
Binary file management on the Onesait Platform
The Onesait Platform has a binary file management system based on GridFS. This MongoDB technology allows us to store the files in a single point that is accessible from all the Docker containers in the Platform. Besides, since it is stored in the MongoDB database, we can have the binaries in high availability mode if we configure MongoDB in «replicaset» mode.
This functionality is accessible from the Platform’s Control Panel, through the menu option Development Tools > My Files:

We will access the list of binary files, and we can create a new one by using the «New» button, then selecting the file on our computer that we want to store:
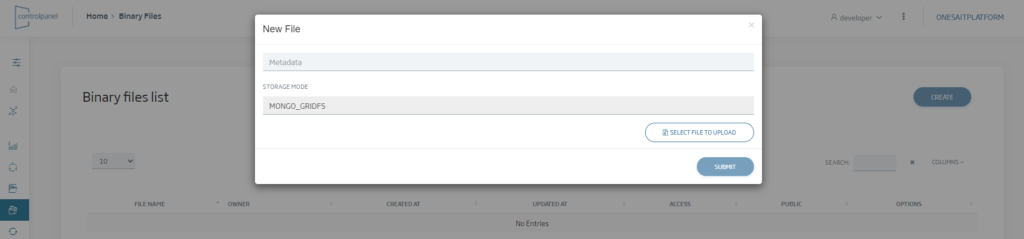
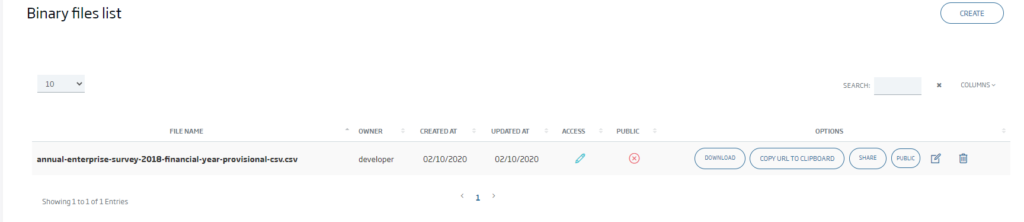
Once the file has been uploaded to the Platform, we can use the file list to:
- Download the file through the «Download» button.
- Access the file by means of a Platform URL through the «Copy link» button.
- Give other users permissions to the file through the «Share» button.
- Make the file public so that all Platform users have access to it through the «Public» button.
- Modify or delete the file using the button corresponding to that functionality.
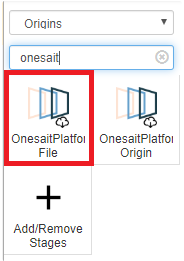
Ever since version 2.1.0-gradius, these files are also accessible from the Dataflow, because a new component of type «Origin: OnesaitPlatform File» has been incorporated.
To use it, just go to the menu option Analytical Tools > Dataflow Management, create a new Pipeline and add this component to the palette.
This component has the following configuration:
Conection
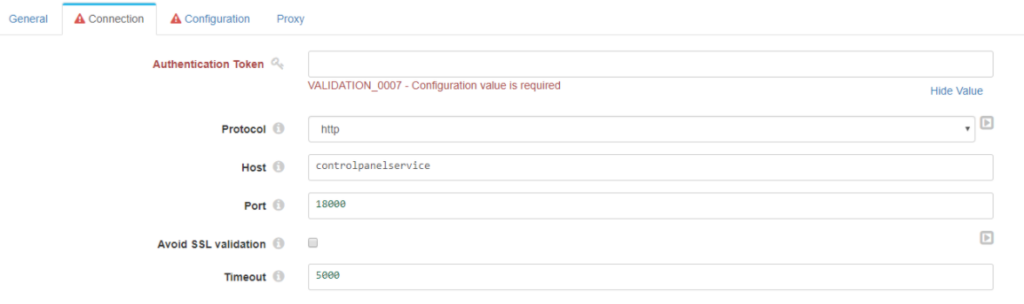
- Authorization: user’s OAuth token. The user must have permissions on the file to be queried.
- Protocol: whether we are going to work using HTTP or HTTPS.
- Host: by default it will be «controlpanelservice», because the DataFlow will connect internally with the Control Panel using its service name. If we want the component to attack another Control Panel, we only need to write its IP here.
- Post: port for connection to the Control Panel. By default it is 18000.
Configuration
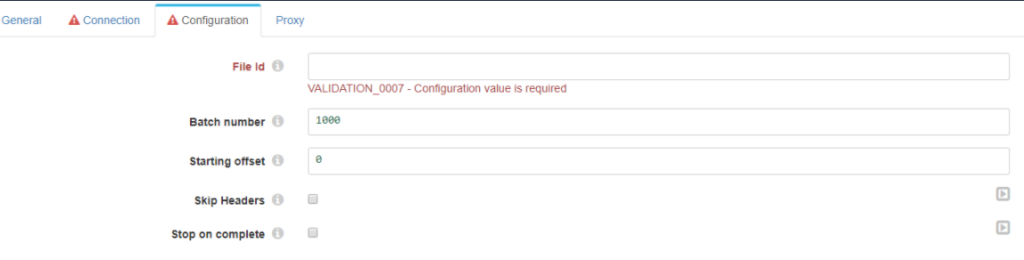
- File Id: id of the file to be read.
- Batch number: number of lines to be read at a single time.
- Starting offset: line where it will start reading the file.
- Skip Headers: whether or not to return the result with the headers.
- Stop on complete: stop the pipeline once you have finished reading the document.
Result
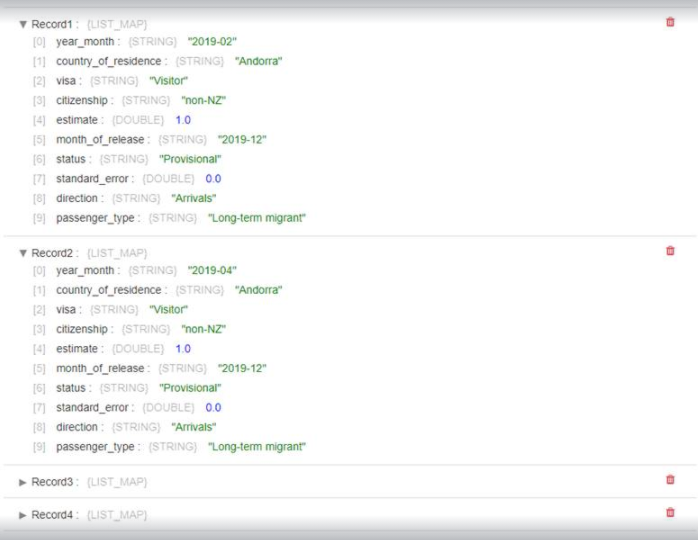
Next is the result of running a pipeline that reads the file, including the headers:
In the following link, you can see a video tutorial of how this tool works and how to read files from a DataFlow Pipeline.
We hope you find this tool useful and if you have any concern or suggestion, please feel free to leave us a comment!


