
Guía Spring Cloud Streams para EDA
Spring Cloud Streams es un proyecto construido sobre Spring Boot y Spring Integration que nos ayudará a construir aplicaciones bajo patrones dirigidos por eventos. Gracias a que esta desarrollado sobre estos proyectos su uso es muy sencillo para los desarrolladores, ya que requerirá de mínimas configuraciones y del uso de anotaciones de Spring.
Como gestor de eventos, nos permite hacer uso de la mayoría de gestores de mensajes existentes en la actualidad como son: Apache Kafka, RabitMQ y Amazon Kinesis entre otros.
Para mas información visitar la documentación oficial.
Cómo usarlo
Para poder usar la librería, lo primero que deberemos es importar la dependencia maven en el pom de nuestro proyecto.
Dependencia spring-cloud-streams
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka</artifactId>
</dependency> Esta librería se deberá importar tanto en el proyecto emisor como receptor.
En el caso del emisor deberemos configurar los bindings (o canales de eventos) en el que mandaremos los eventos generados. Para ello, lo podremos hacer modificando el fichero application.yml de nuestro proyecto.
Configuración YAML Publisher
spring:
cloud:
stream:
bindings:
users: # Nombre del binding
destination: users_event # Canal de salida
binder: local_kafka # Broker binder deseado
kafka: # Datos de conexion de los brokers
binder:
brokers:
- localhost:19092 # Brokers de kafka
binders: # Lista de brokers disponibles
local_kafka: # Nombre del broker
type: kafka # Tipo de broker Para poder enviar eventos deberemos crear una interfaz encargada de vincular estos datos de configuración del YAML. Para ello crearemos la siguiente interfaz.
Interfaz Binding Publisher
public interface UsersChannel {
@Output("users") // Nombre del binding
MessageChannel output();
} Una vez creada la interfaz podremos crear un servicio que envíe los eventos.
Clase publisher
@Slf4j
@Component
@EnableBinding(UsersChannel.class) // Etiqueta para poder seleccionar el binding a usar
@RequiredArgsConstructor(onConstructor = @__(@Autowired))
public class UsersPublisher {
private final UsersChannel source;
public void newUser(UserKafka user) {
log.info("Sending newUser: {}", user);
source.output().send(MessageBuilder.withPayload(user).setHeader("operation", "new").build());
log.info("Message sent successfully");
}
public void deleteUser(UserKafka user) {
log.info("Sending deleteUser: {}", user);
source.output().send(MessageBuilder.withPayload(user).setHeader("operation", "delete").build());
log.info("Message sent successfully");
}
} Podemos agregar headers que se agregarán automáticamente al evento en Kafka para luego poder filtrar en el subscriptor como veremos a continuación.
Con estos sencillos pasos ya tenemos creado el micro-servicio emisor. Para poder crear el subscriptor deberemos seguir unos pasos similares. Primero deberemos modificar el YAML.
Configuración YAML Subscriber
spring:
cloud:
stream:
bindings:
users: # Nombre del binding
destination: users_event # Canal de entrada
group: homeQueue_users # GroupID de Kafka
binder: local_kafka # Broker binder deseado
binders: # Lista de brokers disponibles
local_kafka: # Nombre del broker
type: kafka # Tipo de broker
kafka:
binder:
brokers:
- localhost:19092 # Brokers de kafka A continuación, al igual que en el publisher, deberemos crear una interfaz para vincular los datos del YAML.
Interfaz Binding Subscriber
interface InputBinding {
@Input(value = "users")
SubscribableChannel channel();
} Por último, deberemos crear una clase que escuche todos los eventos generados por el publisher. Como tenemos dos eventos para crear y borrar y hemos puesto las cabeceras, podemos crear dos métodos que escuchen y filtren los eventos.
Clase Subscriber
@Slf4j
@EnableBinding(InputBinding.class)
public class UsersSubscriber {
@Autowired
private UsersRepository repository;
@StreamListener(target = "users", condition = "headers['operation']=='new'")
public void processUser(UserKafka user) {
log.info("User NEW recived: {}", user);
Optional<UserDocument> optUser = repository.findByUserId(user.getId());
if (!optUser.isPresent()) {
UserDocument doc = new UserDocument(user.getId());
repository.insert(doc);
}
}
@StreamListener(target = "users", condition = "headers['operation']=='delete'")
public void processDeleteUser(UserKafka data) {
log.info("User DELETE recived: {}", data);
Optional<UserDocument> optUser = repository.findByUserId(data.getId());
if (optUser.isPresent()) {
repository.delete(optUser.get());
}
}
} De esta manera, en el primer metodo leeremos los eventos que tengan la cabecera «operations = new» y en el segundo método sólo llegarán aquellas que tengan la cabecera «operations = delete».
