The importance of Smart Data Models
As we have already discussed many times, digital transformation is widespread in all businesses and at all levels, not only in the private sector but also in public administrations and governments around the world. This digitalisation has been accompanied by the generation of an enormous amount of data, which needs to be stored for later exploitation and reuse.
When it comes to generating data structures in which to store all this information, as is the case with Onesait Platform Entities, having an information model that follows a globally adopted structure is key to being able to create and participate in a digital market of intelligent, replicable and, above all, interoperable solutions. And this is where “Smart Data Models” come into play.
What are they?
Smart Data Models are similar to traditional data models, which represent the elements of a dataset and their relationships and connections to each other, but provide a technical basis to support a digital marketplace of interoperable and replicable smart solutions across multiple sectors, so that the availability of data in specific domains is homogenised.
The Smart Data Models programme
The Smart Data Models (SDM) programme is a collaborative programme that seeks to support the adoption of common and compatible data models that underpin a digital marketplace of interoperable and replicable smart solutions.
This programme is led by the FIWARE Foundation, the IUDX, TM Forum and OASC, organisations that seek to achieve common models, as we have said, for use in the digital markets for smart solutions, such as in the case of Smart Cities, energy, environment, robotics, logistics, healthcare, smart destinations, etc.
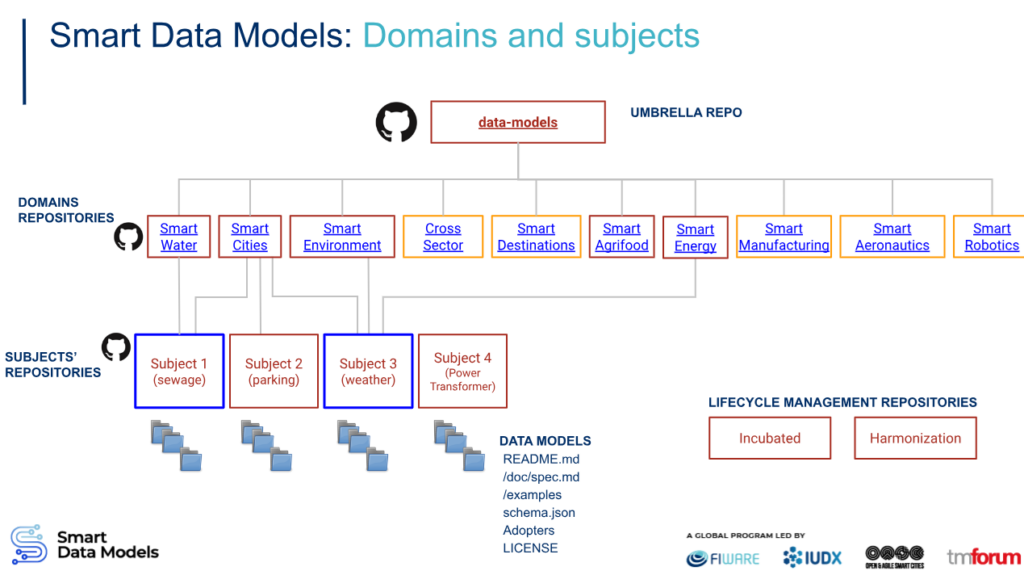
The fundamental objective of SDM is to enable organisations to evolve their vision of data exchange towards a sharing that supports both the so-called “data economy” and data spaces. This data economy is nothing more than the set of activities and initiatives whose business model is based on the discovery and exploitation of data, for the identification of opportunities that generate products and services.
Basis
The idea is that the models will be developed following the principles of agile standardisation, which will allow specifications to be created in less than a week (data-model-in-a-week) as long as examples of use and definitions are available. The data models will be incorporated from two different sources: the mapping of open and already adopted standards (standards that allow free use, free customisation and free exchange of customisations) and real use cases.
For this, these seven agile standardisation practices are followed:
- Not only standardise, but be agile and standardise.
- Don’t reinvent the wheel.
- Standardise real cases.
- Be open.
