
New Process Verifier Asset
For release 5.3.0-Ultimate we have incorporated a new asset to verify processes that will allow us to check the result of the execution of processes developed on Onesait Platform, Minsait’s platform, allowing us to verify the correct loading of data.
In addition to this, the process verifier allows us to add rules to these processes to achieve greater control of the data inserted. For example, there is a rule that checks the correct integrity of the loaded data (“dataExist“) or one that allows us to control the number of loaded records (“volumetry“).
Process Verifier concepts
In the following diagram we can see the flow that the process verifier follows:
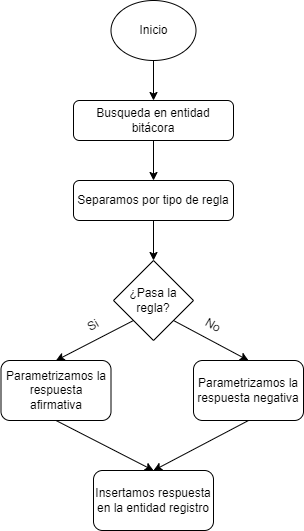
Logbook entity
This Entity contains information on the processes to be verified.
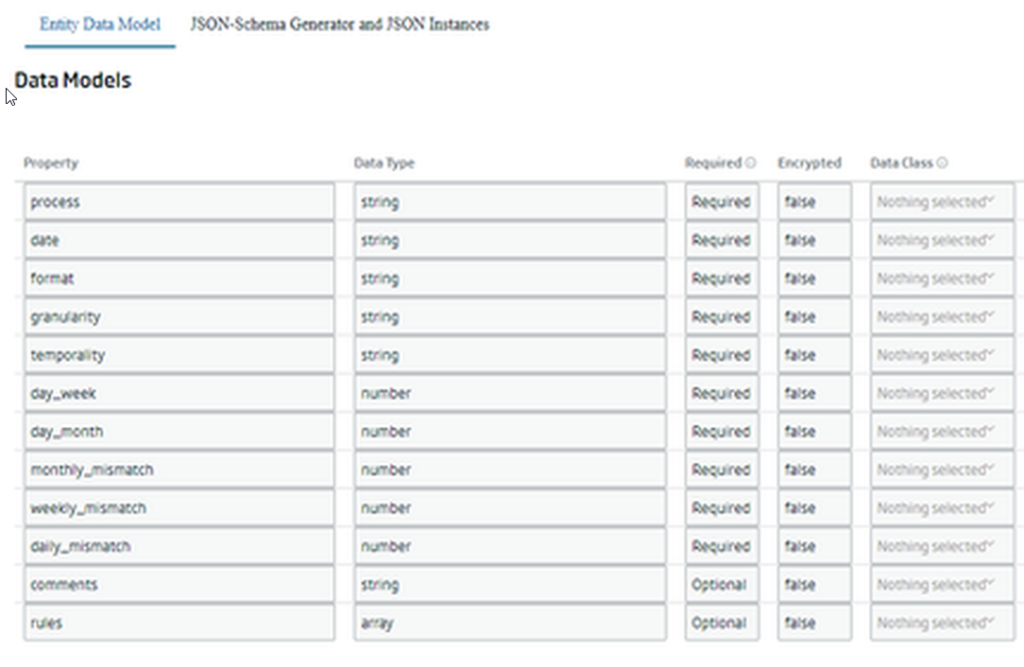
This Entity stores the information about the processes to be launched as well as the rules to be applied. Its attributes are:
- process: the name of the process shall be recorded in this field.
- date: refers to the process field that stores the date of the data insertion.
- granularity: frequency of the inserted data.
- temporality: frequency with which data is inserted.
- day_week: day of the week on which the data load is carried out (Monday = 1, Sunday = 7).
- day_month: day of the month on which the data load is performed.
- monthly_mismatch: difference of months between the data load and the information it references.
- weekly_mismatch: difference of weeks between the data load and the information it is referencing.
- daily_mismatch: daily difference between the data load and the information it refers to.
- comments: comments that we can add about the process for more information.
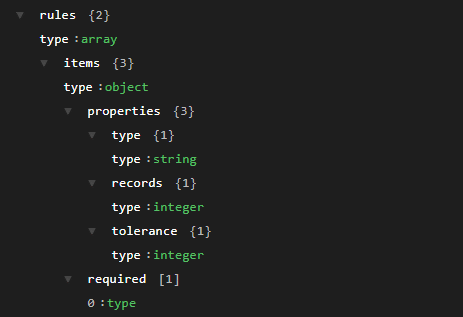
- rules: field that contains the definition of the rules that apply to each process. This field is divided as follows:
- type: type of rule that applies to this process.
- records: expected records for this process (only applies to “volumetric” rules).
- tolerance: tolerance of expected records (only applies in “volumetric” rule).
Registration Entity
This other Entity stores the execution log of the processes, and whether they have passed the various rules defined for them:

The attributes in this case are:
- process: name of the process.
- date: date on which the verification was carried out.
- type: type of rule that has been verified.
- detail: information in case of error in the verification.