Ejemplo
Vamos a analizar un ejemplo aplicando el patrón EDA para tres micro-servicios, que obtendrán diferentes eventos en sus canales respectivos.
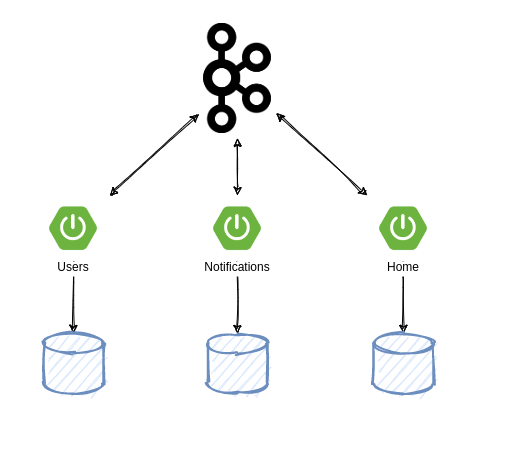
Como podemos ver, cada uno de los micro-servicios tendrá una base de datos diferente y compartirán datos a través de un broker de mensajería, en este caso, Kafka.
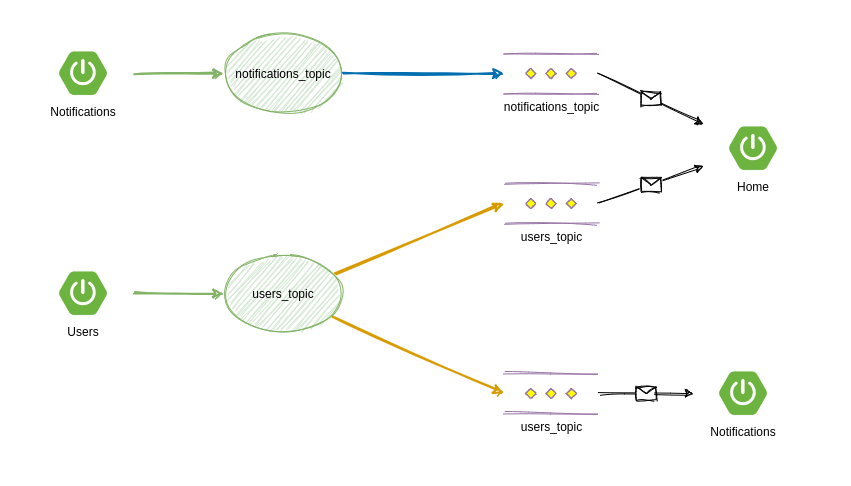
Cuando el micro-servicio Users reciba una petición por parte del usuario para crear uno nuevo o eliminarlo, se mandarán eventos a otros dos micro-servicios Notifications y Home por lo que cuando reciban estos eventos, crearán o eliminarán cada uno de su base de datos el usuario que se da de alta. Por ese motivo, existirá un canal de comunicación en el que enviaremos todos los eventos de usuarios.
Por otro lado, el micro-servicio Notifications tendrá un Endpoint en el que cuando un usuario cree una nueva notificación, se enviará automáticamente por otro canal un evento que en este caso sólo recibirá el micro-servicio Home, que servirá para poder listar todas las notificaciones creadas.
Instrucciones
- Clonar el proyecto de GitLab:
git clone https://gitlab.devops.onesait.com/onesait/onesait-architecture/examples/eda/spring-cloud-streams 2. Acceder a la carpeta «sources» del proyecto y levantar los contendores Docker necesarios. Para ello, se ofrece un Docker Compose:
cd spring-cloud-streams/sources
docker-compose up -d Con esto levantaremos tres contenedores Docker: por un lado tenemos MongoDB que usaran los servicios como base de datos y por otro lado tenemos Kafka y Zookeper, que será utilizados como gestor de eventos. Es importante no modificar ni puertos ni credenciales de estas contendores, en caso de hacerlo habría que entrar a los application.yml y modificar las configuraciones.
3. Arrancar cada uno de los servicios: «home», «notifications» y «user». Esto se puede hacer desde el sts o desde la consola:
cd home
mvn spring-boot:run
cd user
mvn spring-boot:run
cd notifications
mvn spring-boot:run Con esto ya tendríamos levantado todo lo necesario.
4. Acceder al swagger del servicio de user: http://localhost:8090/users/swagger-ui.html y crear un usuario; se devolverá el id de usuario.
5. Acceder al swagger del servicio de notifications: http://localhost:8092/notifications/swagger-ui.html y crear una notificación con el id de usuario obtenido.
6. Acceder al swagger del servicio de home: http://localhost:8091/home/swagger-ui.html , donde podremos listar tanto los usuarios como las notificaciones que se han creado en la base de datos de «home», y que han llegado mediante eventos de Kafka.
Imagen de cabecera: foto de Liana Mikah en Unsplash