- Don’t be too specific.
- Focus on something flat, not in depth.
- Sustainability is the key.
Let’s look at each of these practices in a little more detail.
1.- Not only standardise, but be agile and standardise
Agile standardisation is distinguished by its speed, measuring progress in days or weeks rather than months or years. This involves automating processes and minimising human intervention to avoid errors and delays.

2.- Don’t reinvent the wheel
Build on what already exists and is in common use in the market under open licences. Instead of creating new theoretical standards, focus on solutions that solve real problems and are needed.

3.- Standardise real cases
Building on use cases that have already proven to be useful in the market ensures that standards are practical and applicable.

4.- Be open
The results of agile standardisation should be made available under open licences that allow them to be freely reused, modified and shared.

5.- Don’t be too specific
Although data models should solve real problems, they should be general enough to cover multiple use cases. One should therefore avoid making too many attributes mandatory in order not to complicate the models.

6.- Focus on something flat, not in depth
Models should be as independent as possible. It is preferable to access data from a single place, avoiding excessive references between models that complicate their use.

7.- Sustainability is the key
Agile standardisation must consider continuity and continuous improvement of models, adapting them as the market changes. It is not a one-time project, but an ongoing effort.

A practical example of Smart Data Models: Smart Cities
The reference architecture and data models use the FIWARE NGSI API and TM Forum’s open APIs for interoperability and scalability of smart solutions.
The FIWARE Context Broker technology, which implements the FIWARE NGSI APIs (NGSI v2 and NGSI-LD), provides the basis for breaking down information silos in organisations aspiring to become smart. This will enable a real-time (or very close to real-time) view and provide the basis for the development of governance systems at the global organisational level. Examples of such organisations are cities, factories, hospitals, airports, farms, etc.
Combined with TM Forum’s open APIs, data publishing platforms can help organisations harness the potential of open data in real time, facilitating the development of innovative solutions by third parties. In addition, organisations can evolve their existing data sharing policies towards a vision that, shared with other organisations, supports a Data Economy. In this way, the proposed reference architecture is ready to address the current needs of organisations, while preparing for future requirements.

For smart cities, the following data structures are currently available:
- dataModel.Building
- dataModel.GBFS
- dataModel.OSLO
- dataModel.Parking
- dataModel.ParksAndGardens
- dataModel.PointOfInterest
- dataModel.Ports
- dataModel.S4BLDG
- dataModel.Streetlighting
- dataModel.Transportation
- dataModel.UrbanMobility
- dataModel.WasteManagement
- dataModel.Weather
- dataModel.WifiNetwork
Within each of them, there are different types of entities available. Thus, in the case of buildings (first option in the list), there are four types:
- Building: with the corresponding information of a building.
- BuildingOperation: in this case, with the operation information of the building.
- BuildingType: this entity type contains a harmonised description of a generic building type.
- VibrationsObserved: to contain the vibration information observed at a specific location.
If we focus on the generic example, that of “BuildingType“, we will see that its specifications are, in JSON format:
{
"id": "urn:ngsi-ld:BuildingType:57b912ab-eb47-4cd5-bc9d-73abece1f1b3",
"type": "BuildingType",
"source": {
"type": "Text",
"value": "https://source.example.com"
},
"dataProvider": {
"type": "Text",
"value": "https://provider.example.com"
},
"name": {
"type": "Text",
"value": "House"
},
"description": {
"type": "Text",
"value": "Standard building type definition for a domestic house"
},
"root": {
"type": "Boolean",
"value": false
},
"buildingTypeParent": {
"type": "Text",
"value": "urn:ngsi-ld:BuildingType:4146335f-839f-4ff9-a575-6b4e6232b734"
},
"buildingTypeChildren": {
"type": "StructuredValue",
"value": [
"urn:ngsi-ld:BuildingType:e4291e84-58f8-11e8-84c3-77e4f1f8c4f1",
"urn:ngsi-ld:BuildingType:a71c7a08-58f9-11e8-a41e-4bcb7249360e",
"urn:ngsi-ld:BuildingType:afac9bbc-58f9-11e8-b587-1f0d57b81bb4"
]
}
} In this way, we have a template that allows us to define what a generic building is with all the most important information, which, as it is standardised, can be used in APIs and other consultation and consumption services. If both the client and the provider work with the same template, the exchange of information will hardly require any effort.