- status: record of the status of the process for a certain rule (“Passed” or “Failed”).
How is the Process Verifier used?
Main flow
To use the process checker, we will first create a flow in the FlowEngine like this one:
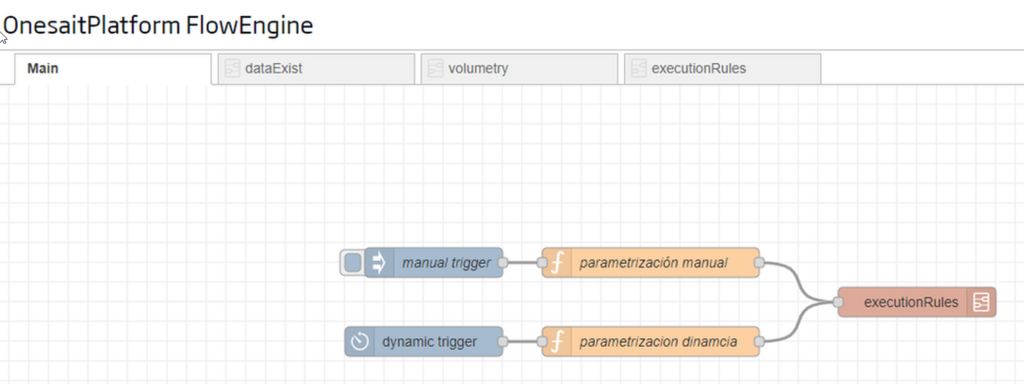
In the main flow (“Main“) we will have a manual “trigger” that will allow us to launch the process on request. The image shows how to execute it on a specific date:
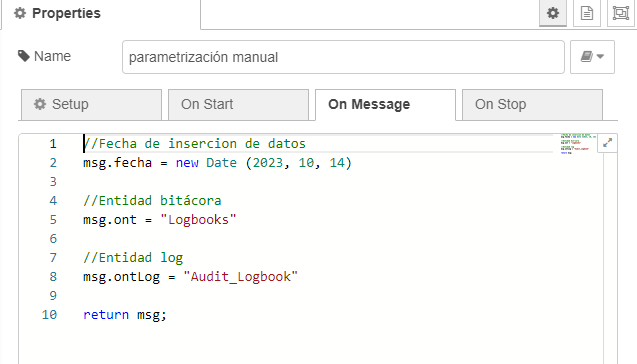
In addition, the process can be dynamically triggered by the “trigger dynamic” node once a day.
In the parameterisation nodes, we define the following variables:
- fecha: Today’s date.
- ont: Log entity from which we will obtain the information.
- ontLog: Log entity where we will insert the information.
Rule Execution Flow
In this flow, all the necessary configuration is defined before verifying the different rules of each process:
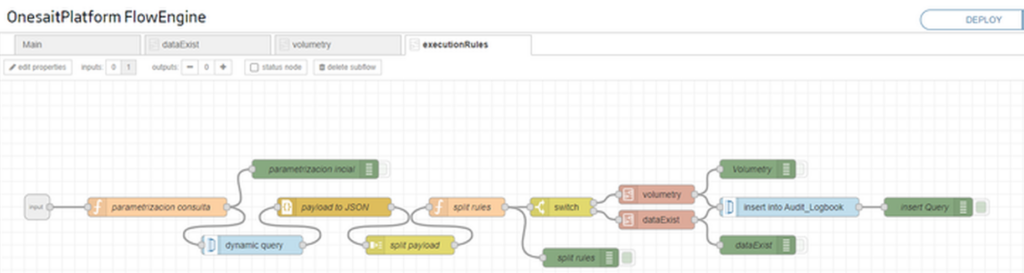
In the “query parameterisation” node, the necessary “query” is formed to obtain the information from each process and store it in the variable “msg.payload“.
With the “payload to JSON” node, the output of the query is simply transformed into a JSON, while the “split payload” node separates this JSON into different objects.
After this, the splitting of rules must be performed; this is done in the “split rules” node, where we create a new variable (“msg.rule“) that we will use in the next “switch” node to split the objects and apply the rule that applies to it.
After going through the flow of the rule to be applied, we will perform the insertion of the result in the register entity.
Rules
After separating by rules, we enter the definition of each of them in their respective flows. We can add as many rules as we wish. Initially, these two are included:
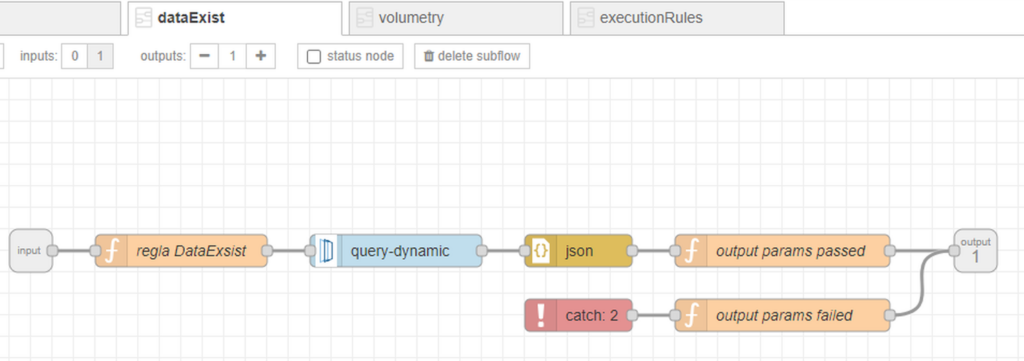
Rule dataExist
In this rule we check the existence of data for the granularity specified in the process. If there is no data, the rule will be given as “Failed” and a message explaining the reason for the error will be reflected in the “detail” field.
