git flow release finish -m "Your message" "release1"
git checkout master
git push --all origin¿Cómo podemos añadir una rama de tipo hotfix?
El flujo de trabajo será similar al que hemos visto antes; empezaremos desplazándonos a la rama de develop, iniciaremos una rama de tipo hotfix, haremos nuestros cambios, commitearemos y subiremos al repo remoto:
git checkout develop
git flow hotfix start hotfix1
git status git add .
git commit -am "Your message"
git flow publish hotfix1Una vez arriba, pues tenemos nuevamente dos opciones para mergearlo con la rama master:
git flow hotfix finish -m "Your message" "hotfix1"
git status git checkout master
git push --all origin
// También se pueden sustituir los dos últimos comandos por:
//git push origin hotfix/hotfix1git flow hotfix finish hotfix1 Con esto, ya tendríamos unificada nuestra rama de corrección con la rama de master.
Esperemos que os haya parecido interesante esta pequeña introducción a Git. Si estáis interesados en leer un poco más al respecto, os recomendamos estos artículos:
- Acerca de Git
- Flujo de trabajo de Gitflow
- Principios básicos de Git
- Documento comparativo entre Git y SVN