Data models in Onesait Platform
In the Platform, the entity of the data model is simply called Entity, although we initially called it “Ontology”. These Entities will allow modelling from simple concepts such as a measure or a record, to complex concepts such as an organisation. These Entities are defined in the JSON + JSON-Schema format.
Origin of Ontologies
The concept of Ontology – now Entities, we recall – comes from the European R&D project SOFIA, from which the Sofia2 platform originated, which used RDF/OWL Ontologies as data models, in accordance with the principles of the semantic web.
When in 2013 Indra considered evolving SOFIA to create an enterprise platform (Sofia2), which could be used in productive and complex projects, an analysis and empirical tests were carried out on Sofia2, and it was concluded that the technology underlying the traditional ontologies modelled in OWL did not scale in accordance with the needs of IoT and Big Data projects.
After considering various options, JSON + JSON Schema was considered to be the best current and future proposition.
A bit of history: Sofia2’s data model
To better understand how data models work in Onesait Platform, it is interesting to take a look back and analyse the data model that previously existed in the Sofia2 platform, where although the key concept of the data model was the Ontology, there were other important concepts to consider, such as the “Template” and the “Ontology Instance“.
Let’s see what they are:
| Data Model or Template | Ontology | Ontology Instance | |
|---|---|---|---|
| Represents | Template, either created by an Administrator, or created according to a particular standard (such as FIWARE Data Model), that allows Ontologies to be created. | Entity representing a concept on which the Platform works. | It is a concrete record of the entity that defines the Ontology. |
| Example | Template defining the environmental quality attributes, according to the FIWARE Data Model. | – Environmental quality (obtained from a device). – Weather forecast (obtained by an algorithm). | – Environmental quality obtained at a specific time at a specific point. – Forecast for a specific region and month. |
| Formats | JSON-Schema | JSON-Schema | JSON |
| Where are? | It is not stored, it is a definition. | Independent of the chosen persistence engine: in a relational model they represent a table, in a document-type NoSQL DB they represent a collection of documents, etc. | Independent of the chosen persistence engine: in a relational model they represent a record, in a document-type NoSQL DB they represent a specific document, etc. |
Data models in the Onesait Platform Control Panel
Our current data model is a natural evolution of the Sofia2 model, in which we retain concepts such as the template or instances. In this case, the concept of the data model represents a template on which the Entities can then be created.
This is why the creation of templates is restricted to those users who have an “Administrator” role.
To visualise the different data models available, from the Control Panel of the Platform, navigate to the menu Administration > Data Models Management:
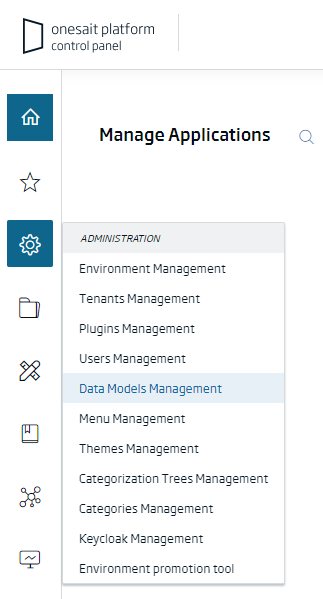
We will then be shown a list of existing data templates, where we can see their name, owner, template type, categorisation tags and creation and edition dates.
