
Running a Spark application with StreamSets
When processing large amounts of data in a short time, Spark becomes an interesting platform to perform all this processing, as it allows operations on a large volume of data in clusters in a fast and fault-tolerant way.
StreamSets offers a processor called Spark Evaluator that allows customised processing within a pipeline based on a Spark application. To do this, it is necessary to create a Spark application using Java or Scala language, and encapsulate it in a JAR. The following example is taken from the StreamSets blog, and shows the steps to follow to run your application. To download the input data for the example, you can access the tutorials provided by StreamSets.
First of all, you have to develop the Spark application, in which you have to include the «transform» method. This method is called for each batch of records that the pipeline processes and it is where the data is processed according to the custom code. The Spark Evaluator processor transforms the processed data into a resilient distributed dataset (RDD). In addition, there are two other methods: one for making connections to external systems or reading configuration data or data from external systems, «init», which is called once at startup; and «destroy», which is called when the pipeline is stopped and serves to close connections that have been made in the «init» to external systems.
In this example, the «transform» method reads a set of data in which a credit card number is reported. Depending on the number at the beginning of the field, it will determine the type of card it is, performing error checking if the field is empty. The configuration relating the number to the card type has been added in the Spark Evaluator itself:
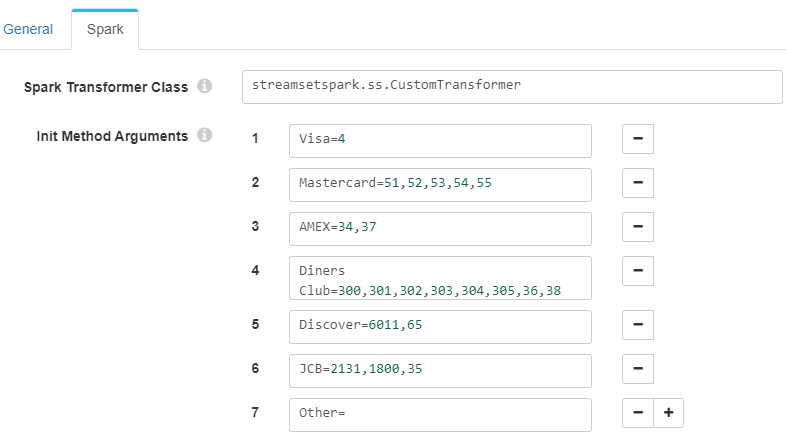
To read this information, you need to include the «init» method, which saves the information in the «ccTypes» map to be used later in the data processing:

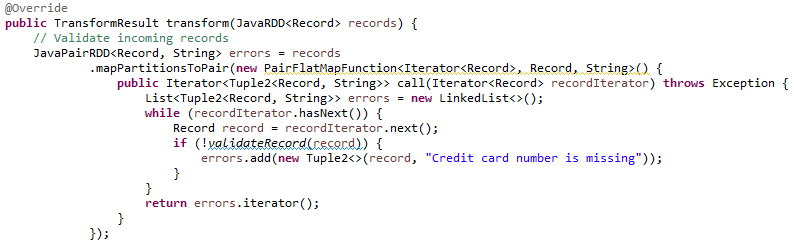
The «transform» method first performs data validation, returning as an error those entries whose card number value is not reported or is empty.
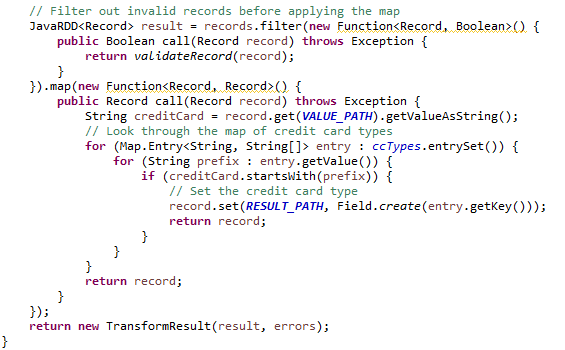
Then, to generate the response which adds the card type field to the received data set, a filter is performed to avoid processing data classified as erroneous, and with the information extracted from the Spark Evaluator configuration, the new field is added, returning the «TransformResult» with the response RDD and errors:
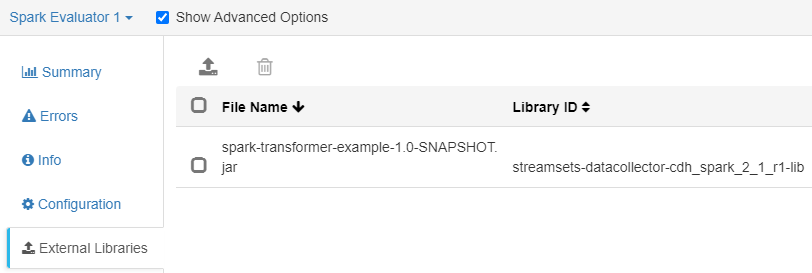
In order to use the application in StreamSets, it has to be packaged in a JAR, compiling it with the same version of the library used for the Spark Evaluator processor. This JAR will be added as an external library in the StreamSets component:
To summarise, the Spark Evaluator component is now configured as follows:
- Spark Transformer Class: streamsetspark.ss.CustomTransformer (corresponds to the name of the class containing the «transform» method).