Otherwise, the rule shall be given as “Passed“.
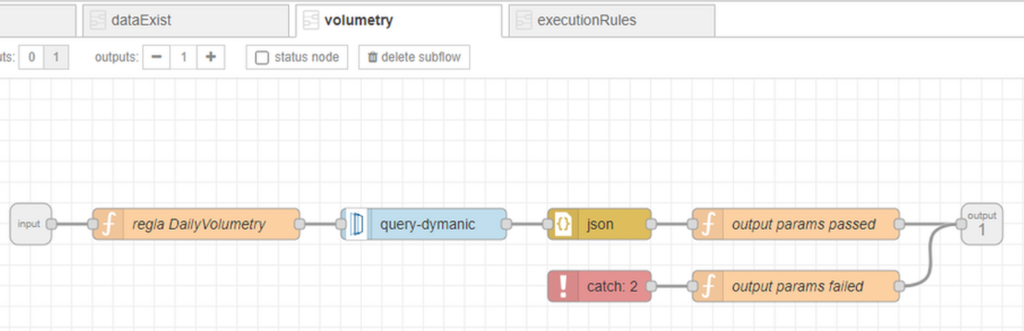
Rule Volumetry
This rule is used to check the volume of data recorded for a specific process. The expected number of records and the tolerance (percentage number) is given within the same rule.
In case of receiving a number of records within the expected number, the rule will be given as “Passed“, but otherwise it will be given as “Failed” and a message explaining the failure will be added in the “detail” field.
Example of Execution
Next, we are going to see an example of the execution of this verifier for these processes.
In order not to have to build the whole flow from scratch, we have prepared a ZIP file with the asset code to import it into the Platform.
How do we import it? Simply download the file and go to the “Bundle Load” section under “Version Control” in the Platform.
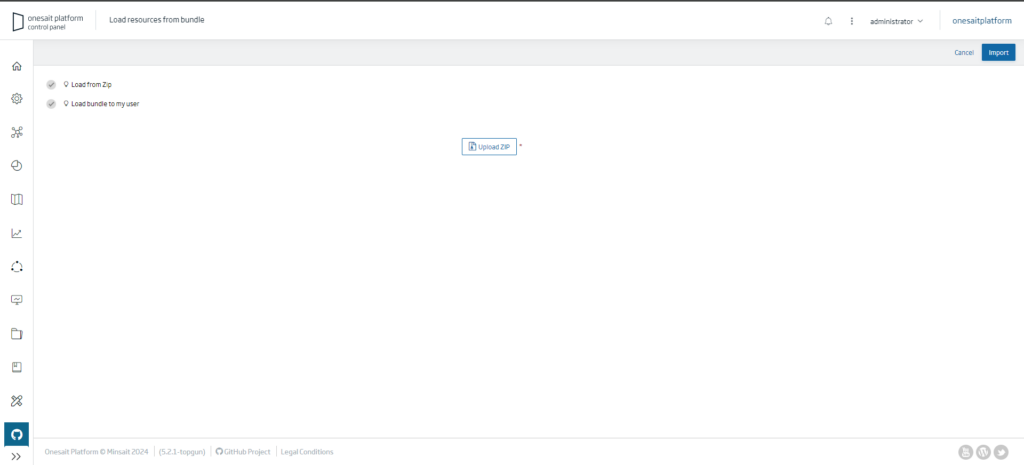
Once on this page, click on the “Upload ZIP” button and then on “Import“.
Definition Process 1
- process: Process1
- date: datetime
- fromat: yyyy/mm/dd
- granularity: daily
- temporality: weekly
- day_week: 0
- day_month: 0
- monthly_mismatch: 0
- weekly_mismatch: 0
- daily_mismatch: 0
- rules:
- Item 1
- type: dataExist
- Item 2
- type: volumetry
- records: 336
- tolerance: 20
- Item 1
Definition Process 2
- process: Process2
- date: datetime
- fromat: yyyy/mm/dd
- granularity: daily
- temporality: weekly
- day_week: 0
- day_month: 0
- monthly_mismatch: 0
- weekly_mismatch: 0
- daily_mismatch: 0
- rules:
- Item 1
- type: dataExist
- Item 2
- type: volumetry
- records: 1
- tolerance: 20
- Item 1
For this case there will be no data from process 1 on 14/12/2023. In addition, the total number of inserted records of process 2 is 66.
After launching our process checker, the result in the record entity will be as follows:

Header Image: Sigmund at Unsplash.