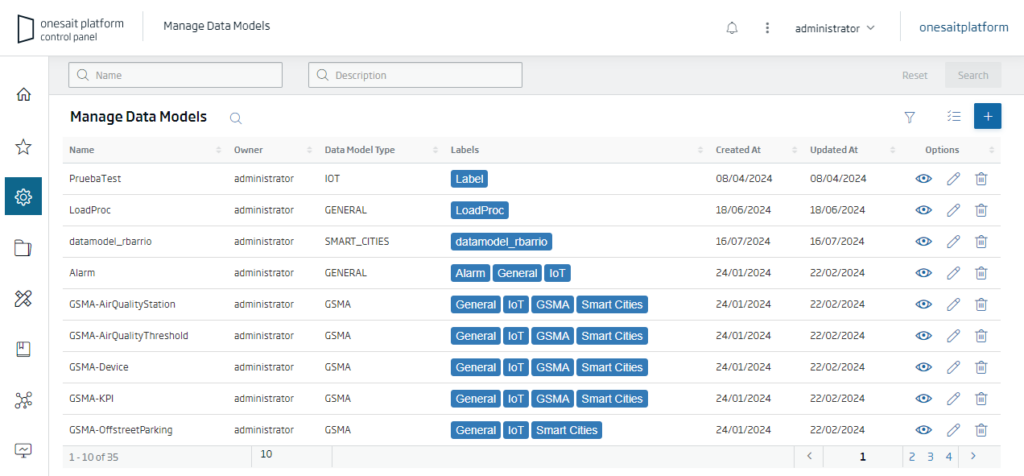
To analyse one of the data model templates, simply click on the “Show” button (eye icon) on the right hand side of each template.

The general information of the data model template as well as the JSON schema will then be displayed:
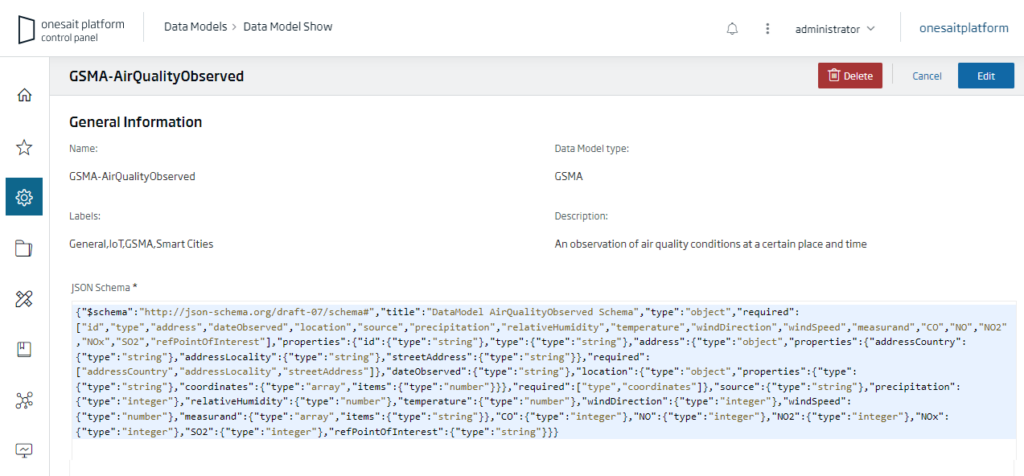
Entities and data models
Entities and data models
The Entities are the key concept of the data model, as well as of the complete operation of the Platform, since the rest of the processes are triggered on them, such as, for example:
- Rules: which are applied upon the arrival of an Entity instance (or planned), and allow access to the attributes of the Entities in order to act on the basis of this.
- Dashboards: dashboards are built, either representing in real time the instances arriving at the Platform, or through a query made on these (DataSources, API REST, etc.).
- Analytics: Machine Learning models are typically performed on the Entities stored in the Platform’s Big Data infrastructure (BDH).
Entities can be created by users with “Developer” or “Analyst” roles, as well as “Administrator” roles. When creating these Entities, we have several mechanisms that will facilitate our work, as we explain in this article of the Developer Portal.
Entity Instances
As mentioned above, an Entity instance represents a specific time and position within an Entity.
The Platform offers several tools to access the instances, being the Query Tool the most used by developers, since it allows through a wizard to quickly generate queries on the Entities, both in SQL and native, obtaining the result of the query in JSON format, which we can download in our local both in JSON and CSV format.