- Init Method Arguments: with the configuration that classifies each type of card, as shown in the first image (Spark Evaluator configuration).
- Parallelism (Standalone Mode Only): 4.
- Application Name (Standalone Mode Only): SDC Spark App.
The flow that has been represented starts with the reading of the csv file mentioned above, a filter that identifies which operations have been performed with a card and which have not, the execution of the Spark code, and the insertion of the new information in a local file.
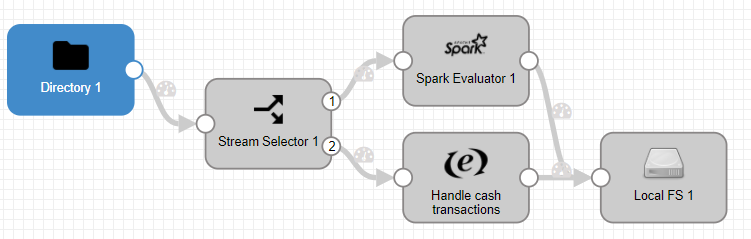
- Directory 1: in the Files tab, select the directory where the file is located, and its name.
- Stream Selector 1: in the Conditions tab, add
${record:value("/payment_type")=="CRD"}to filter those data that have been made by credit card. - Spark Evaluator 1: has the configuration discussed above, with the Spark application’s JAR installed as an external library.
- Handle cash transactions: simply add the «credit_card_type» field with value «n/a» so that all data saved in the final file have this field reported.
- Local FS 1: saves the file to the specified path in JSON format.
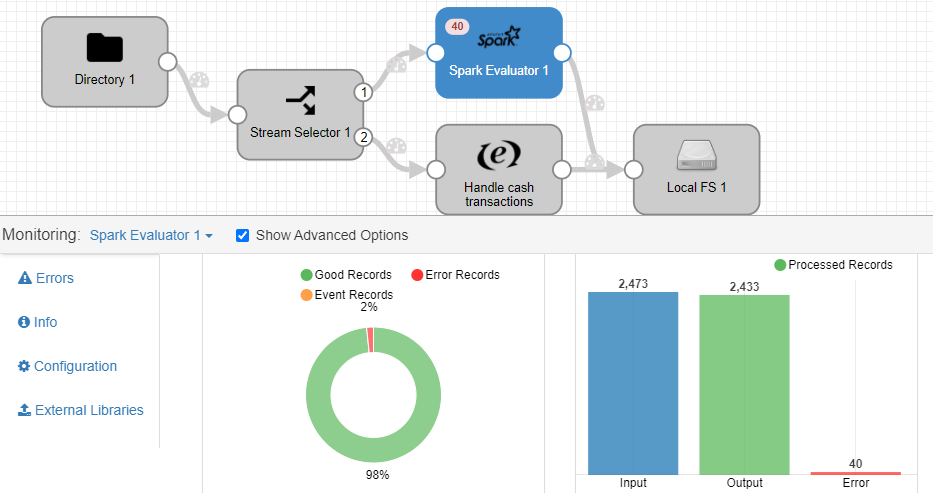
Once the pipeline is executed, you can see that the Spark Evaluator component receives 2473 reports of credit card payments, of which 40 have failed because the «credit_card» field was not reported:
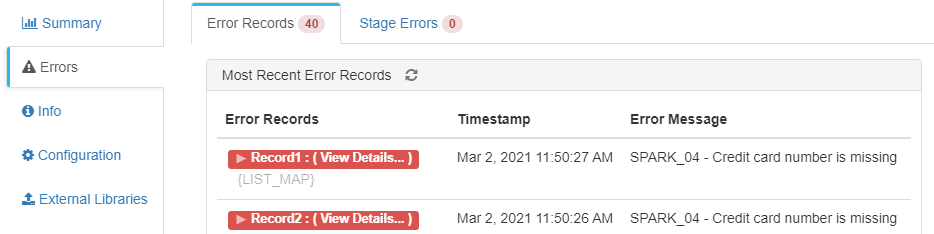
In this way, the final file will have the data processed by Spark Evaluator without errors, plus those filtered for not being of type «credit card» with the card type classification added with the Spark application.