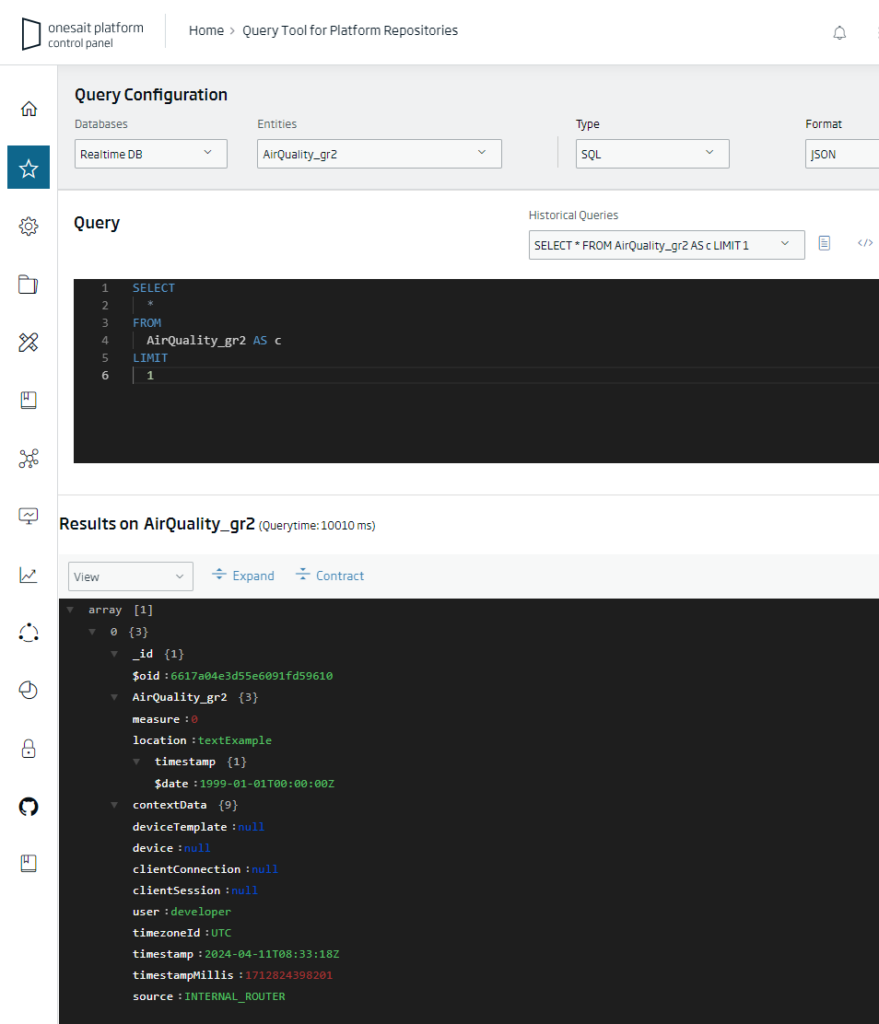
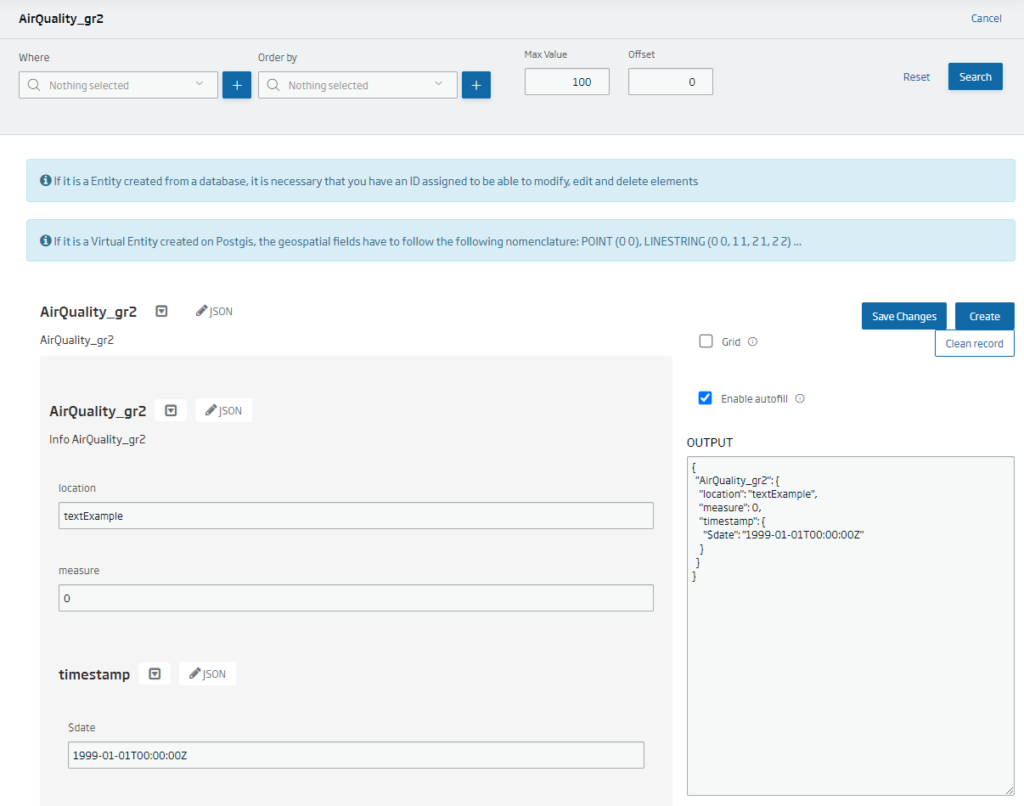
Another option we have to view the content of an Entity is through the Entity CRUD tools, where we can view the existing records:
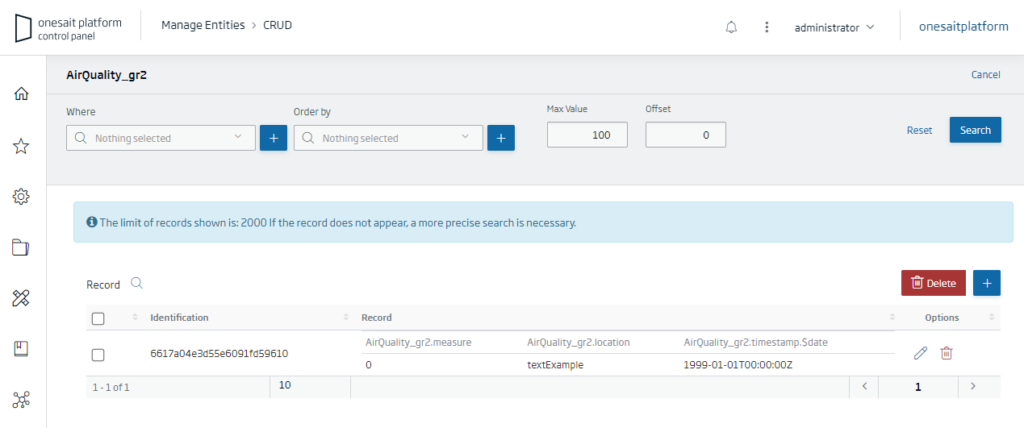
From the Entity CRUD we will be able to edit the records in a simple way. This is not practical when you have thousands of records, but for a quick correction it is very useful.
In conclusion
Given the importance of data models, we at the Platform believe that the Smart Data Model programme is a great initiative that will allow different partners and clients to work under the same data formats, facilitating the exchange of information and working in parallel to be able to exploit the information.
Moreover, the fact that they are open, consensual proposals adopted by a large number of users fits with our mentality of open source, reuse and adaptation to the needs of the market, so we believe and trust that these data models will have an interesting future and will continue to grow the available options.
Header Image: Analytics Vidhya.
More Information: Smart Data Models.